Why CNN for Image

图片是由像素点组成的,可以这样来解释深度神经网络对图片的处理。
第一层的layer是最基本的分类器,区分一些基本的特征,比如颜色、是否有斜线。
第二层的layer会检测更加复杂的东西,比如一些简单的组合线条;
后面的layer也会越来越复杂……
我们可以通过思考图像的特征来简化网络。
1.图片中一些特征通常比整个图片要小,比如要检测图像中是否有鸟嘴。

我们的neuron不需要看整个图像来发现某些特征,所以我们只需要把鸟嘴那一小部分的图片,用很少的参数跟neuron关联起来。
2.同样的特征可能出现在图片的不同位置。

我们不会为每个不同位置的特征单独训练一个neuron,因为它做的都是同样的事情,就是检测是否出现鸟嘴,只是出现的位置不一样罢了。
3.subsampling 可以使图片缩小,但不影响图片的表达。

每隔一行、一列删除一行pixel,就是subsampling,我们同样可以看到图片表达的信息,就是一只鸟。
由于图片缩小了,这样又可以减少参数了。
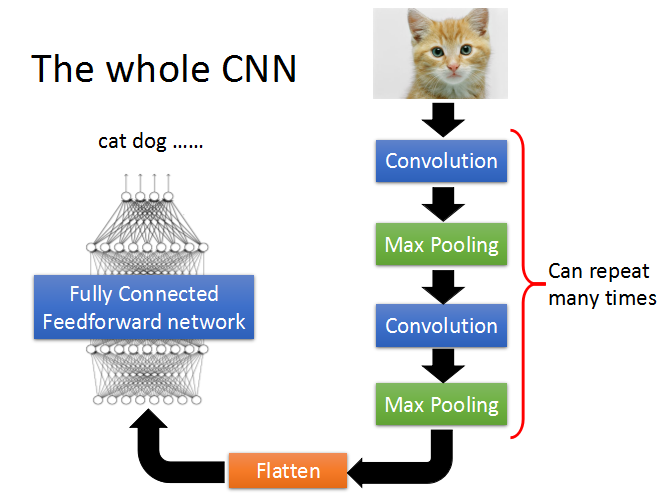
The whole CNN
来看看整个CNN的架构

从图片作为输入开始,经过多层的Convolution层+MaxPooling的组合,然后是Flatten层,最后经过一个Fully Connected network。

