D:MYSQLmysql-5.7.20-winx64mysql-5.7.20-winx64dataWIN-20171216YUR-slow.log是慢日志: SET timestamp=1515143608; select * from emp where empno = 100004; # Time: 2018-01-05T09:14:17.472000Z # User@Host: root[root] @ localhost [127.0.0.1] Id: 6 # Query_time: 0.704000 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 4000000 SET timestamp=1515143657; select * from emp where empno = 100004; # Time: 2018-01-05T09:15:02.444000Z # User@Host: root[root] @ localhost [127.0.0.1] Id: 6 # Query_time: 0.731000 Lock_time: 0.001000 Rows_sent: 1 Rows_examined: 4000000 SET timestamp=1515143702; select * from emp where empno = 100044; # Time: 2018-01-05T09:15:17.827000Z # User@Host: root[root] @ localhost [127.0.0.1] Id: 6 # Query_time: 0.712000 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 4000000 SET timestamp=1515143717; select * from emp where empno = 105544; # Time: 2018-01-05T09:30:59.422000Z # User@Host: root[root] @ localhost [127.0.0.1] Id: 6 # Query_time: 3.686000 Lock_time: 0.001000 Rows_sent: 5 Rows_examined: 4000000 SET timestamp=1515144659; select * from emp where ename='OfjJBN'; 四种索引(主键索引/唯一索引/全文索引/普通索引) 说起提高数据库性能,索引是最物美价廉的东西了。不用加内存,不用改程序,不用调sql,只要执行个正确的’create index’,查询速度就可能提高百倍千倍,这可真有诱惑力。可是天下没有免费的午餐,查询速度的提高是以插入、更新、删除的速度为代价的,这些写操作,增加了大量的I/O。 Mysql发现和查询语句是一样的时候会从缓存中取。
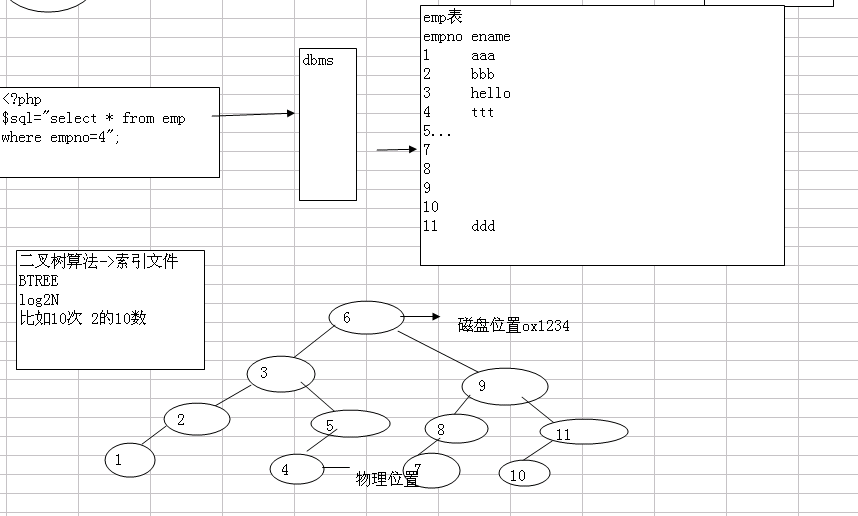
添加索引后,只有通过索引来查就快,不通过索引查是不会快的。 .frm是表的结构,.MYD是表的数据,.MYI是索引文件。 只是拷贝.MYD文件到另一个数据库下面,索引要重新建立,因为索引里面包含有原始.MYD数据的原硬盘的地址,即使把.MYI文件拷贝过去也不行。 为什么建了索引就会变快(原来0.8秒的变成了0.003秒), 原来数据就是1,2,3,4,5,6,7,不加索引的时候从1一直到4,即使到了4仍然继续向下找,因为不敢保证后面还有没有4,因此要全部检索完毕,所以就慢了。 二叉树算法:首先建立索引文件MYI,首先扫描emp有多少数据,然后构建一个二叉树记录中间的6(磁盘硬盘都是有物理地址的),效率是log以2为底N次幂。 Hash算法: