一、sys模块
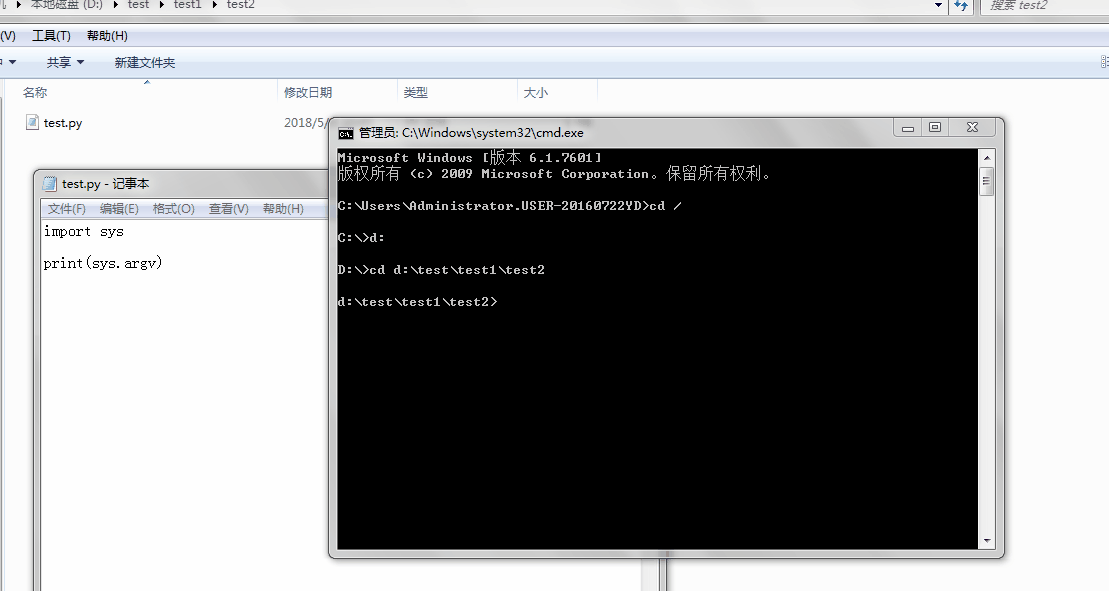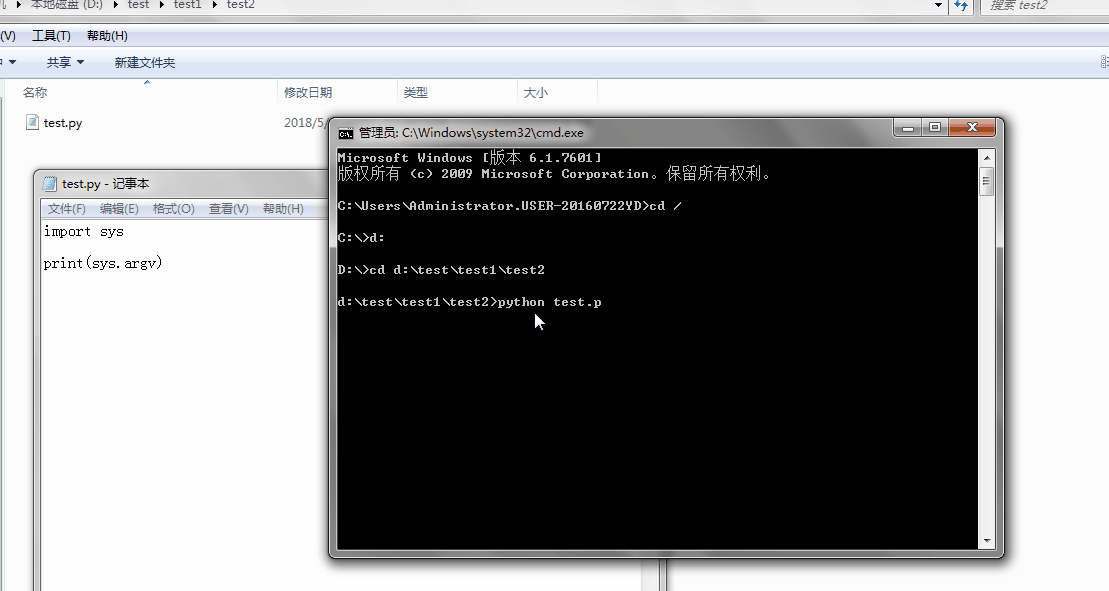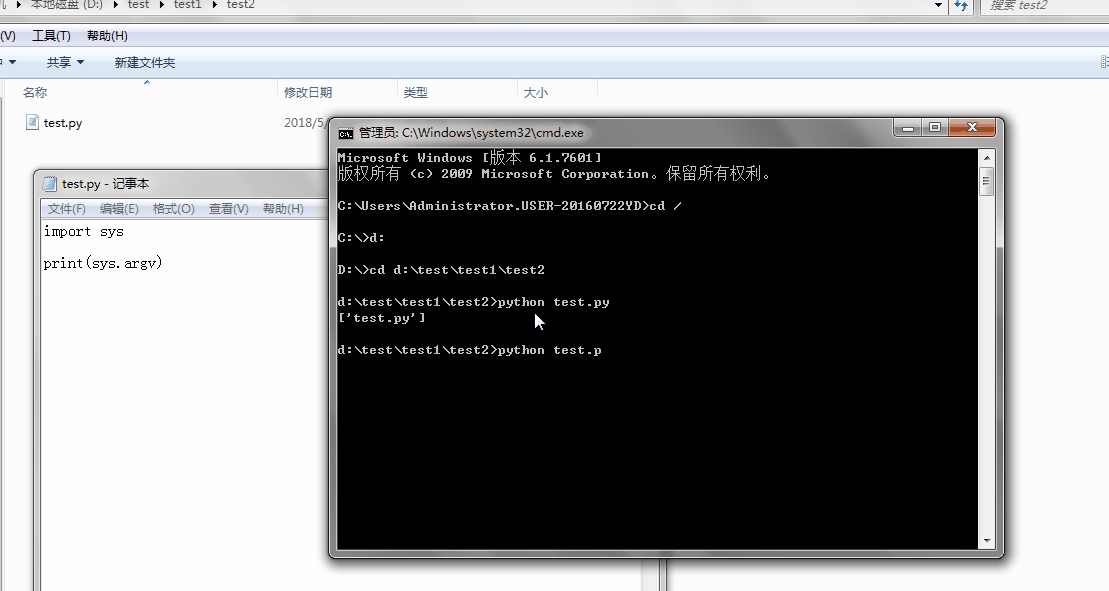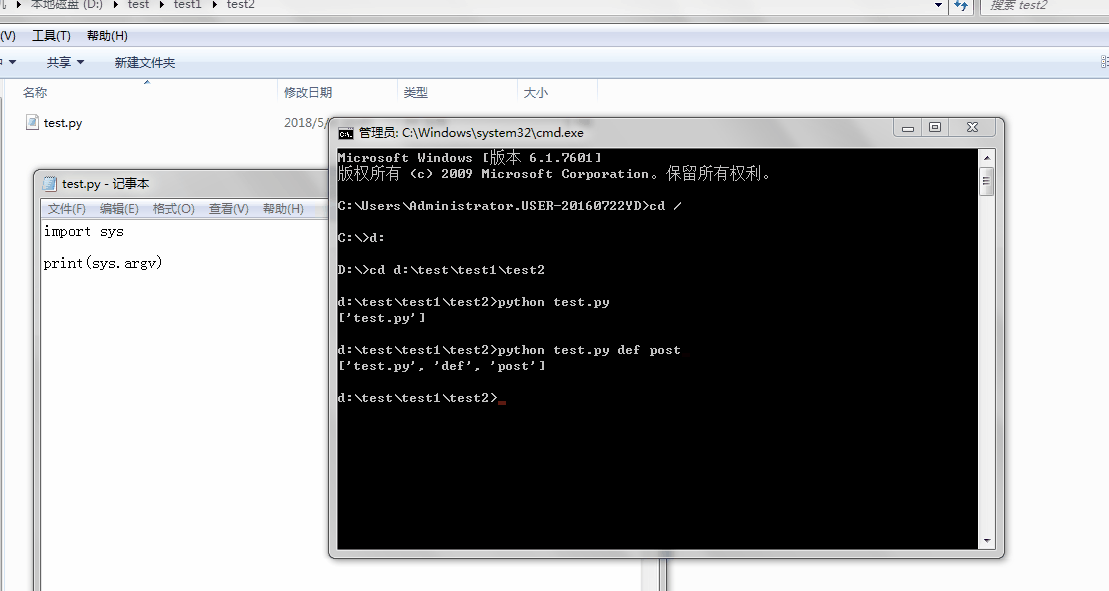
1、sys.argv
命令行参数List,第一个元素是程序本身路径
%E3%80%90day22%E3%80%91sys.argv1.gif?lastModify=1525869572)
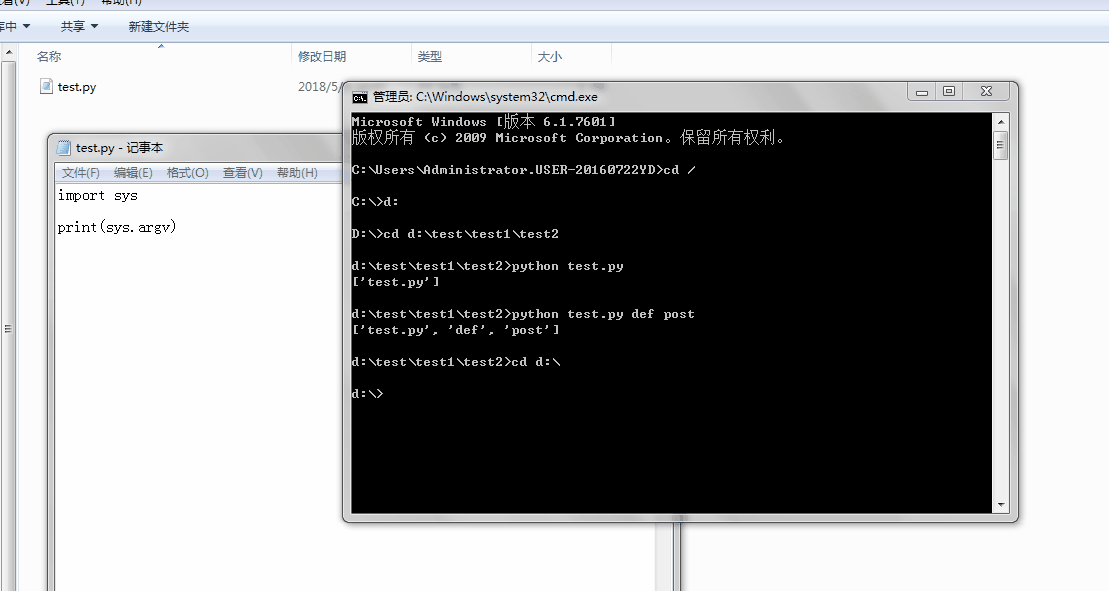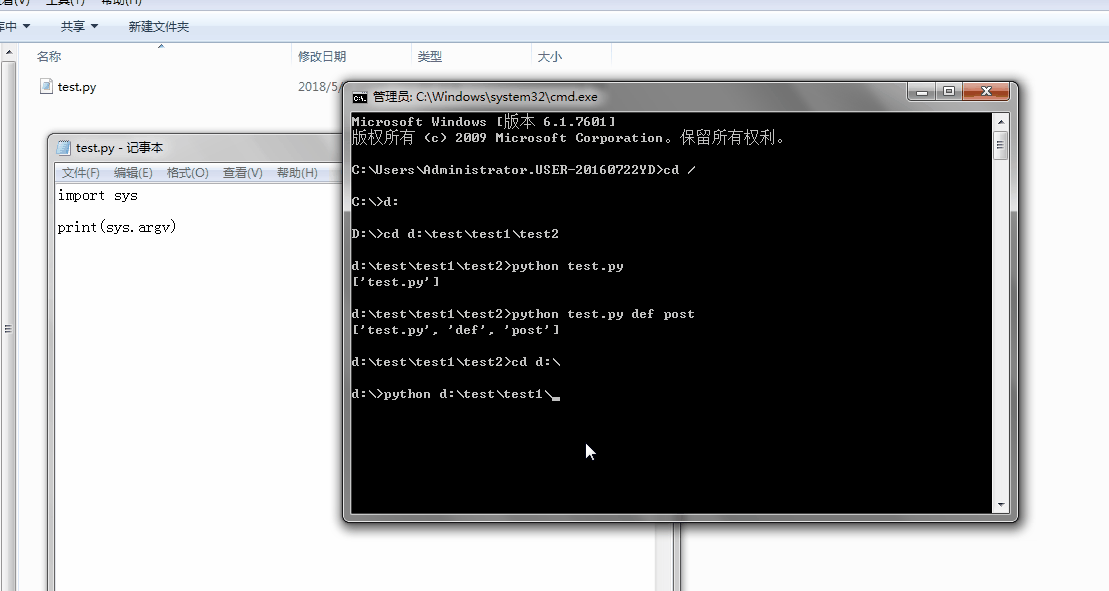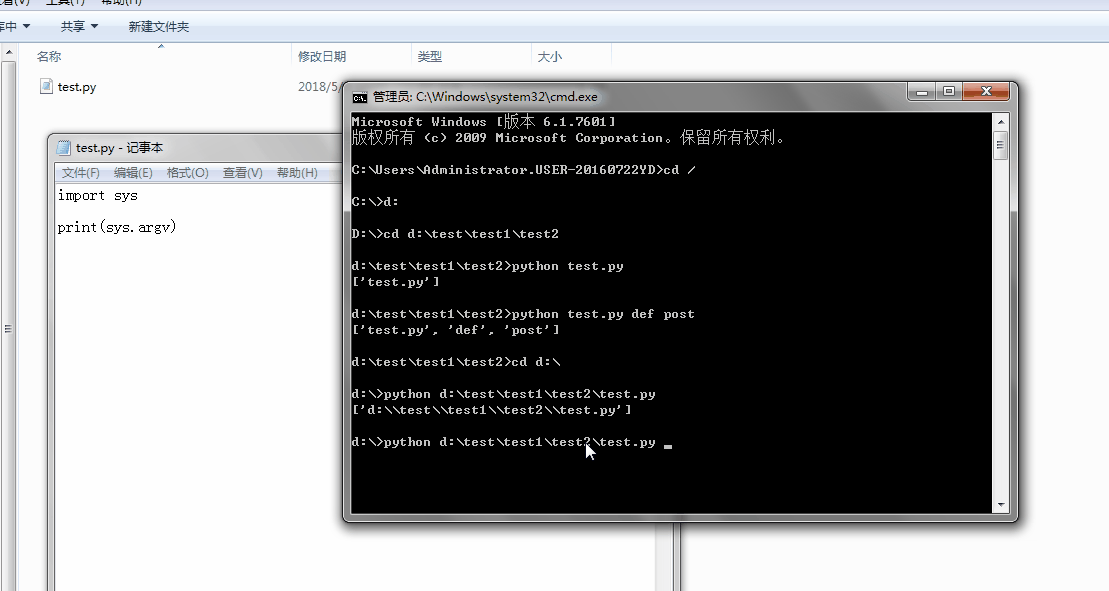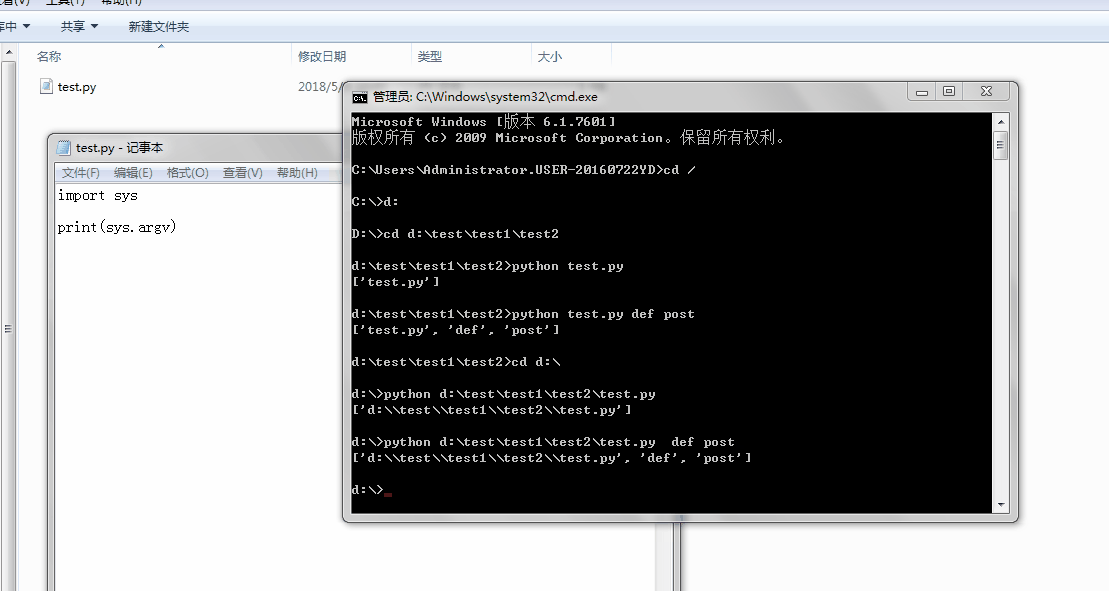
%E3%80%90day22%E3%80%91sys.argv%202.gif?lastModify=1525869572)
2、sys.exit(n)
退出程序,正常退出时exit(0)
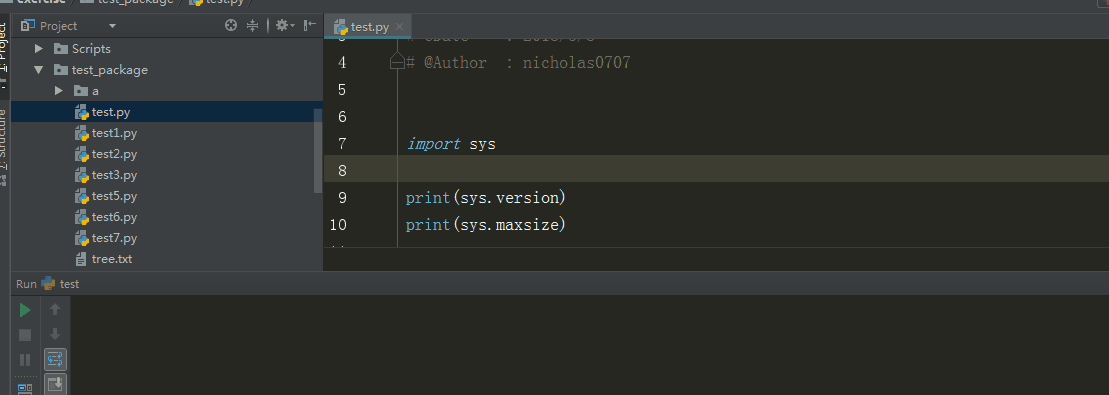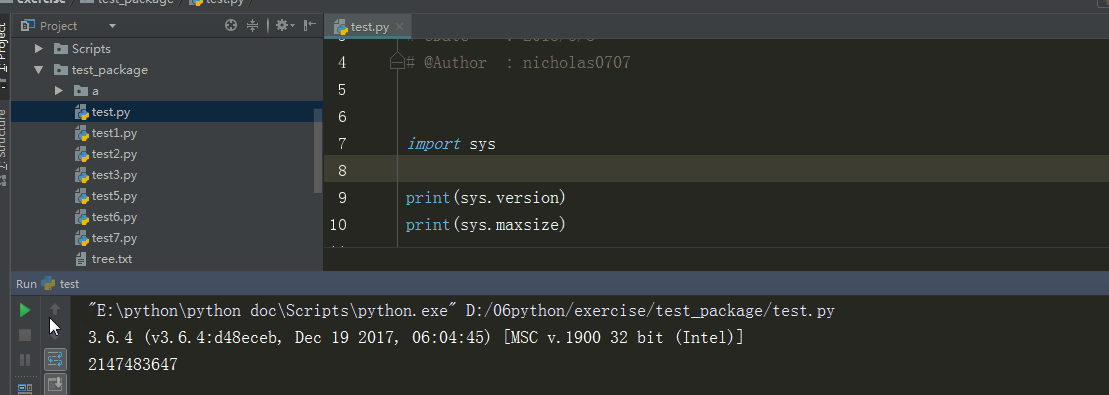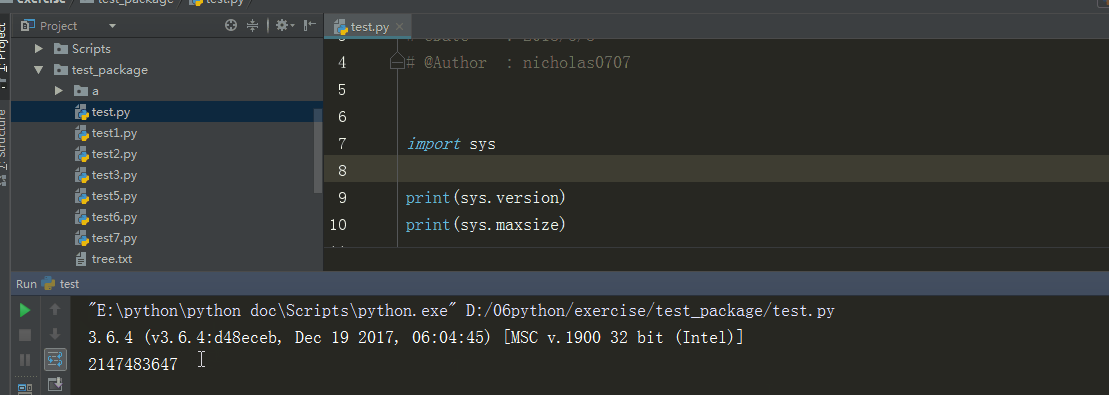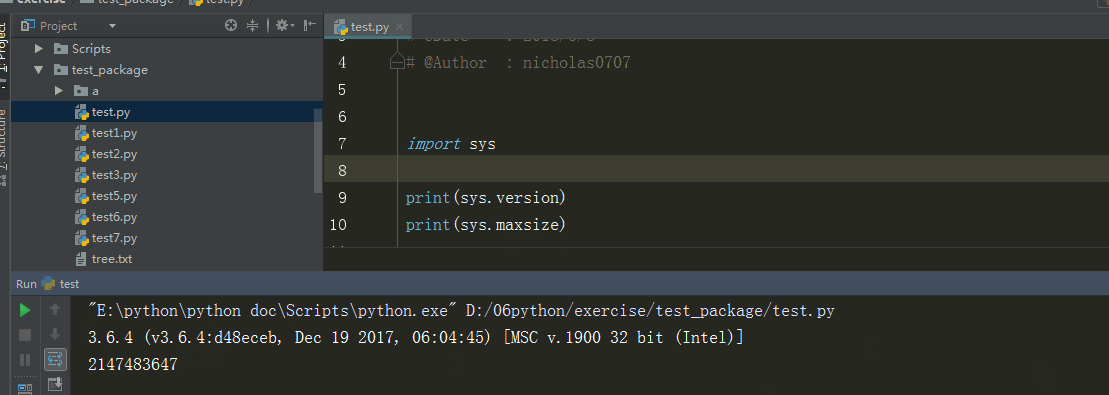
3、sys.version 、 sys.maxint
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
%E3%80%90day22%E3%80%91sys.version%20%E3%80%81%20sys.maxint%20%20.gif?lastModify=1525869572)
4、sys.path
返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
%E3%80%90day22%E3%80%91sys.path.gif?lastModify=1525869572)

分析:sys.path输出的第一个结果是程序执行文件所在的文件夹绝对路径,这里的输出结果第二个是工程文件目录,但是这个目录是pycharm自主加上的,直接用解释器执行是没有这个路径的。
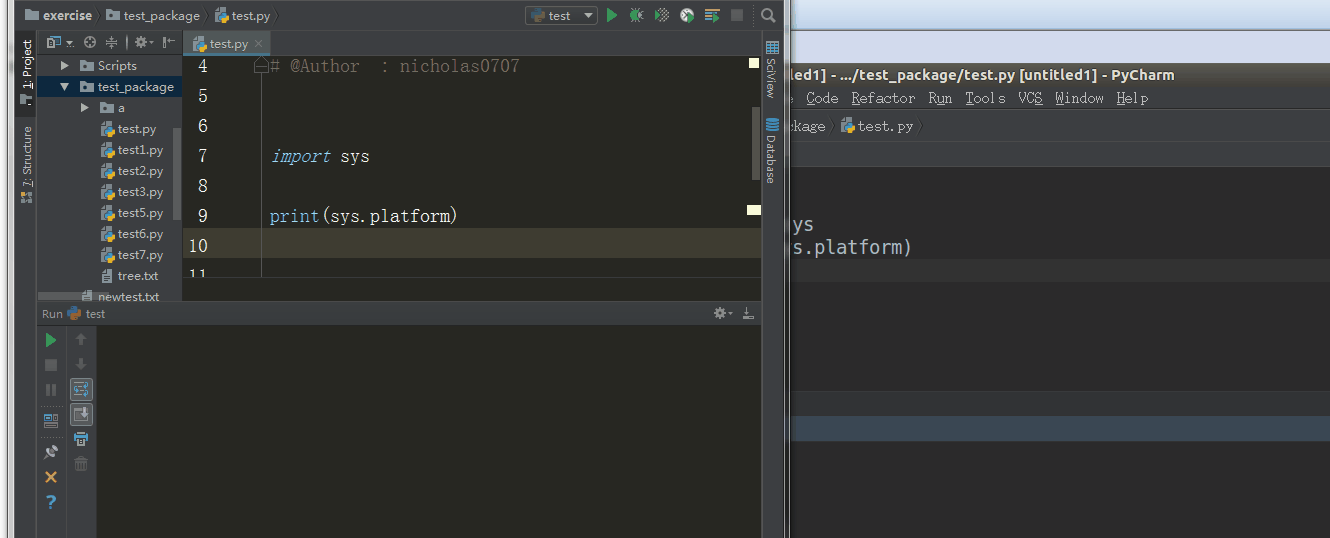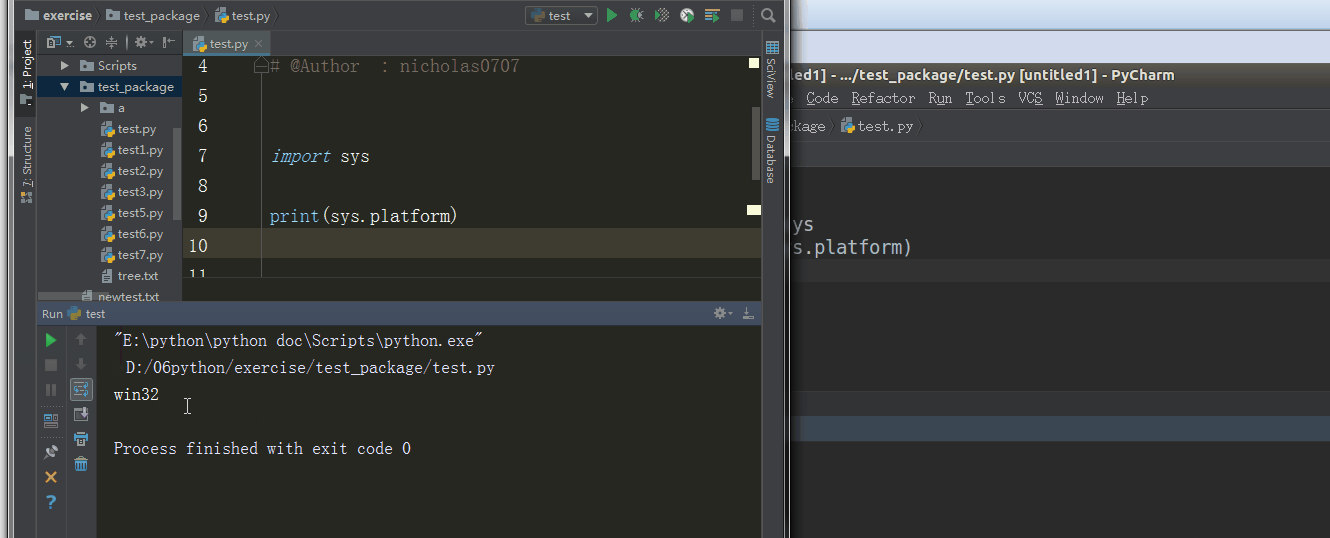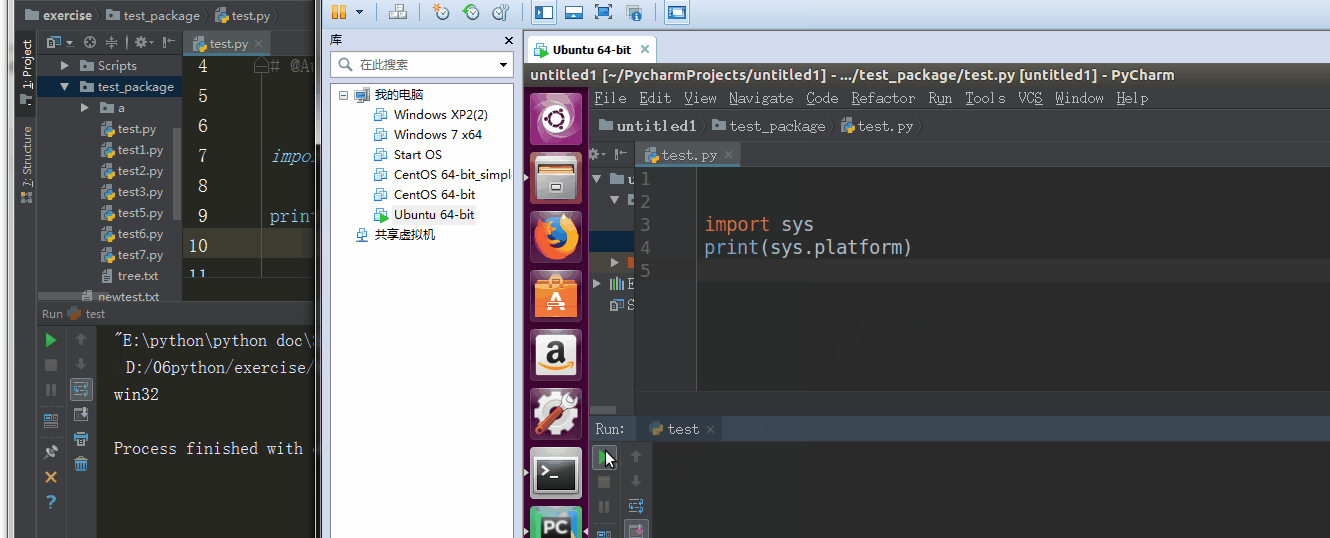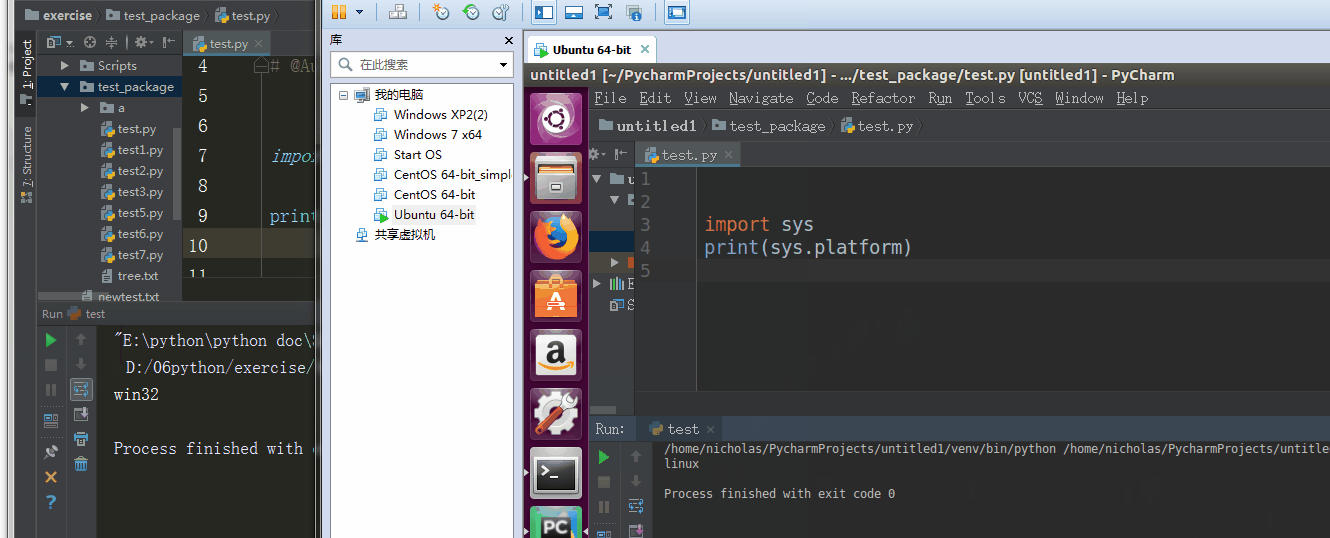
5、sys.platform
返回操作系统平台名称
%E3%80%90day22%E3%80%91sys.platform%20%20.gif?lastModify=1525869572)
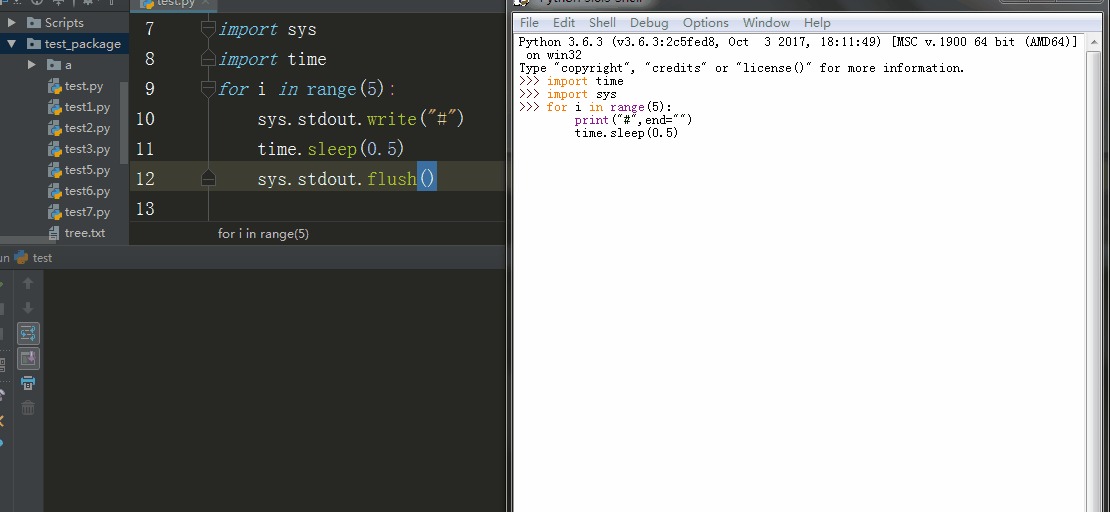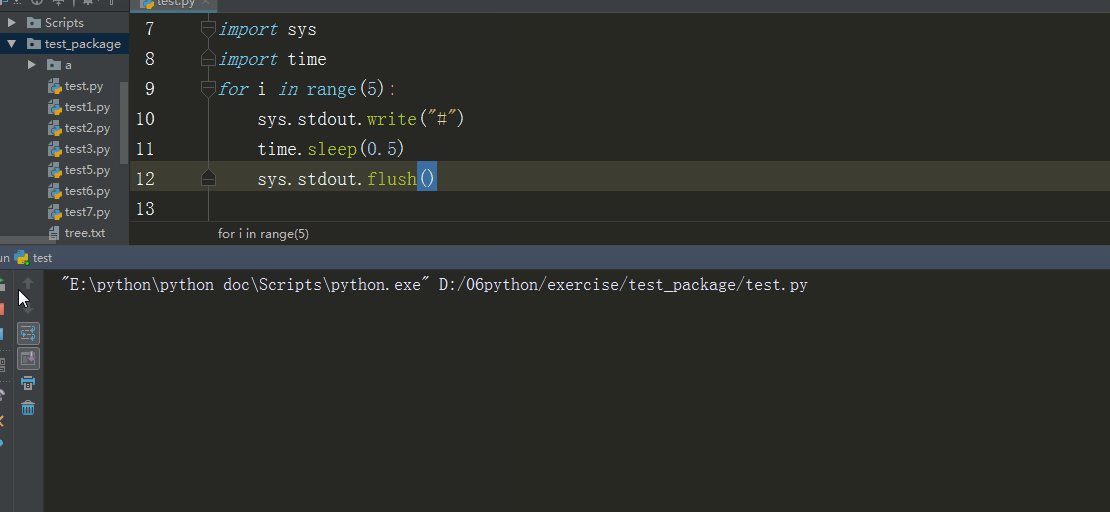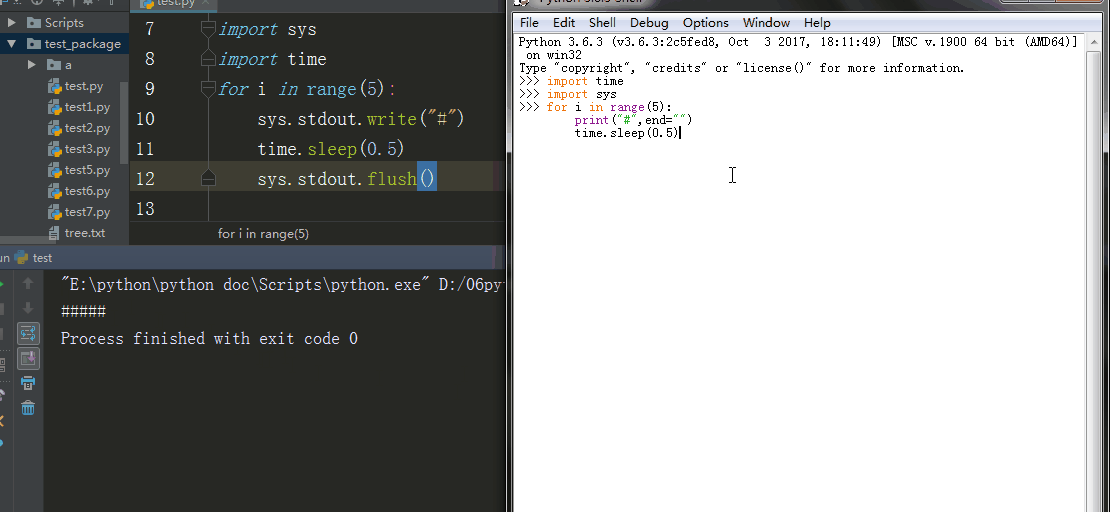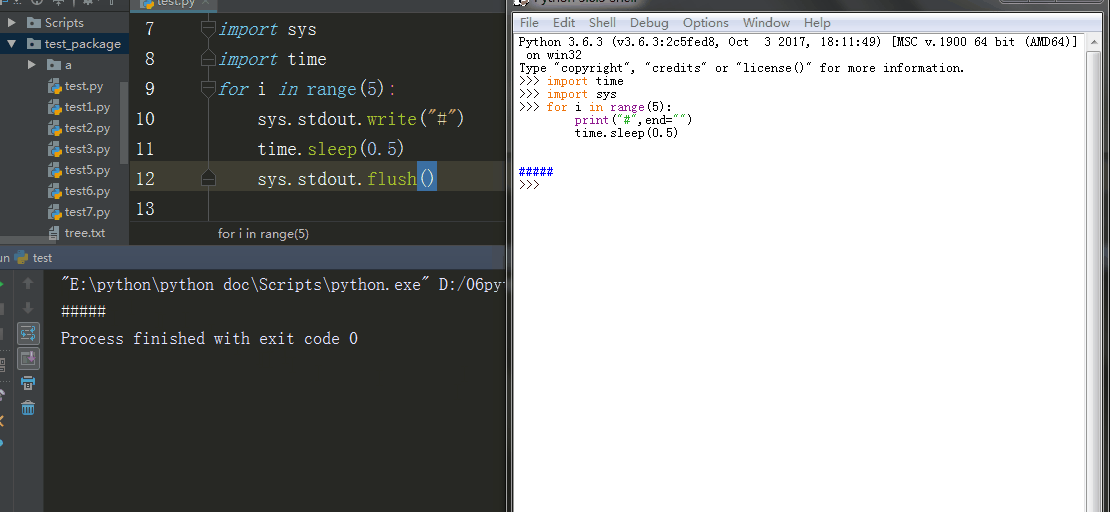
6、sys.stdout.write() 、sys.stdout.flush()
sys.stdout.write() 标准输出 , sys.stdout.write 在交互器模式下这个函数输出数据到stdout,同时还有一个返回值,就是字符串的长度。在pycharm里输出不会有字符串的长度。
sys.stdout.flush() 刷新输出

在Linux系统下,必须加入sys.stdout.flush()才能一秒输一个字符(交互器模式下)
在Windows系统下,加不加sys.stdout.flush()都能一秒输出一个字符(交互器模式下)
在pycharm里都必须加sys.stdout.flush()才能刷新输出
%E3%80%90day22%E3%80%91sys.stdout.write.gif?lastModify=1525869572)
例子
需求:做一个简单的进度条
%E3%80%90day22%E3%80%91\%E7%AE%80%E5%8D%95%E8%BF%9B%E5%BA%A6%E6%9D%A1.gif?lastModify=1525869572)
7、 sys.stdin.readline() 、sys.getrecursionlimit() 、sys.setrecursionlimit(1200)
sys.stdin.readline()[:-1] 标准输入
sys.getrecursionlimit() 获取最大递归层数
sys.setrecursionlimit(1200) 设置最大递归层数
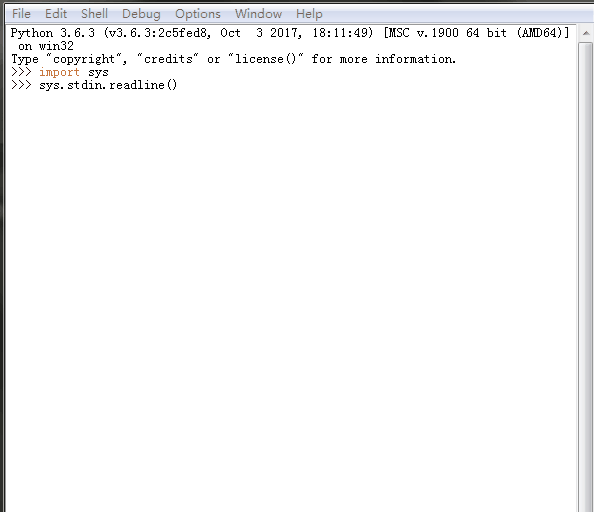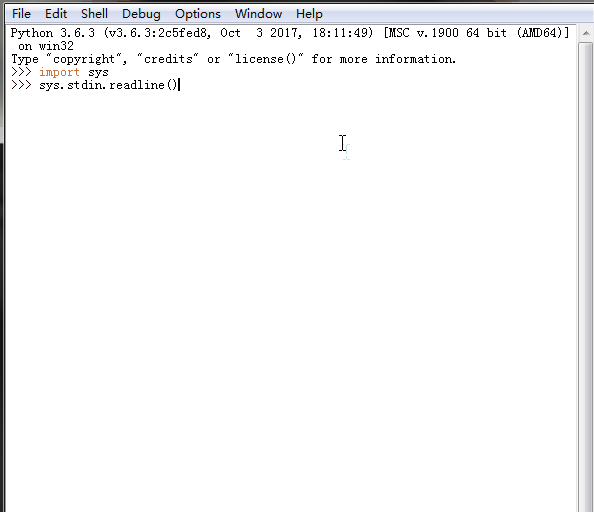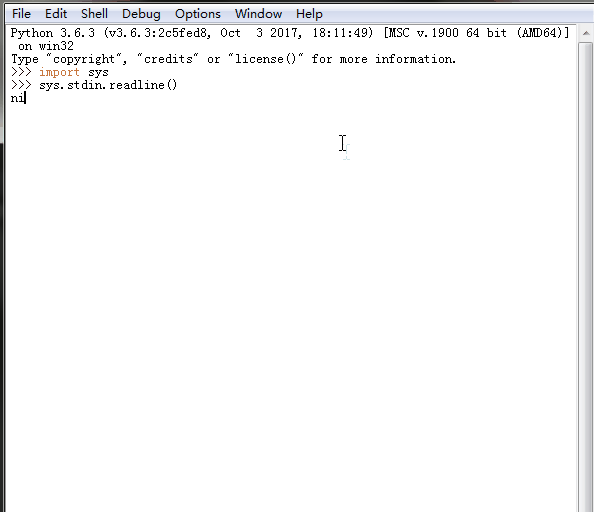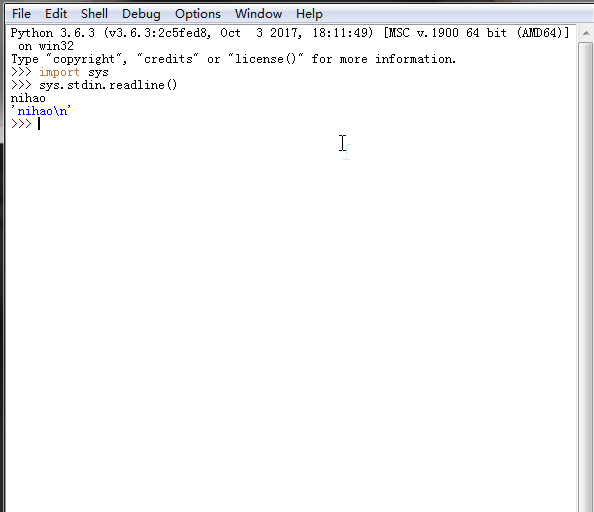
%E3%80%90day22%E3%80%91sys.stdin.readline.gif?lastModify=1525869572)
8、sys.getdefaultencoding() 、sys.getfilesystemencoding
sys.getdefaultencoding() 获取解释器默认编码