其中,上面讨论的关于图片的三个特点,在CNN的不同层中有相应处理。
Property1、2是小的特征和 特征的不同位置,通过Convolution层进行处理;
Property3 Subsampling通过MaxPooling处理。
CNN – Convolution
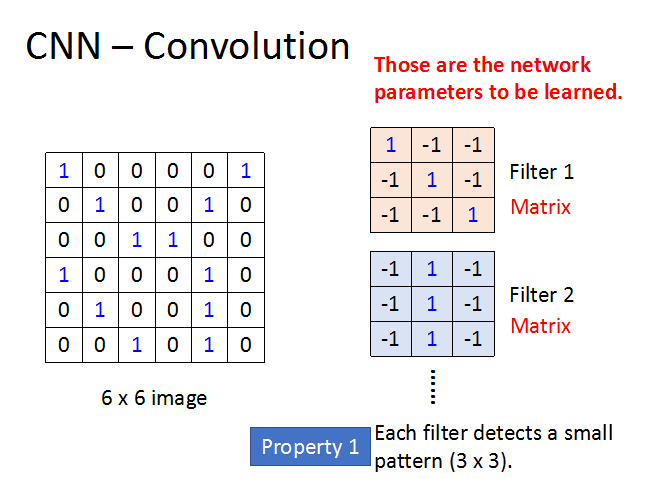
这里需要提到的是Filter。Filter其实就是一个矩阵,它们是神经网络需要学习的参数。
每个Filter在图片中进行扫描,检测3*3的特征。
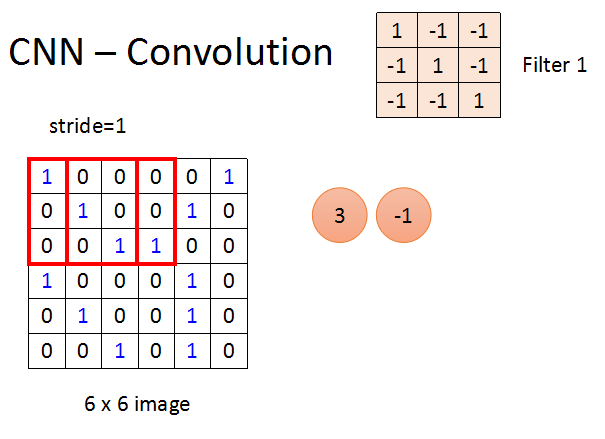
Filter从图片的左上角开始,以stride为步长进行图片扫描,图片中每3*3的子图会和Filter作内积,然后得到一个输出值。
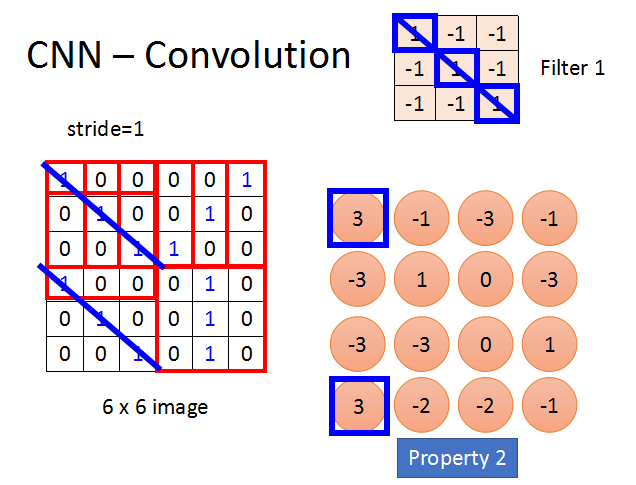
上面就是FIlter1扫描整个6×6图片后得到的4×4的结果矩阵。
可以进一步理解的是,该Filter对角线全为1,表示检测图像是否出现类似的斜线,出现斜线的地方在结果矩阵中的值为最大。
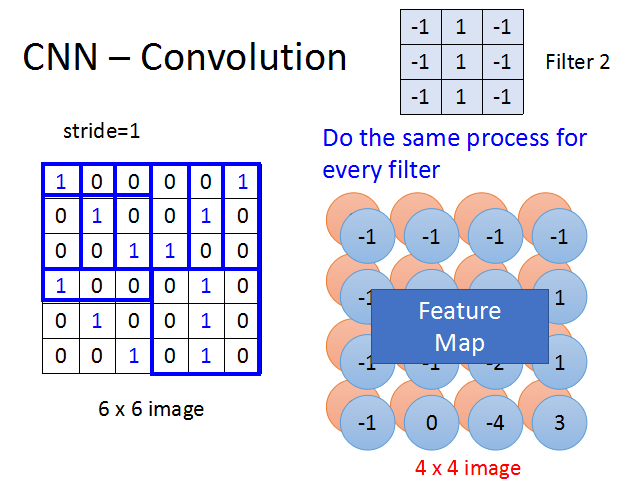
对于一张图片,我们会同时检测很多特征,每个filter只做一件相同的事情,所以需要有很多的Filter,
它们放在一起就叫做Feature Map。
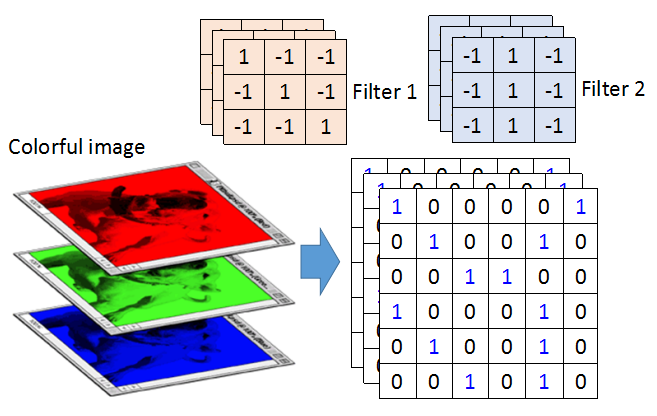
对于彩色图片,一个Filter是3维的,如上图,Filter是3×3×3的立方体(tensor).
下面将Convolution层和Fully Connected连接对应理解。


