文本开始之前先把下载地址附上:小工具
本人平时喜欢下载一些高清的电影和资料,一般找到的都是BT种子,通过迅雷下载以后,有时候就没有去管他了,有些稀缺的资源找不到来源,也找不到对应的种子,后来到迅雷的程序目录下面发现很多种子
种子存放路径是:安装目录ThunderProfilesTorrents
但是根据这些种子的名字是无法判别里面的内容是什么,一个一个点击又太麻烦,作为一个码农,我就想是不是可以去解析这些种子的内容,并且提供快速查询。
说干就干,反正咱就是干这一行的,百度了BT文件解析,网上也有现成的代码,关键代码如下:
/// <summary> /// 读取结构 /// </summary> /// <param name="TorrentBytes"></param> /// <param name="StarIndex"></param> /// <param name="Keys"></param> /// <returns></returns> private bool GetValueText(byte[] TorrentBytes, ref int StarIndex, string Keys) { switch (Keys) { case "ANNOUNCE": TorrentAnnounce = GetKeyText(TorrentBytes, ref StarIndex).ToString(); break; case "ANNOUNCE-LIST": int ListCount = 0; ArrayList _TempList = GetKeyData(TorrentBytes, ref StarIndex, ref ListCount); for (int i = 0; i != _TempList.Count; i++) { TorrentAnnounceList.Add(_TempList[i].ToString()); } break; case "CREATION DATE": object Date = GetKeyNumb(TorrentBytes, ref StarIndex).ToString(); if (Date == null) { if (OpenError.Length == 0) OpenError = "CREATION DATE 返回不是数字类型"; return false; } TorrentCreateTime = TorrentCreateTime.AddTicks(long.Parse(Date.ToString())); break; case "CODEPAGE": object CodePageNumb = GetKeyNumb(TorrentBytes, ref StarIndex); if (CodePageNumb == null) { if (OpenError.Length == 0) OpenError = "CODEPAGE 返回不是数字类型"; return false; } TorrentCodePage = long.Parse(CodePageNumb.ToString()); break; case "ENCODING": TorrentEncoding = GetKeyText(TorrentBytes, ref StarIndex).ToString(); break; case "CREATED BY": TorrentCreatedBy = GetKeyText(TorrentBytes, ref StarIndex).ToString(); break; case "COMMENT": TorrentComment = GetKeyText(TorrentBytes, ref StarIndex).ToString(); break; case "COMMENT.UTF-8": TorrentCommentUTF8 = GetKeyText(TorrentBytes, ref StarIndex).ToString(); break; case "INFO": int FileListCount = 0; GetFileInfo(TorrentBytes, ref StarIndex, ref FileListCount); break; case "NAME": TorrentName = GetKeyText(TorrentBytes, ref StarIndex).ToString(); break; case "NAME.UTF-8": TorrentNameUTF8 = GetKeyText(TorrentBytes, ref StarIndex).ToString(); break; case "PIECE LENGTH": object PieceLengthNumb = GetKeyNumb(TorrentBytes, ref StarIndex); if (PieceLengthNumb == null) { if (OpenError.Length == 0) OpenError = "PIECE LENGTH 返回不是数字类型"; return false; } TorrentPieceLength = long.Parse(PieceLengthNumb.ToString()); break; case "PIECES": TorrentPieces = GetKeyByte(TorrentBytes, ref StarIndex); break; case "PUBLISHER": TorrentPublisher = GetKeyText(TorrentBytes, ref StarIndex).ToString(); break; case "PUBLISHER.UTF-8": TorrentPublisherUTF8 = GetKeyText(TorrentBytes, ref StarIndex).ToString(); break; case "PUBLISHER-URL": TorrentPublisherUrl = GetKeyText(TorrentBytes, ref StarIndex).ToString(); break; case "PUBLISHER-URL.UTF-8": TorrentPublisherUrlUTF8 = GetKeyText(TorrentBytes, ref StarIndex).ToString(); break; case "NODES": int NodesCount = 0; ArrayList _NodesList = GetKeyData(TorrentBytes, ref StarIndex, ref NodesCount); int IPCount = _NodesList.Count / 2; for (int i = 0; i != IPCount; i++) { TorrentNotes.Add(_NodesList[i * 2] + ":" + _NodesList[(i * 2) + 1]); } break; default: return false; } return true; }
然后就是各种整合,处理,思考,发现功能也不需要太多(程序员的通病,总是考虑过多的可能需求),于是乎界面出炉了

功能也很简单,就是设置文件夹,然后获取文件夹和子文件夹下面所有的种子文件,调用解析类获取文件信息,加入到队列里面。因为文件比较多,加载会比较慢,因此也做了一个异步线程去执行解析,解析完成以后如下:
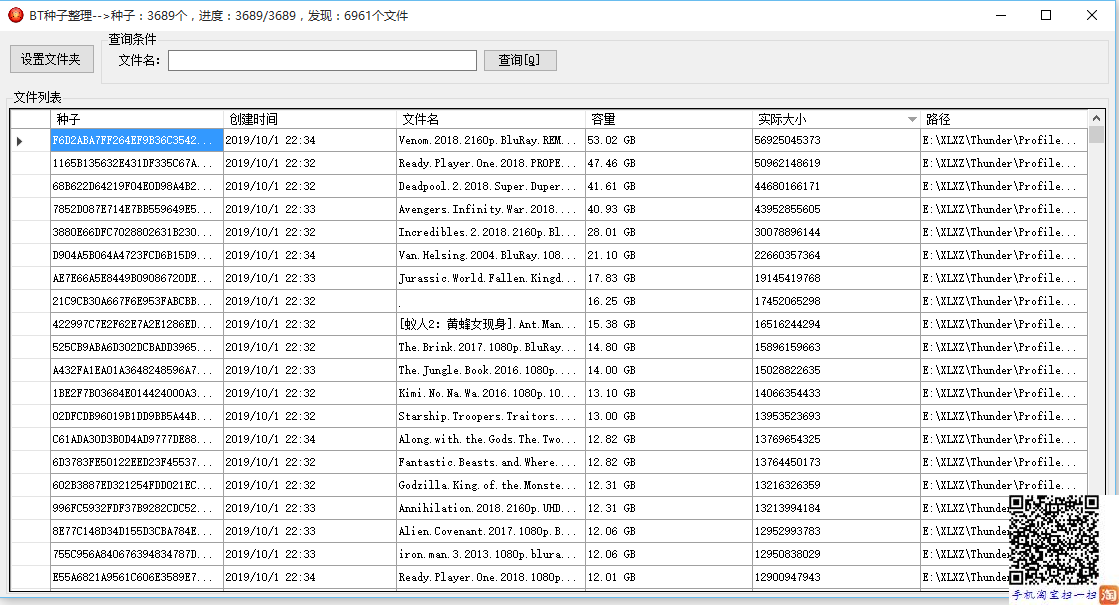
吼吼吼,发现自己原来下载了这么多的文件。目前也就先实现了这么些功能,程序很简单。