sys.getfilesystemencoding 获取内存数据存到文件里的默认编码
二、json模块、pickle模块
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,Python的Json模块有序列化与反序列化两个过程。即 encoding和 decoding。
-
encoding:把一个python对象编码转换成Json字符串。
-
decoding:把json格式字符串编码转换成python对象。
什么是序列化、反序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
即把python中的对象变成可存储的json字符串。序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
JSON和Python内置的数据类型对应关系
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
%E3%80%90day22%E3%80%91json%E5%92%8Cpython%E4%B9%8B%E9%97%B4%E6%95%B0%E6%8D%AE%E7%B1%BB%E5%9E%8B%E7%9A%84%E5%AF%B9%E5%BA%94%E5%85%B3%E7%B3%BB.png?lastModify=1525869572)

json和python之间相互转换
%E3%80%90day22%E3%80%91json%E5%92%8Cpython%E4%B9%8B%E9%97%B4%E7%9B%B8%E4%BA%92%E8%BD%AC%E6%8D%A2.png?lastModify=1525869572)

json的4个方法
json提供四个功能:dumps, dump, loads, load
1、dumps和dump
序列化过程
将一个python对象编码转换成Json字符串,可以存储可以网络远程传输
dumps只完成了序列化为str,将数据通过特殊的形式转换为所有程序语言都认识的字符串
dump必须传文件描述符,将序列化的str保存到文件中,将数据通过特殊的形式转换为所有程序语言都认识的字符串,并写入文件
dumps()用法
例子
import json
dic = {"k1":"v1"}
str1= "nicholas"
data1 = json.dumps(dic)
data2 = json.dumps(str1)
print(data1)
print(data2)
print(type(data1))
print(type(data2))
输出结果

%E3%80%90day22%E3%80%91dumps.gif?lastModify=1525869572)
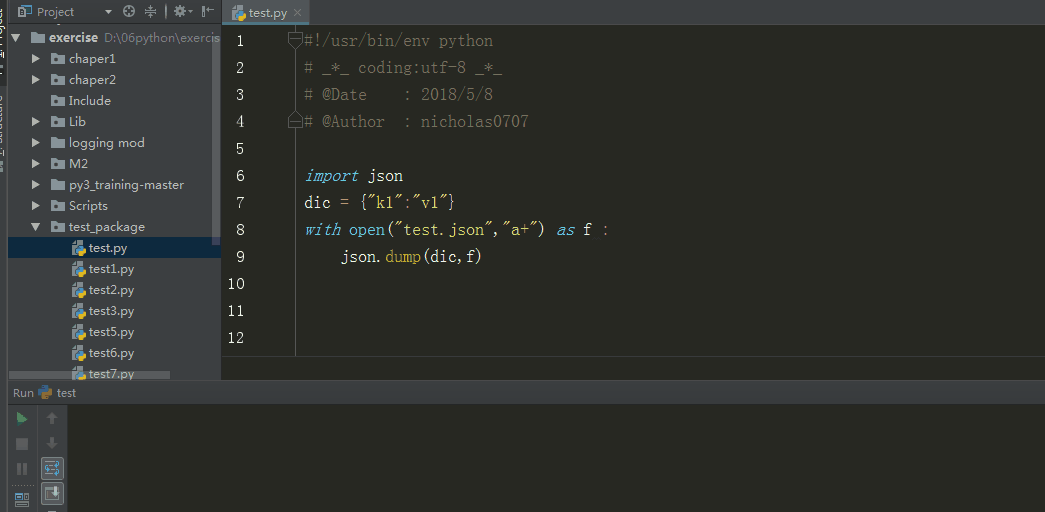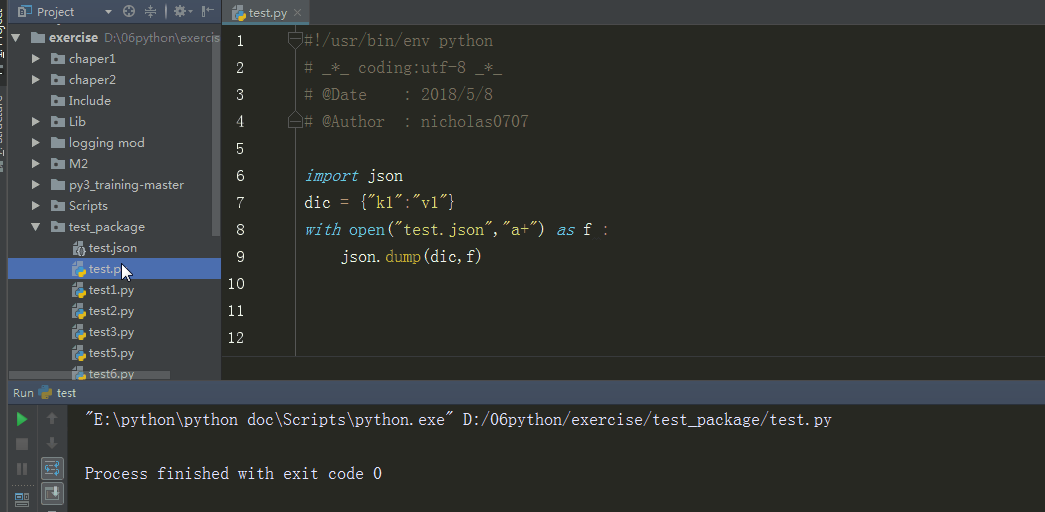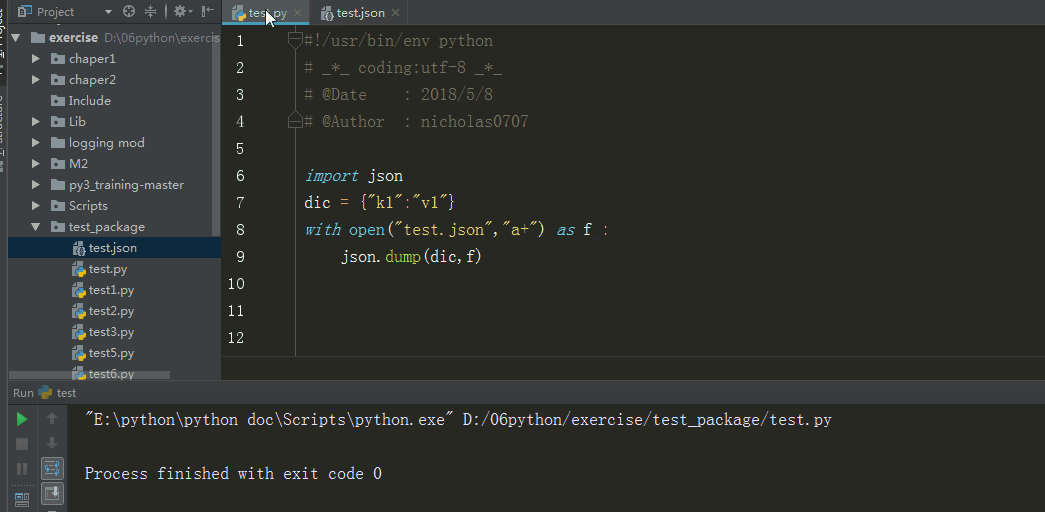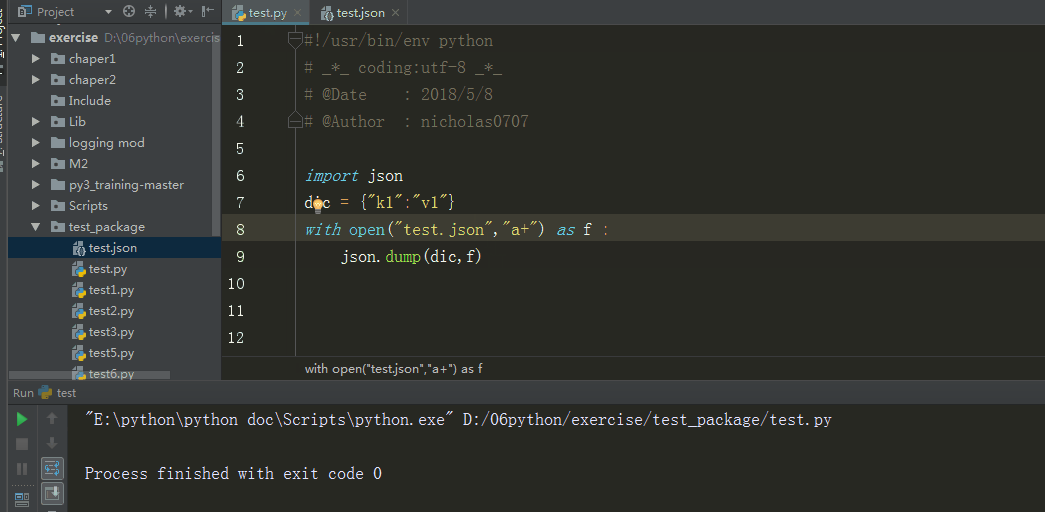
dump
例子
import json
dic = {"k1":"v1"}
with open("test.json","a+") as f :
json.dump(dic,f)#传入要序列化的数据、文件描述符
输出结果
%E3%80%90day22%E3%80%91dump.gif?lastModify=1525869572)
分析:数据通过json.dump转换为所有程序语言都认识的字符串,并写入文件
dump等价于dumps加上打开文件然后将data = json.dumps(var) 写入文件。
例子
import json
dic = {"k1":"v1"}
data = json.dumps(dic)
with open("test.json","a+") as f :
f.write(data)
2、loads 和 load
loads 只完成了反序列化,将json编码的字符串再转换为python的数据结构
load 只接收文件描述符,完成了读取文件和反序列化,数据文件中读取数据,并将json编码的字符串转换为python的数据结构
用loads例子
import json
with open("test.json") as f :
data = json.loads(f.read()) #需要加入f.read()方法读取文件数据
print(data)
print(type(data))
输出结果
{'k1': 'v1'}
<class 'dict'>
用load例子2
import json
with open("test.json") as f :
data = json.load(f) #直接加入文件描述符即可
print(data)
print(type(data))
输出结果
{'k1': 'v1'}
<class 'dict'>
pickle和python之间相互转换

Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
%E3%80%90day22%E3%80%91pickle%E5%92%8Cpython%E4%B9%8B%E9%97%B4%E7%9B%B8%E4%BA%92%E8%BD%AC%E6%8D%A2.png?lastModify=1525869572)
picle模块 和json模块都有 dumps、dump、loads、load四种方法,而且用法一样。
不用的是json模块序列化出来的是通用格式,其它编程语言都认识,就是普通的字符串,
而picle模块序列化出来的只有python可以认识,其他编程语言不认识的,表现为乱码
注意json的序列化之后产生的格式是还是字符串,pickle序列化之后产生的格式是字节流,可以直接用于网络传输。
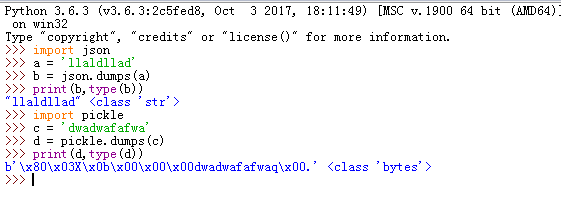
例子1
import pickle
dic = {"k1":"v1"}
with open("test.pickle","wb") as f: #注意这里要用二进制模式,序列化后的对象是'bytes'
data = pickle.dumps(dic)
f.write(data)
或者
import pickle
dic = {"k1":"v1"}
with open("test.pickle","wb") as f:
data = pickle.dump(dic,f)
例子2
import pickle
with open("test.pickle","rb") as f:
data = pickle.loads(f.read())
print(data)
或者
import pickle
with open("test.pickle","rb") as f:
data = pickle.load(f)
print(data)
json vs pickle比较:
JSON:
优点:跨语言、体积小
缺点:只能支持intstrlist upledict
Pickle:
优点:专为python设计,支持python所有的数据类型
缺点:只能在python中使用,存储数据占空间大
三、shelve 模块
shelve是封装了pickle,shelve 只能在python中用
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
序列化:保存对象至shelve文件中
例子
import shelve
f = shelve.open("test")
