协程
在python3.5以前,写成的实现都是通过生成器的yield from原理实现的, 这样实现的缺点是代码看起来会很乱,于是3.5版本之后python实现了原生的协程,并且引入了async和await两个关键字用于支持协程。于是在用async定义的协程与python的生成器彻底分开。
async def downloader(url): return 'bobby' async def download_url(url): html = await downloader(url) return html if __name__ == '__main__': coro = download_url('http://www/imooc.com') coro.send(None) 输出结果: Traceback (most recent call last): File "D:/MyCode/Cuiqingcai/Flask/test01.py", line 67, in <module> coro.send(None) StopIteration: bobby
可以看到结果中可以将downloader(url)的结果返回。需要注意的是在原生协程里面不能用next()来预激协程。
async def downloader(url): return 'bobby' async def download_url(url): html = await downloader(url) return html if __name__ == '__main__': coro = download_url('http://www/imooc.com') coro.next() 结果: AttributeError: 'coroutine' object has no attribute 'next' sys:1: RuntimeWarning: coroutine 'download_url' was never awaited
原生协程async代码中间是不能在使用yield生成器的,这样就为了更好的将原生协程与生成器严格区分开来。并且await只能和async语句搭配,不能和生成器搭配。因为要调用await需要调用对象实现__await__()这个魔法方法。所以在定义协程时候注意不要混用。但是理解的时候还是可以将原生的协程中 await可以对比生成器的yield from。
asyncio
高并发的核心模块,3.4之后引入,最具野性的模块,web服务器,爬虫都可以胜任。它是一个模块也可以看做一个框架。
协程编码模式的三个要点:
- 事件循环
- 回调(驱动生成器(协程))
- epoll(IO多路复用)
asyncio的简单实用:
这里需要注意的是:同步阻塞的接口不能使用在协程里面。因为协程是单线程的,只要有一个地方阻塞了,那么所有的协程都需要等待阻塞结束之后才可以向下运行,于是在协程函数中等待一定不能用time.sleep() 如果用time.sleep()就失去了协程的意义了(即程序运行的时间将会是每个协程数乘以time.sleep()的时间数。)同时用asyncio.sleep() 之前需要加上 await
import time
async def download_url(url):
print('start get %s' % url)
await asyncio.sleep(2)
print('get %s finished.' % url)
if __name__ == '__main__':
start_time = time.time()
loop = asyncio.get_event_loop()
loop.run_until_complete(download_url('https:www.baidu.com')) # 阻塞等事件完成之后再向下运行。相当于进程线程的join()方法,或者进线程池的wait()
print('一共用时:%s' % (time.time() - start_time))
start get https:www.baidu.com
get https:www.baidu.com finished.
一共用时:2.0011143684387207
一次执行多个任务。(用时和一个任务一样!)下面任务如果换成time.sleep(2)则函数需要至少20秒才能执行完毕。
import asyncio
import time
async def download_url(url):
print('start get %s.' % url)
await asyncio.sleep(2)
print('get %s end' % url)
if __name__ == '__main__':
start_time = time.time()
loop = asyncio.get_event_loop()
url_list = []
for i in range(10):
url_list.append('https:www.baidu.com.index{}'.format(i))
tasks = [download_url(url) for url in url_list]
loop.run_until_complete(asyncio.wait(tasks))
print('用时 %s' %(time.time() - start_time))
...
...
用时 2.0031144618988037
获取协程的返回值:
可以用两种方式先得到一个future对象。然后将该future对象放入loop.run_until_complete()中。(该函数即可以接受future对象也可以接受协程对象)然后future对象跟进程池和线程池中的future对象的方法是一样的。于是可以用.result()方法的到函数的返回结果。
async def download_url(url):
# print('start get %s' % url)
await asyncio.sleep(2)
# print('get %s finished.' % url)
return 'frank is a good man.'
if __name__ == '__main__':
start_time = time.time()
loop = asyncio.get_event_loop()
# get_future = asyncio.ensure_future(download_url('https:www.baidu.com'))
get_task = loop.create_task(download_url('https:www.baidu.com'))
loop.run_until_complete(download_url(get_task))
print('一共用时:%s' % (time.time() - start_time))
print(get_task.result())
一共用时:2.0021142959594727
frank is a good man.
future完成之后的回调函数
设置协程完成之后的回调函数:future对象的.add_done_callback(),注意在调用add_done_callback的时候会默认将future对象传递给回调函数,因此回调函数必须至少接受一个参数,同时add_done_callback必须在run_until_complete()前,(协程函数创建之后调用)因为如果在run_until_complete()之后的话,协程都应结束了。就不会起作用了。
async def download_url(url):
# print('start get %s' % url)
await asyncio.sleep(2)
# print('get %s finished.' % url)
return 'frank is a good man.'
def send_emai(future):
print('网页下载完毕')
print(future.result())
if __name__ == '__main__':
start_time = time.time()
loop = asyncio.get_event_loop()
# get_future = asyncio.ensure_future(download_url('https:www.baidu.com'))
get_task = loop.create_task(download_url('https:www.baidu.com'))
get_task.add_done_callback(send_emai)
loop.run_until_complete(download_url(get_task))
print('一共用时:%s' % (time.time() - start_time))
print(get_task.result())
网页下载完毕
frank is a good man.
