1、优化前可通过各种手段先观察观察 SOL 涉及的表结构、索引等,看它们有无不合理之处,急于动手改造 SO 太盲目了,是没有抓住主要矛盾的体现。
2、做事要有方法论,要先整体后局部,解决问题要注 重效率,先尽量考虑不改写的优化,再考虑改写的优化 而不改写的优化靠的是 体系结构知识的沉淀,而改写则妥考虑、逻辑等价改写和业务改写两大思路,其中 业务改写是 SQL 优化的最高境界 另外还是妥有一定的知识沉淀,高级 SQL 语法也妥掌握,其在很多场合下能帮上我们大忙。
3、要花一小时时间才定位到某处需要 建立索引,如果建索引有依据的规范并且能快速被体检报告诊断出来。这里涉及了数据库的设计规范。如果性能低下的 SOL 在运行之前能被事先捞取出来, 则很多故障就能避免。这里涉及 SOL 写法的规范。
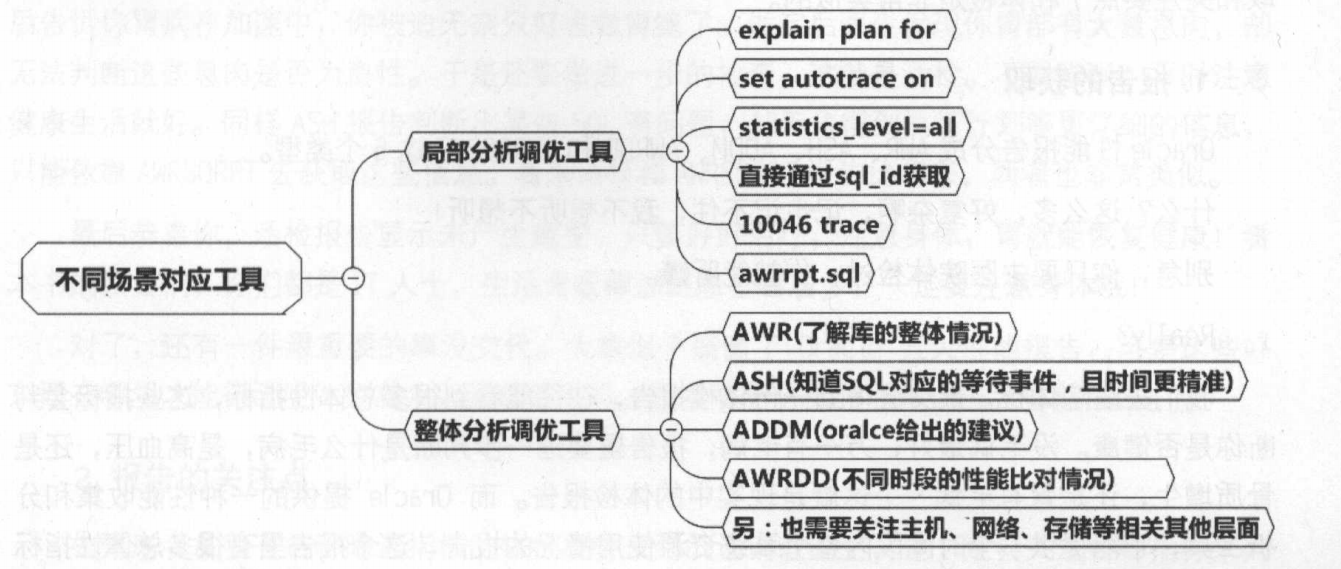
4、性能工具:AWR、ASH、ADDM、AWRDD
AWR:关注数据库的整体性能报告;
ASH:是数据库的等待事件与哪些sql具体对应的报告(生成该报告的命令:@?/rdbms/admin/ashrpt.sql);
ADDM:oracle给出的建议