将图片拉直成一个列向量,上面的Filter连接的是1,2,3,7,8,9,13,14,15的输入单元,而不是全连接,Filter的每一个分量可以看作是全连接网络中的w和b。
这样相比于全连接的网络,就只需要更少的参数。
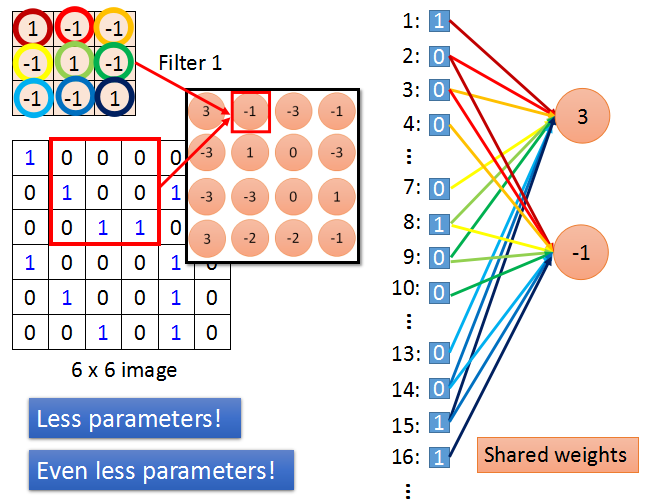
而且,之前讨论过,检测同一个特征只使用相同的Filter,所以每一个neuron共用相同的参数,这就是Shared weights。
这会使CNN的参数变得更少。
CNN – Max Pooling

将每一个Filter检测后的结果,划分成2×2的小块,在每一块中可以取均值或最大值,代替这四个值,这样就实现了Subsampling的功能。
取最大值的方法就是Maxpooling。
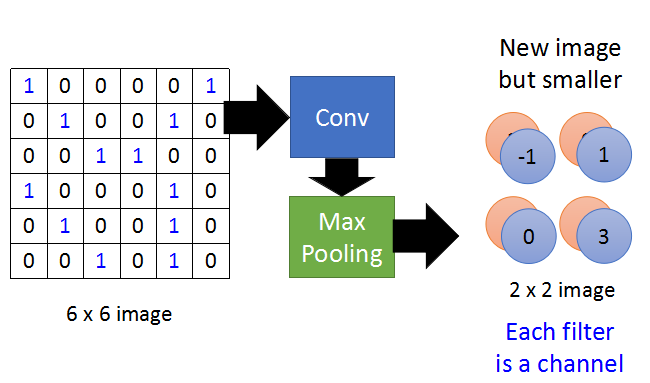
一副图像,经过Conv和Maxpooling后,会变成一幅小的新图像。可以再它之上继续进行Conv和Maxpooling。
经过MaxPooling处理后会产生和Filter数目相同的“新图像”,每一个Filter都可以看作是处理之前图像的一个channel。

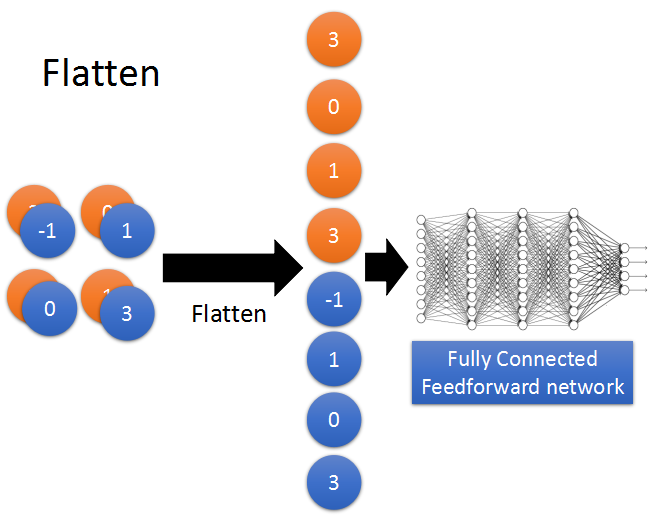
Flatten

最后的Flatten就是将上一层Maxpooling得到的image拉直成列向量,作为全连接网络的输入。
以上就是一个CNN神经网络的所有模块简介。最后附一张全图。