一共用时:2.0021145343780518
frank is a good man.
问题来了。tasks.add_done_callback方法只能接受函数名,如果回调的方法也需要参数怎么办?这就需要用到偏函数from functools import partial (偏函数可以将函数包装成为另外一个函数)
import asyncio import time from functools import partial async def get_html(url): print('start get url') await asyncio.sleep(2) return 'bobby' def callback_method(url, future):# 此处因为是future对象即(tasks)调用的,所以有一个默认的参数。同时要注意:回调函数的future只能放到最后,其它的函数实参放前面。 print('download ended %s' % url) if __name__ == '__main__': start_time = time.time() loop = asyncio.get_event_loop() tasks = asyncio.ensure_future(get_html('http://www.baidu.com')) # tasks = loop.create_task(get_html('http://www.baidu.com')) tasks.add_done_callback(partial(callback_method, 'http://www.baidu.com')) # 参数为回调方法 loop.run_until_complete(tasks) print(tasks.result()) start get url download ended http://www.baidu.com bobby
gather 与 wait的区别。都是可以等待程序运行之后往下运行。但是gather比wait更加高级一点
gather可以将任务分组:
import asyncio import time async def get_html(url): print('start get %s' % url) await asyncio.sleep(2) print('end get %s' % url) if __name__ == '__main__': start_time = time.time() loop = asyncio.get_event_loop() group1 = [get_html('http://goup1.com') for i in range(2)] group2 = [get_html('http://group2.com') for i in range(2)] group1 = asyncio.gather(*group1) group2 = asyncio.gather(*group2) loop.run_until_complete(asyncio.gather(group1, group2)) # 上面三行代码也可以合一起loop.run_until_complete(asyncio.gather(*group1, *group2)) 注意此参数前面要加* print(time.time()-start_time) start get http://goup1.com start get http://group2.com start get http://group2.com start get http://goup1.com end get http://goup1.com end get http://group2.com end get http://group2.com end get http://goup1.com 2.0021145343780518
loop.run_forever()协程的任务完成之后不会停止,而是会一直运行。老师吐槽:python中间loop和future的关系有点乱,loop会被放到future中间同时future又可以放到loop中间,造成一个循环。
如何取消future(task)
async def get_html(sleep_time): print('waiting') await asyncio.sleep(sleep_time) print('end after %s S' % sleep_time) if __name__ == '__main__': task1 = get_html(2) task2 = get_html(3) task3 = get_html(4) tasks = [task1, task2, task3] loop = asyncio.get_event_loop() try: loop.run_until_complete(asyncio.wait(tasks)) except KeyboardInterrupt as e: all_tasks = asyncio.Task.all_tasks() for task in all_tasks: print('cancel task') print(task.cancel())# 打印是否取消 是返回Ture,否False loop.stop() loop.run_forever() # 注意此处一定要加上loop.run_forever()不然会报异常 finally: loop.close()
waiting
waiting
waiting
cancel task
True
cancel task
True
cancel task
True
cancel task
True
将此代码进入cmd中运行,然后再中间按ctrl + C键,主动生成一个 KeyboardInterrupt 异常,然后异常被捕捉之后做出处理(即停止协程的运行)
协程的嵌套
import asyncio async def compute(x, y): print('Computer %s + %s...') % (x, y)) await asyncio.sleep(1) return x + y async def print_sum(x, y): result = await computer(x, y) print("%s + %s = %s" % (x, y, result)) loop = asyncio.get_event_loop() loop.run_until_complete(print_sum(1, 2)) loop.close()
代码分析图:
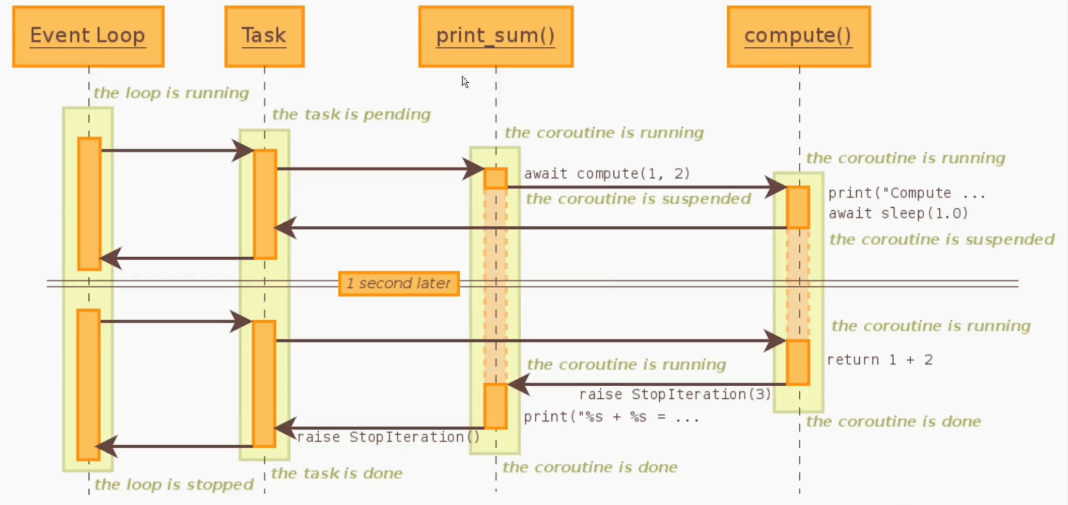
- loop首先会为print_sum()创建一个task
- event_loop()驱动task运行,使task进入(pending状态)
- task去执行print_sum
- print_sum中首先进入子协程的调度(await相当于yiel from)所以转向执行computer,print_sum自身暂停。
- compute中存在await 于是也被迫进入暂停状态,然后可以直接返回给task(await == yield from 而yield from可以在调度方与子生成器之间掠过委托方建立双向通道)
- task返回给event_loop()
- 等待1秒钟之后,task唤醒compute,compute继续执行下一行代码(即return x + y)完成之后compute就是一个done状态,同时抛出一个stopiterationError异常,此异常将激活print_sum()(委托方),并且将异常将被await(对应之前的yield from)捕捉并提取出return的值。
- print_sum()被激活之后执行print然后变成done状态,也会抛出一个stopiterationError异常,然后被task接受并处理了。
asyncio中的其他函数(以下三个为底层函数,多数条件下用得不多)
call_soon()
在协程运行时候,可以传递一些函数去执行,注意是函数不是协程。
import asyncio def callback(sleep_times): print('sleep {} success'.format(sleep_times)) if __name__ =='__main__': loop = asyncio.get_event_loop() loop.call_soon(callback, 2) #第一个参数为调用的函数名,第二个单数为被调用函数的参数 loop.run_forever() sleep 2 success
注意此处调动函数的运行需要用到loop.run_forever()而不是loop.run_until_complete()因为oop.call_soon()只是调用函数而不是loop注册的协程。
同时loop.run_forever()会导致程序一直在运行,不会自动结束。于是需要添加以下方法使程序关闭。
import asyncio def callback(sleep_times): print('sleep {} success'.format(sleep_times)) def stop_loop(loop): loop.stop() if __name__ =='__main__': loop = asyncio.get_event_loop() loop.call_soon(callback, 2) loop.call_soon(stop_loop, loop) loop.run_forever()
call_later()
功能,讲一个callback函数在一个指定的时候运行。
import asyncio def callback(sleep_times): print('sleep {} success'.format(sleep_times)) def stop_loop(loop): loop.stop() if __name__ =='__main__': loop = asyncio.get_event_loop() loop.call_later(2, callback, 2) # 参数含义:第一个参数为延迟时间,延迟越少越先运行。 loop.call_later(1, callback, 1) loop.call_later(3, callback, 3) loop.call_soon(callback, 4) loop.run_forever() sleep 4 success sleep 1 success sleep 2 success sleep 3 success
同时存在call_soon()和call_later()时,call_soon()会在那个call_later()前面调用。
call_at()
也是调用函数在指定时间内调用,但是它的指定时间,是指的loop内的时间,而不是自己传递的时间。可以用loop.time()来获取loop内时间。
import asyncio def callback(sleep_times): print('sleep {} success'.format(sleep_times)) if __name__ =='__main__': loop = asyncio.get_event_loop() now = loop.time() loop.call_at(now+2, callback, 2) # 注意第一个参数是相对于loop系统时间而来的,不是自定义的几秒钟之后运行。 loop.call_at(now+1, callback, 1) loop.call_at(now+3, callback, 3) loop.call_soon(callback, 4) loop.run_forever() sleep 4 success sleep 1 success sleep 2 success sleep 3 success
协程中线程的实现
协程不提供阻塞的方式,但是有时候有些库,和有些接口只能提供阻塞方式连接。于是就可以在协程中继承阻塞io