一、计算机里的基础数据类型
就是对计算机系统存储和处理的数据根据计算机的存储特性来进行分类,在计算机的世界里,数据类型就是在数据结构中的定义是一组性质相同的值的集合以及定义在这个值集合上的一组操作的总称。。计算机里的数据有哪些特性呢:首先是数据是用二进制保存,其次是有长度限制,然后才是加上语义上的信息,那么根据这些特征来进行分类,计算机里的基础数据类型包括:字节、字、双字、布尔值、数值、字符等。
1.1、纯二进制数据类型
- 字节(byte)
对就是用二进制的的单位Byte作为了数据类型的名称,表示一个长度为8bit的二进制数据,范围0x00---0xFF,具体语义要根据使用场景来确定。 - 字(word)
也是用二进制的的单位word作为了数据类型的名称,表示一个长度为16bit的二进制数据,范围0x0000---0xFFFF,具体语义要根据使用场景来确定。 - 双字(dword)
也是用二进制的的单位dword作为了数据类型的名称,表示一个长度为32bit的二进制数据,范围0x00000000---0xFFFFFFFF,具体语义要根据使用场景来确定。 - 布尔值(bool)
占用8bit,表达逻辑上的真和假,取值范围(0,1)
这些数据类型通常没有明确的语义,需要在具体的使用场景才有具体的语义,比如我们在Windows系统里编程时,经常用到的一些标识数据,每一个位代表的意思不一样。
1.2、编码数据类型
除了上面的纯二进制数据类型外,还有一些基础数据类型是需要人为编码后,才能被计算机识别和处理的数据,比如数值和字符文本。这类数据在任何情况下它们的语义都是清晰明了唯一的。
1.2.1、数值型
对应了实数里的所有的类型:整数,有理数、无理数。在计算机里,数值根据计算机系统特征分了很多类型。整数包括了:整形、长整形、短整形,实数包括了:单精度浮点型和双精度浮点型。
整数:不包含小数部分的数值型数据,用字母I表示。整型数据只用来表示整数,以二进制形式存储。
- 整形
长度是32bit,有符号的表示范围-2147483648~2147483648,无符号表示的范围0~4294967295 - 长整形
跟整形一样,只是长度是整形2倍,是64bit ,表示的整数范围大很多,有符号的表示范围-9223372036854775808 ~9223372036854775807,无符号表示的范围0~1844674407370955161 - 短整形
跟整形一样,只是长度是整形0.5倍,是16bit ,表示的整数范围小很多,有符号的表示范围-32768~32767,无符号表示的范围0~65535
实数:在计算机系统的发展过程中,曾经提出过多种方法表示实数,但是到目前为止使用最广泛的是浮点表示法。相对于定点数而言,浮点数利用指数使小数点的位置可以根据需要而上下浮动,从而可以灵活地表达更大范围的实数。
- 单精度浮点数
单精度浮点型专指占用32位存储空间的单精度(single-precision )值。单精度在一些处理器上比双精度更快而且只占用双精度一半的空间,但是当值很大或很小的时候,它将变得不精确。当你需要小数部分并且对精度的要求不高时,单精度浮点型的变量是有用的。其数值范围为-3.4E38~3.4E38 - 双精度浮点数
占用64位的存储空间。在一些现代的被优化用来进行高速数学计算的处理器上双精度型实际上比单精度的快。所有超出人类经验的数学函数,如sin( ),cos( ) ,tan()和sqrt( )均返回双精度的值。当你需要保持多次反复迭代的计算的精确性时,或在操作值很大的数字时,双精度型是最好的选择。其可以表示的数字的绝对值范围大约是:1.7E-308~1.7E+308
1.2.2、字符(char)