names = ["nicholas","jack","pony"] #python中的数据
info = {"age":[18,54,48],"some":[1,2,3]} #python中的数据
f["names"] = ["nicholas","jack","pony"] #向文件中添加内容,添加方式与给字典添加键值对类似
f["info"] = {"age":[18,54,48],"some":[1,2,3]} #向文件中添加内容,添加方式与给字典添加键值对类似
f.close() #关闭文件
输出结果
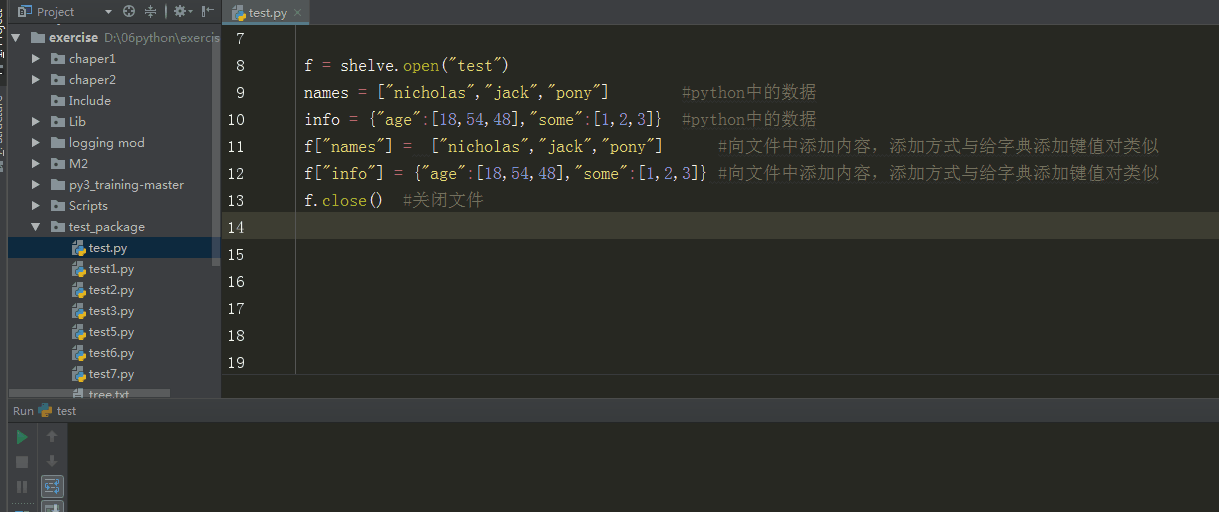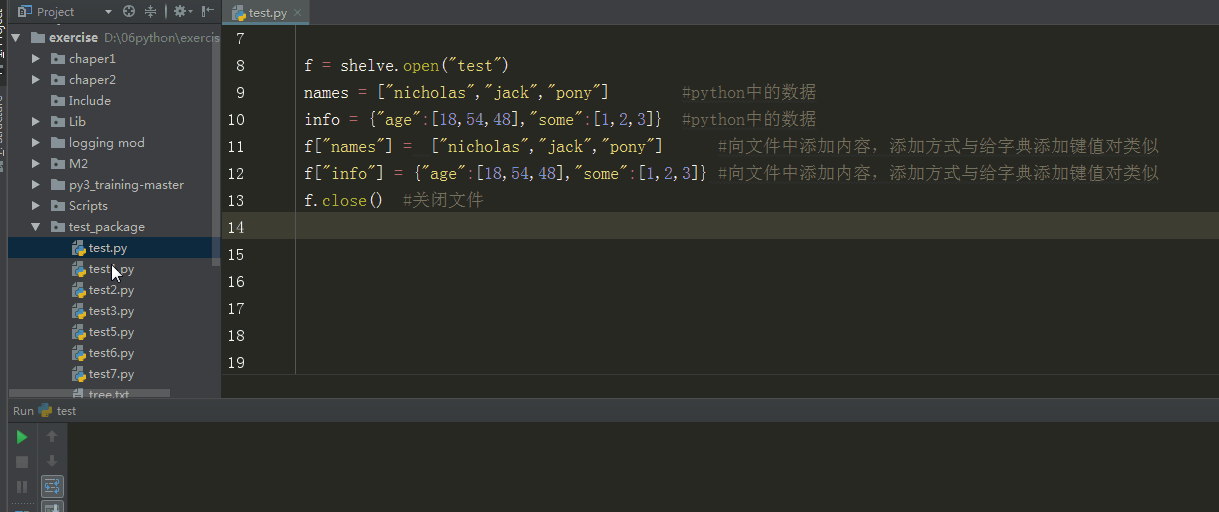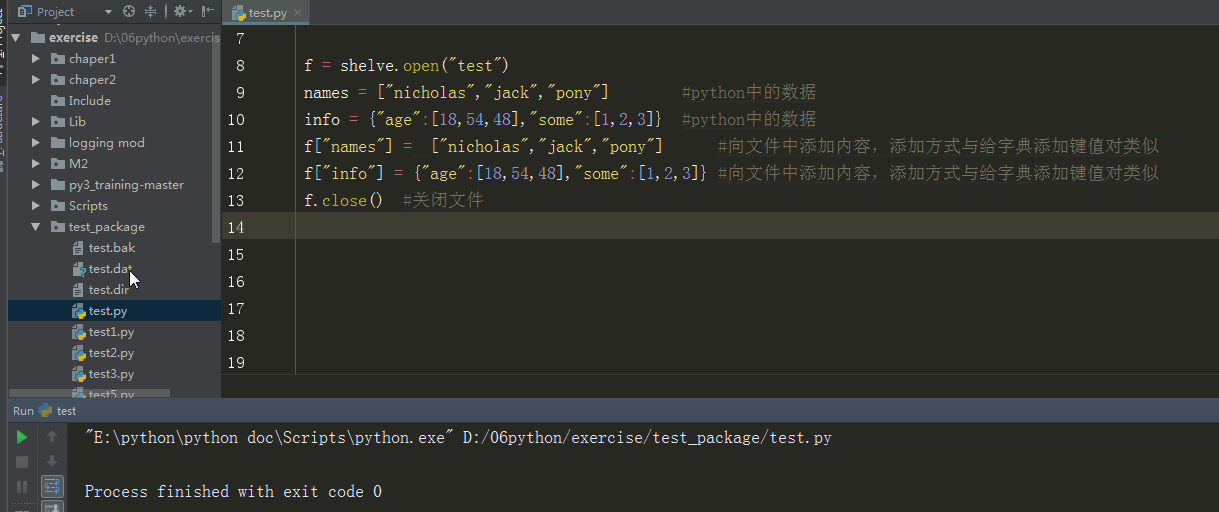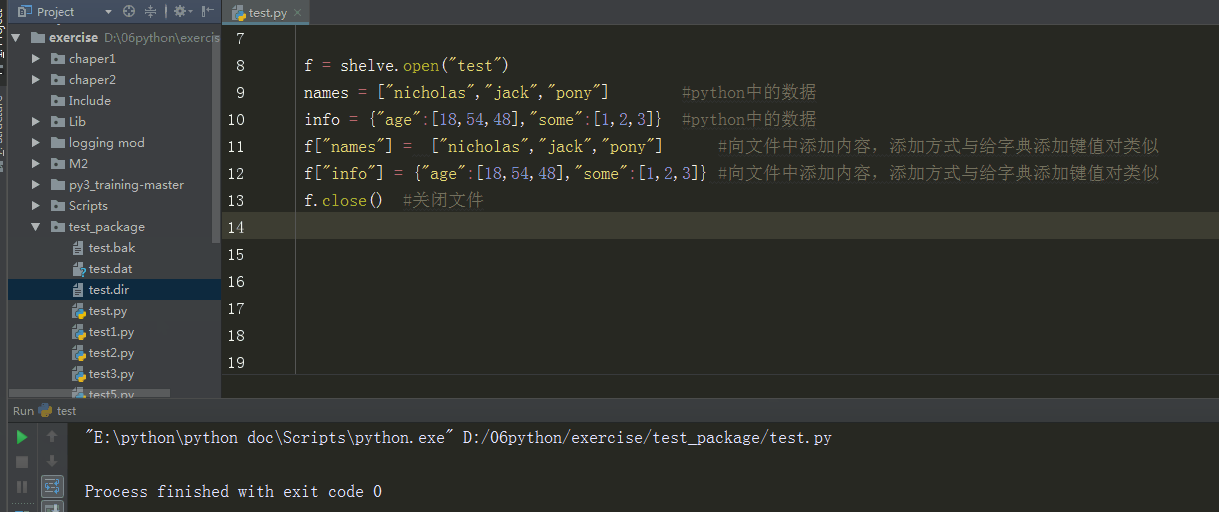
%E3%80%90day22%E3%80%91shelve%E5%BA%8F%E5%88%97%E5%8C%96.gif?lastModify=1525869572)
分析:shelve序列化后产生3个文件
反序列化:从文件中读取对象
例子
import shelve
d = shelve.open("test")
names = d["names"] # 从文件中类似字典中获取键值的方式一样读取内容
info = d["info"]
print(names,type(names))
print(info,type(info))
d.close() #关闭文件
输出结果
%E3%80%90day22%E3%80%91shelve%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96.gif?lastModify=1525869572)
