今天在看hive的时候,注意到我们在查数据的时候,我们可能并不知道这个字段是来自哪个文件。
因为文件都是存在HDFS上面的,hive的表只是对HDFS上文件中的数据做一个映射,真的数据是存在在HDFS上面的。
所以hive在设置的时候,设置了三个虚拟列,他会告诉你你这个值是来自于哪一张表当中,告诉你字段的偏移 量这些信息。
1. INPUT__FILE__NAME map任务读入File的全路径
2. BLOCK__OFFSET__INSIDE__FILE 如果是RCFile或者是SequenceFile块压缩格式文件则显示Block file Offset,也就是当前快在文件的第一个字偏移量,如果是TextFile,显示当前行的第一个字节在文件中的偏移量
3. ROW__OFFSET__INSIDE__BLOCK RCFile和SequenceFile显示row number, textfile显示为0
注:若要显示ROW__OFFSET__INSIDE__BLOCK ,必须设置set hive.exec.rowoffset=true;
这里我使用了一个student表,在这个表当中我分别使用了同一文件,然后命名为不同的文件名称。然后将数据插入到表当中(我在本地测试的没在HDFS上面测试)
查询的结果如下:

我这里采用的是textfile所以最后那个数值为0.从这里我们可以看到我们的结果集中的字段是来自于那个文件当中。
当然我们在进行查询的时候可能这么干,当我们的数据当中出现了脏数据的我们可以使用这种方式去定位具体的脏数据在哪里。是很不错的排查方式。
这种方式看起来不怎么好看,我们可以使用beeline的形式启动hive,那样更清楚。启动的命令行如下:
beeline -u jdbc:hive2://localhost:10000
结果如下,他的线框视觉效果很好;
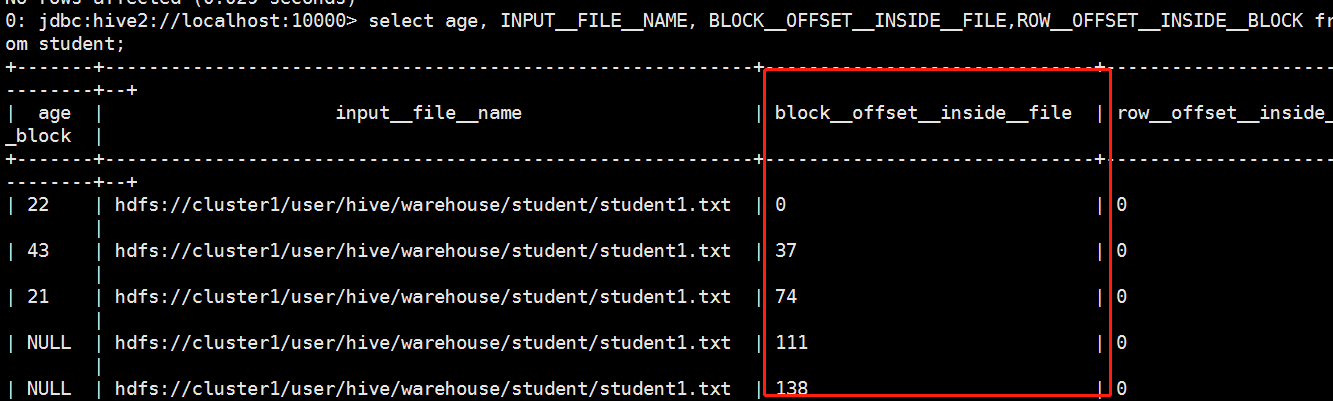
当然这种方式只不只是看着好看,关于beeline是基于线程启动的,我们在操作hive的时候,每启动一个我们都是启动了一个进程,当我们使用beeline启动的时候
这个时候我们启动的是一个线程,这个时候我们只启动了一个进程,对于系统的性能方面有很大的提升。具体的可以自己参考网上的信息学习。