AWRRD:oracle针对不同时段的性能的比对报告。(生成该报告的命令:@?/rdbms/admin/awrddrpt.sql)
Oracle 提供的一种性能收集和分 析工具,它能提供一个时间段内整个系统资源使用情况的报告 这个报告里有很多总体性指标 来判断系统是否健康。没毛病最好 万一有毛病,问题出在什么模块,是日志切换过于频繁, 还是硬解析过大 还是某些 相关等待事件在耗资源……这就是AWR报告。
假设你的数据库是 SOL 相关等待事件问题, AWR 报告很可能只告诉你有 这个问题而无法告诉你是哪些 sql发的。你要得到这些指标 想了解具体某些 sql和相关等待事件的对应需要做进一步的信息收集 那就是 ASH报告。
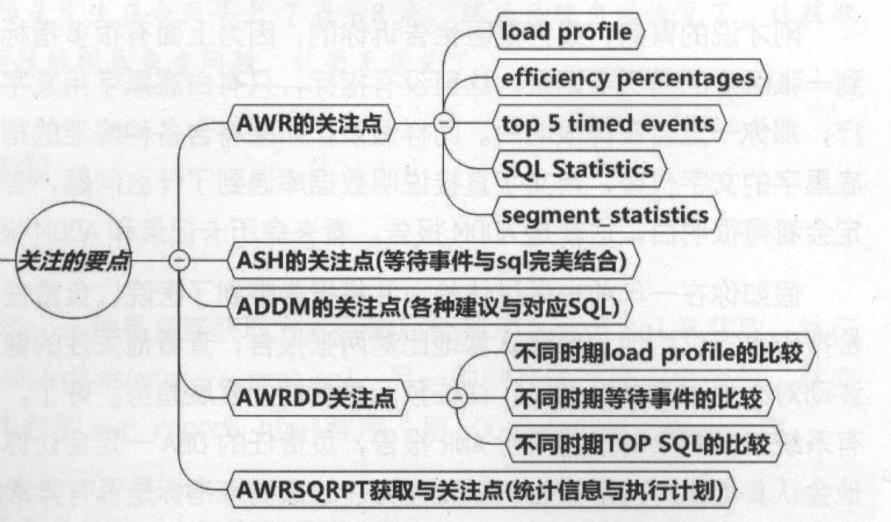
5、AWR需要关注的点:
DB Time、load_profile、efficiency percentages、top 5 events、SQL Statistics、Segment_statistic。
DB Time:指的是花费在数据库调用上的总时间,是数据库负载的指示灯。
load_profile:性能的总体参数,比如redo size显示每秒的日志尺寸和平均每个事务的日志尺寸。Transactions:每秒事务数。