字符指类字形单位或符号,包括字母、数字、运算符号、标点符号和其他符号,以及一些功能性符号。字符是电子计算机或无线电通信中字母、数字、符号的统称,其是数据结构中最小的数据存取单位,是计算机中经常用到的二进制编码形式,也是计算机中最常用到的信息形式。不同国家、民族和地区都有自己的符号系统,计算机系统要想表达这些符号,就必须对这些符号进行二进制的编码。根据符号编码的不同,字符的长度就不同。计算机常用的就是ASCII码,主要用来表示英文世界的常见符号,一个字符占用8bit长度,而中文字符常用编码是GBK,一个中文字符占用16bit。
----------------手动分割--------------------------
然后我们来解释一下有符号数和无符号数,首先我们要明白有符号和无符号都是针对二进制数来讲的,并且他们都是以补码的方式在计算机中存储的。
即(计算机以二进制补码存储数值,当一个具有符号位的数据值储存在计算机中的时候,计算机会以最高位为符号位,其余位数取该数绝对值的二进制补码来储存。)
有符号性(signed)和无符号型(unsigned)两种(默认如char c1就是默认有符号字符)
有符号数:用最高位最符号位,‘0’代表正数,‘1’代表负数,其余位用作数字位代表数值位。
无符号数:所有位都为数值位,无正负之分,亦无符号位。
那这两者的在实际使用过程种有什么区别呢?主要是符号位,但是在普通的赋值,读写文件和网络字节流都没什么区别,反正就是一个字节,不管最高位是什么,最终的读取结果都一样,只是你怎么理解最高位而已,在屏幕上面的显示可能不一样。但是我们却发现在表示byte时,都用unsigned char,这是为什么呢?首先我们通常意义上理解,byte没有什么符号位之说,更重要的是如果将byte的值赋给int,long等数据类型时,系统会做一些额外的工作。如果是char,那么系统认为最高位是符号位,而int可能是16或者32位,那么会对最高位进行扩展(注意,赋给unsigned int也会扩展)而如果是unsigned char,那么不会扩展。这就是二者的最大区别。
1.3 范围
计算过程:
有符号char范围:(占一个字节即八位 )
有符号char最大值(正数):0111 1111即127,最小值1000 0000(补码) 即-128。
注1000 0000 -1=0111 1111 即2^7-1=128-1=127;
-128即- 2^7;
所以有符号char 取值范围[-128,127];当超过这个取值范围就会溢出。
无符号char取值范围:
无符号最大值即1111 1111 即255,最小值为0;
注:10000 0000 - 1 = 1111 1111即2^8-1即256-1=255;
所以无符号char 取值范围[0,255]。
例如:假设我们现在使用的编译器,把char当做signed来看到,则
char c1;
signed c2;
unsigned c3;
则c1和c2的取值范围都是[-128,127],而c3的取值范围则是[0,255]。
----------------------------------
有符号无符号int取值范围
同理,有符号int 取值范围[- 2^31 , 2^31-1];
无符号int取值范围[ 0,2^32-1]。

但是看一个特殊情况
看下面一道题:
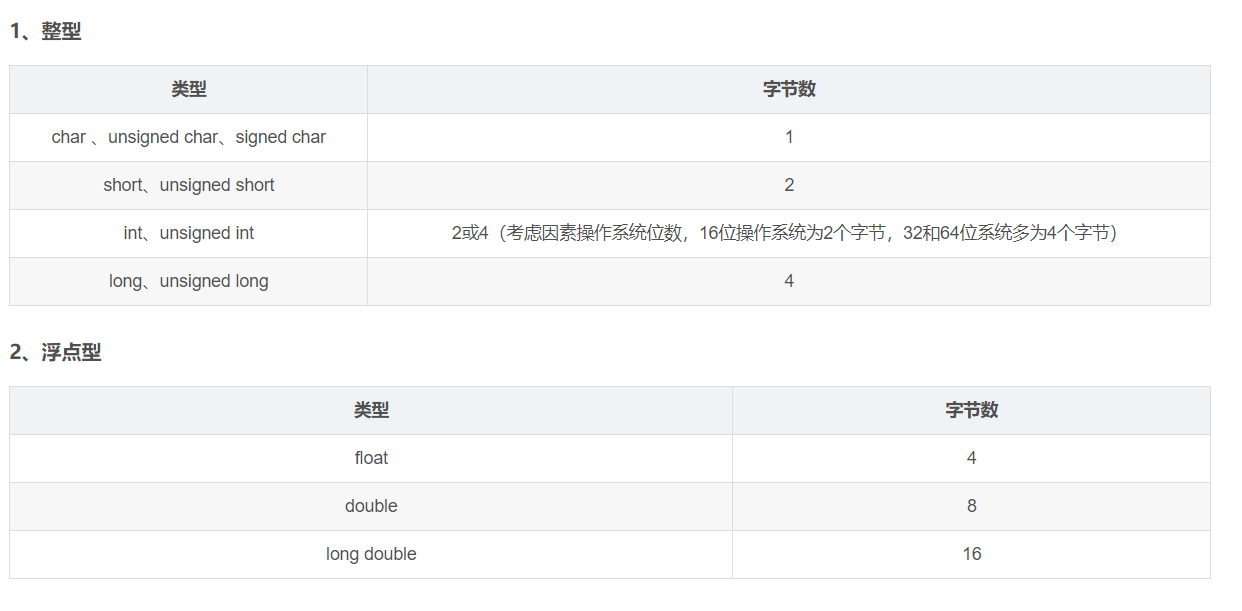
unsigned int i=10; int j=-20; i+j=?

结果计算一下和上面说的有误,那是因为一个知识点忘了
字节数与不同的系统有关
具体字节数可在相应的系统下使用“sizeof(type)”查看
上面的情况是针对16位的情况下的
16位系统时
所以以后写代码定义类型的时候别出错啦!
二.计算机网络
计算机网络-计算机网络是按照网络协议,将地球上分散的、独立的计算机相互连接的集合。连接介质可以是电缆、双绞线、光纤、微波、载波或通信卫星。计算机网络具有共享硬件、软件和数据资源的功能,具有对共享数据资源集中处理及管理和维护的能力。
http:超文本传输协议(Hypertext Transfer Protocol,HTTP)是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应
它可以使浏览器更加高效,使网络传输减少。它不仅保证计算机正确快速地传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等
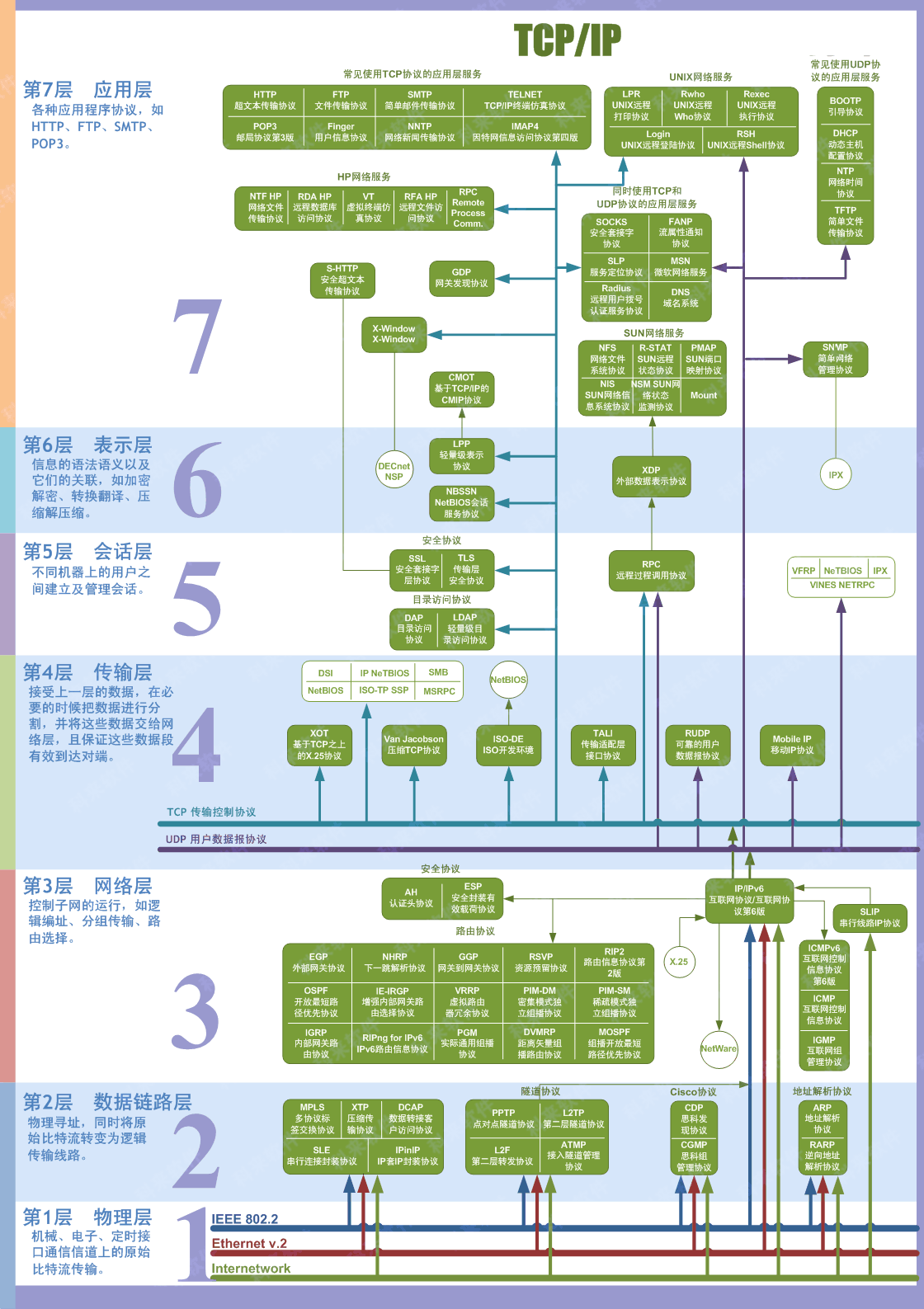
HTTP协议通常承载于TCP协议之上,有时也承载于TLS或SSL协议层之上,这个时候,就成了我们常说的HTTPS。如下图所示:
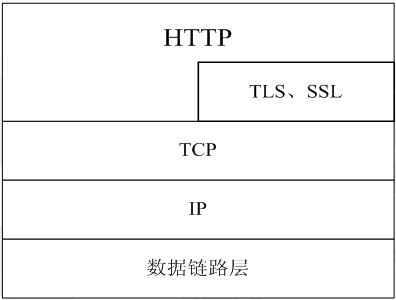
一次HTTP请求的整个过程来讲解:HTTP起源、TCP/IP协议、建立TCP连接、客户端请求、服务端响应、断开TCP连接
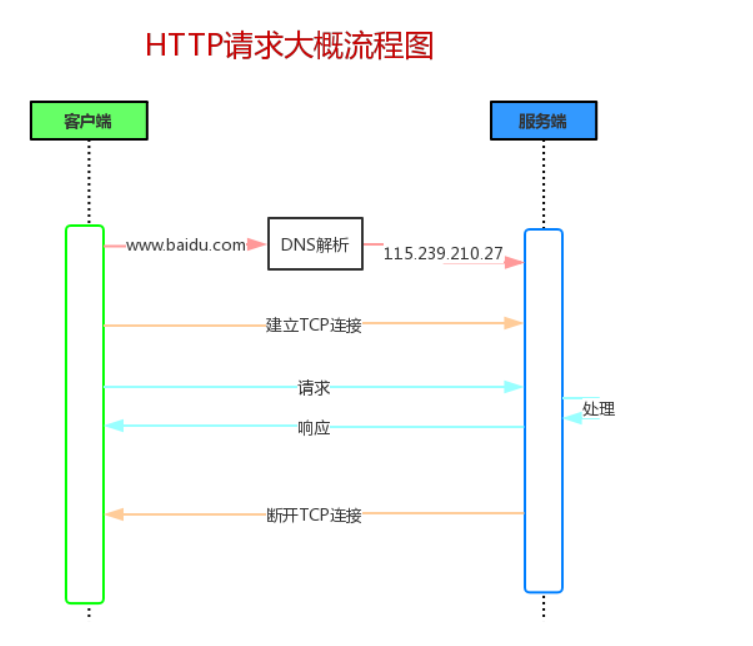
所以如图所示,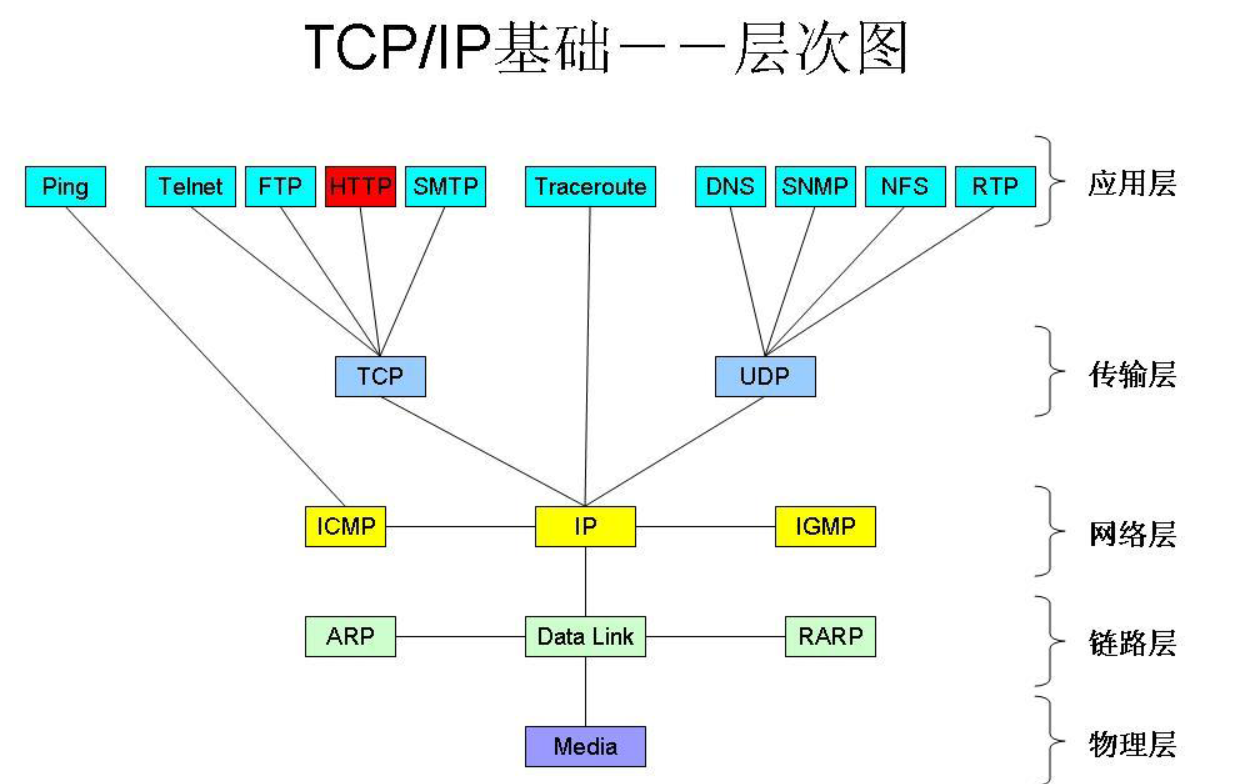
从上图我们可以清晰的看到HTTP使用的传输层协议为TCP协议,而网络层使用的是IP协议(当然还使用了很多其他协议),所以说HTTP是一个基于TCP/IP协议簇来传递数据。
同样我们可以看到ping走的ICMP协议,这也就是为什么有时候我们开vps可以上网,但是ping google却ping不通的原因,因为走的是不同的协议。
既然http在tcp之上,那么接下来看下tcp
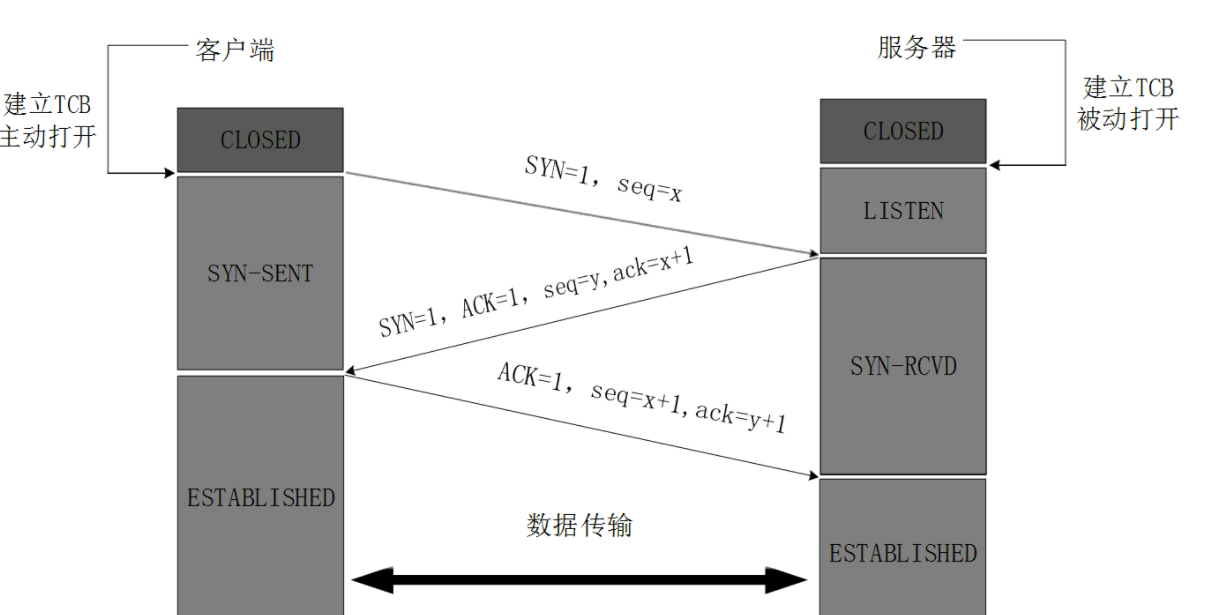
说到tcp那肯定是首先想到了三次握手四次挥手
三次握手:
第一次:
客户端 - - > 服务器 此时服务器知道了客户端要建立连接了
第二次:
客户端 < - - 服务器 此时客户端知道服务器收到连接请求了
第三次:
客户端 - - > 服务器 此时服务器知道客户端收到了自己的回应
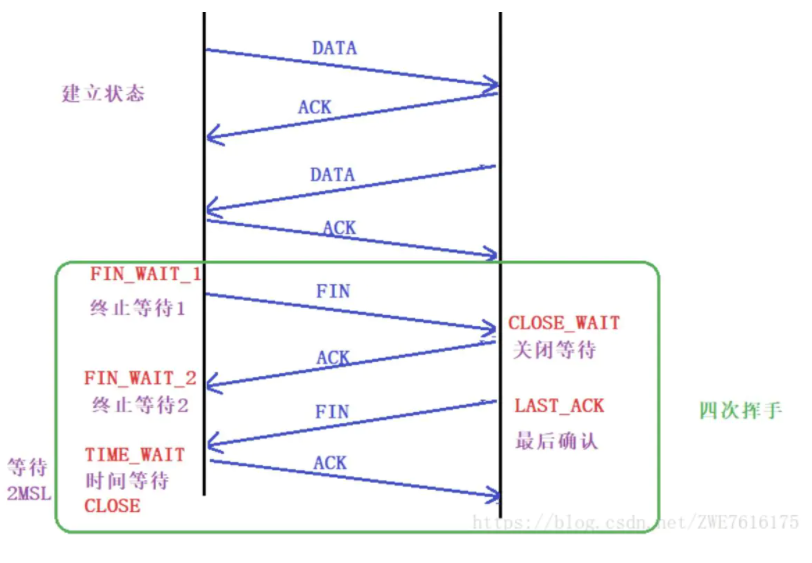
四次挥手:
TCP服务端建立步骤:
- 申请套接字:s = socket(…);
- 确定本地端点,填写端点地址:address = …;
- 建立套接字与端点关系(绑定):bind(s,address…);
- 设置为监听模式:listen(s);
- 接收连接:newsock = accept(s);
- 数据收/发:recv(newsock); / send(newsock);
- 关闭套接字:closesocket(newsock);
- 申请套接字:s = socket(…);
- 确定本地端点,填写端点地址:c_address = …;
- 建立套接字与端点关系(绑定):bind(s,c_address…);
- 确定服务器端点:s_address = …;
- 与服务器建立连接:connect(s,s_address…);
- 数据发/收:send(s); / recv(s);
- 关闭套接字:closesocket(s);
三.数据结构
c语言经典教学:http://data.biancheng.net/
一些其他教程:
线性表:https://blog.csdn.net/earthOLtainanwan/article/details/86652581
栈:https://blog.csdn.net/ScottWei_007/article/details/88596866
队列:https://blog.csdn.net/lym152898/article/details/52202606
四.操作系统
https://www.cnblogs.com/jin-xin/articles/10078845.html
精简的说的话,操作系统就是一个协调、管理和控制计算机硬件资源和软件资源的控制程序。操作系统所处的位置如图
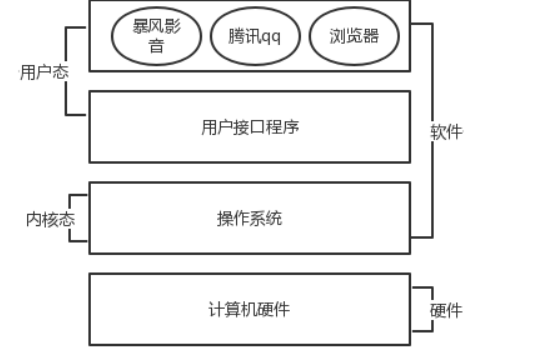
操作系统应该分成两部分功能:
#一:隐藏了丑陋的硬件调用接口(键盘、鼠标、音箱等等怎么实现的,就不需要你管了),为应用程序员提供调用硬件资源的更好,更简单,更清晰的模型(系统调用接口)。
应用程序员有了这些接口后,就不用再考虑操作硬件的细节,专心开发自己的应用程序即可。
例如:操作系统提供了文件这个抽象概念,对文件的操作就是对磁盘的操作,有了文件我们无需再去考虑关于磁盘的读写控制(比如控制磁盘转动,移动磁头读写数据等细节),
#二:将应用程序对硬件资源的竞态请求变得有序化
例如:很多应用软件其实是共享一套计算机硬件,比方说有可能有三个应用程序同时需要申请打印机来输出内容,那么a程序竞争到了打印机资源就打印,
然后可能是b竞争到打印机资源,也可能是c,这就导致了无序,打印机可能打印一段a的内容然后又去打印c...,操作系统的一个功能就是将这种无序变得有序。
操作系统虚拟机为用户提供了一种简单、清晰、易用、高效的计算机模型。虚拟机的每种资源都是物力资源通过复用、虚拟和抽象而得到的产物。

死锁:https://blog.csdn.net/hd12370/article/details/82814348