kakfka架构图:
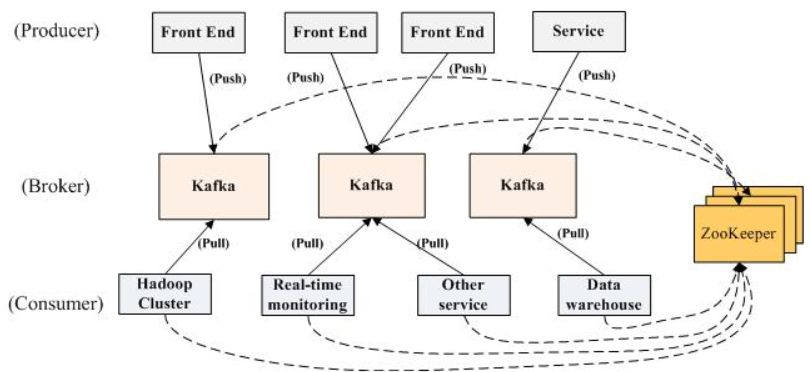
理解kafka需要理解三个问题。
1.producer,broker,consumer,ZK的工作模式。
broker,ZK是作为一个后台服务,而producer和consumer是作为一个SDK提供给开发者进行开发用。
2.producer和consumer的交互类型。
一般的队列模式是采用push模式,传统设计认为push更具备实时性。但是kafka使用的是consumer通过pull去和producer进行交互,这样设计的好处有两个。(1)使用pull可以让系统设计更为简单,producer不用去感知地下consumer的状态,代码设计上会简单许多。(2)通过pullconsumer可以进行消息峰值的控制,避免数据量太大时候压垮cunsumer。宁愿消息暂时性延迟也不愿意consumer宕机。
3.producer是如何知道broker的存在,producer是如何知道发送消息给哪个broker,同样consumer是怎么感知broker的存在,如何知道从那个consumer取数据
从架构图的两个虚线到ZK,是因为kafka从0.8版本开始,kafka开始不用从ZK获取broker的元信息。之前的版本是需要的。0.8版本后,producer可以只指定一个或者多个broker的URL,来获取kafka集群的元信息。(比如集群有300个broker,但是producer只需要指定三个就可以获取到整个broker的集群的活动的列表,每个broker,topic有多少partition,每个partition在哪个broker上,该信息会存储到broker的内存之中进行维护)。而consumer是通过连接ZK,发现kafka集群的元信息(broker的集群的活动的列表,每个broker,topic有多少partition,每个partition在哪个broker上)。
Topic 概念

1.topic可以拥有不同的partition数量,在broker上均匀分配。进行负载均衡
partition的概念
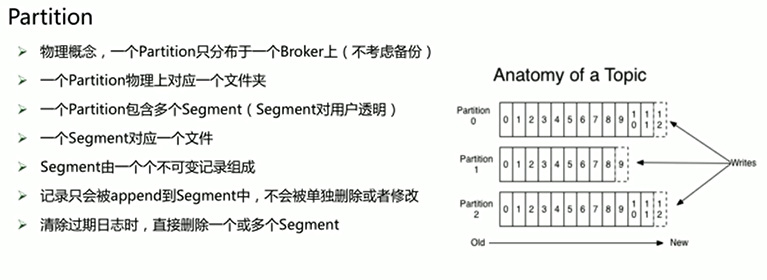
partition之间的序号可以重复,但是partition自己中的segment序号是不可重复的。(定位一条消息需要知道partition的位置,和offset位置才能找)
kafka清理机制有两个(1.基于时间,超过时间删除。2.基于size大小),满足条件会删除整个segment,比如我segment设置100M,超过1G删除,那么10文件就是1000MB,那么当超过1024时候,kafka就会把最后的segment删除,就是剩下924MB,这时候不满足1GB,就停止删除,继续运转。而且删除不是实时性清楚,会有个后台线程进行实时扫描。满足则运行·

参数解析:topic1有三个partition。
kafka存储数据地方:在配置文件里面找到log.dirs(dirs表示可以挂多个磁盘可能对应的多个目录,以便多个磁盘可以加速写入) 路径。
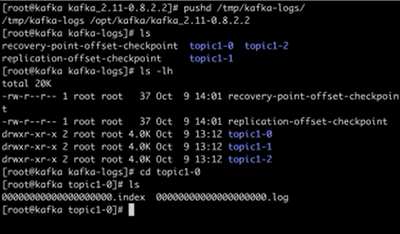
log是消息存储的文件,而index是存储消息的索引。offset对应条目位置。文件名字是以offset最小的条目编号作为文件名字。
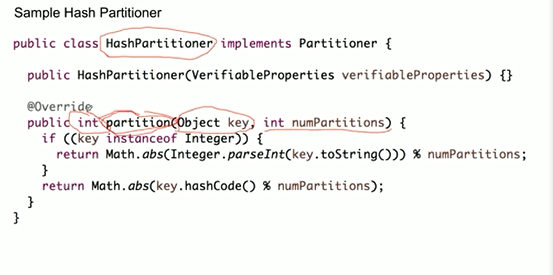
partition的分配方式。
策略1:hashPartitioner(相同key会被分配到同一个partition中)
策略2:roundRobinPartition(保证消息的均匀分布)

策略3:随机分配(默认)
producer的两种方式(同步producer和异步producer)

同步是发送一条跟踪一条,异步是直接把数据发送到一个queue中,后台有一个进程不断去处理这个queue,因为不是马上发送到broder,而是等待这个queue达到一定的数据尺寸才进行处理发送到broker中。如果queue满了kafka会选择把新的数据直接丢掉(-1等待,1数据丢失有参数设置),所以异步的模式会造成数据丢失。