efficiency percentages:命中率指标
....
6、oracle获取执行计划的方法(只摘录3种)
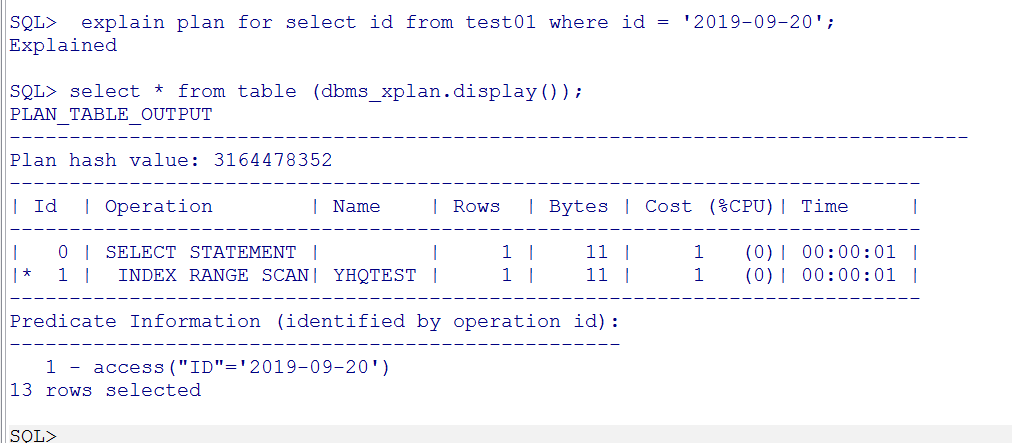
1)、explain plan for select id from test01 where id = '2019-09-20';
select * from table (dbms_xplan.display());
2)、set autotrace on;
set autotrace on;
set linesize 1000;
set timing on;
select * from t3 where rownum<10;
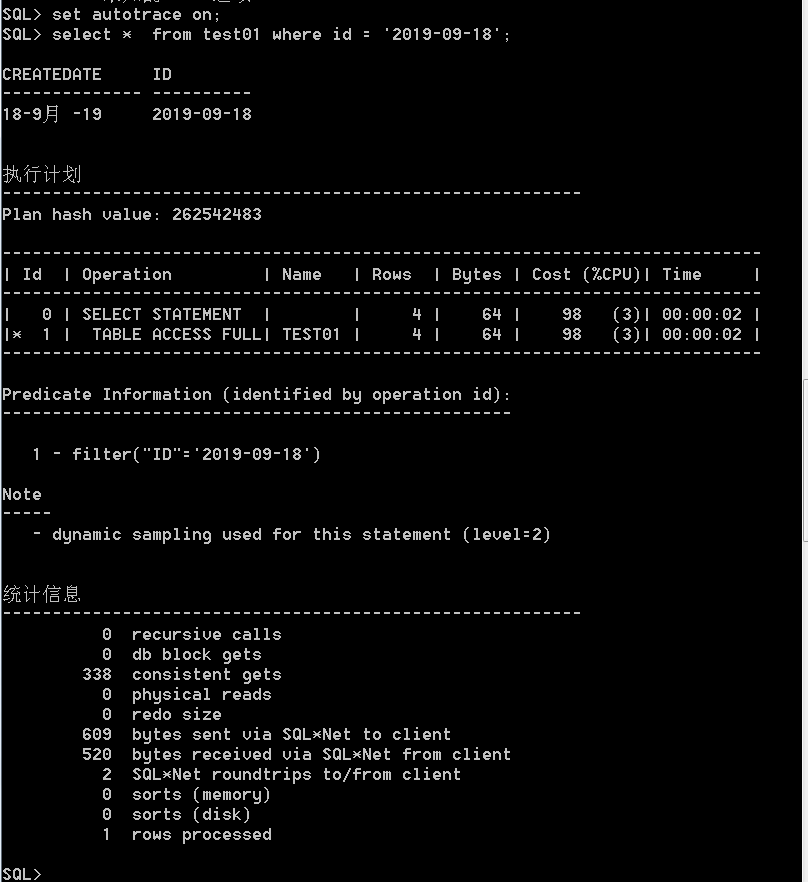
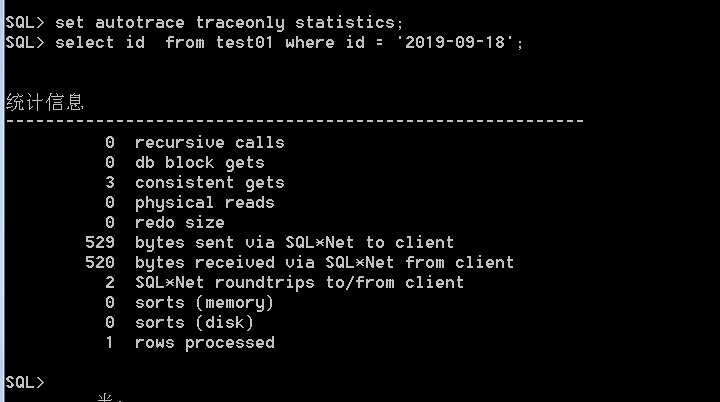
3)、alter session set statistics_level=all ;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last')) ;

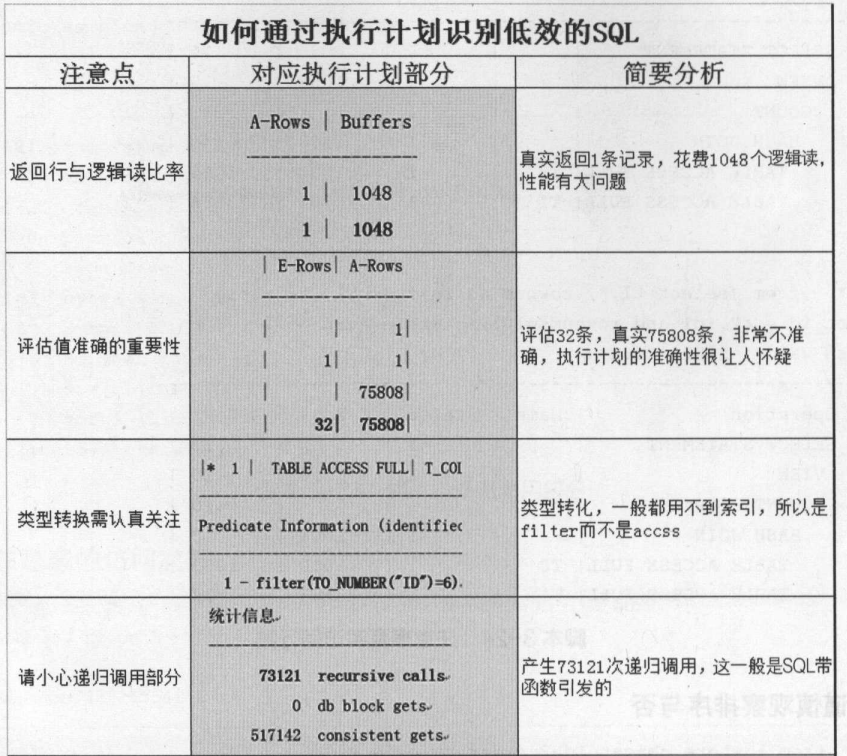
7、执行计划: