字符:各种文字和符号的总称,包括各个国家文字、标点符号、图形符号、数字等。
字符集:是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见字符集有:ASCII字符集、GB2312字符集、Unicode字符集等。
使用哪些字符,字母和符号会被收入标准中。不同字符集中包含的字符个数不同。
编码字符集:计算机要准确的处理各种字符集文字,需要进行字符编码,以便计算机能够识别和存储各种文字。
字符集只是字符的集合,不一定适合作网络传送、处理,有时须经编码后才能应用。在一个字库表中,每一个字符都有一个对应的二进制地址,而编码字符集就是这些地址的集合。
规定每个“字符”分别用一个字节还是多个字节存储,用哪些字节来存储,这个规定就叫做“编码”。
编码:我们可以选用任意类型的编码方式将字符转换成一串二进制数,这个过程就是编码,我们也可以称之为加密过程,无论使用哪一种编码方式进行编码,最终都是产生计算机
可识别的二进制数,但如果编码规范的字库表不包含目标字符,则无法在编码字符集中找到对应的二进制数。这将导致不可逆的乱码!例如:像ISO-8859-1的字库表中不包含中文,
因此哪怕将中文字符使用ISO-8859-1进行编码,再使用ISO-8859-1进行解码,也无法显示出正确的中文字符。
解码:一串二进制数,使用一种编码方式,转换成字符,这个过程我们称之为解码。就像解开密码一样,程序员可以选用任意的编码方式进行解码,但往往只有一种编码方式可以
解开密码显示出正确的文字,而使用错误的编码方式,产生其他不合理的字符,这就是我们通常说的————乱码!

F2类似于F1的反函数,不同F会有不同的字符集,比如ASCII就无法编码中文,因为中文不在它的字符集内,不同的F编码出来的二进制也不同。
一个字符可以属于多个字符集,故也可以采用多种编码方式,即多种F1。但一个二进制通常对应一种解码方式。
1. ASCII编码
ASCII码,是最早产生的编码规范,字符集一共包含00000000~01111111共128个字符,可以表示阿拉伯数字和大小写英文字母,以及一些简单的符号。
可以看出ASCII码只需要1个字节的存储空间,最高位为0。ASCII字符集中的字符数量有限,不支持编码中文。
2. GBK编码
GBK全称《汉字内码扩展规范》,GBK字符集中所有字符占2个字节,不论中文英文都是2个字节。没有特殊的编码方式,习惯称呼GBK编码。一般在国内,汉字较多时使用。
不然将占用大量空间。
3. Unicode编码
a. 由于各种编码规范互不兼容,且只能表示自己需要的字符,于是,国际标准化组织(ISO)决定制定一套全世界通用的编码规范,这就是Unicode。
b. Unicode 是一本很厚的字典,记录着世界上所有字符对应的一个数字,Unicode 给所有的字符指定了一个数字用来表示该字符。
c. 和 ascii 一样,unicode编码的字符串只是存储每个字符的码点(编号),即存储的是码点序列。
d. Unicode 没有规定字符对应的码点序列如何存储。以汉字“汉”为例,它的 Unicode 码点是 0x6c49,对应的二进制数是 110110001001001,二进制数有 15 位,
这也就说明了它至少需要 2 个字节来表示。可以想象,在 Unicode 字典中往后的字符可能就需要 3 个字节或者 4 个字节,甚至更多字节来表示了。
这就导致了一些问题,计算机怎么知道你这 2 个字节表示的是一个字符,而不是分别表示两个字符呢?这里我们可能会想到,那就取个最大的,假如 Unicode 中
最大的字符用 4 字节就可以表示了,那么我们就将所有的字符都用 4 个字节来表示,不够的就往前面补 0。这样确实可以解决编码问题,但是却造成了空间的极大浪费,
如果是一个英文文档,那文件大小就大出了 3 倍,这显然是无法接受的。
于是,程序员就设计了几种可变长度的字符编码方式,比如:UTF-8,UTF-16,UTF-32。
最广为程序员使用的就是UTF-8,UTF-8是一种变长字符编码,注意:UTF-8不是编码规范(ASCII,GBK,Unicode等都是编码规范),而是编码方式。
我为大家介绍一下UTF-8的编码规则。
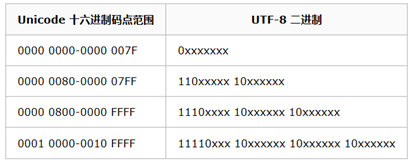
1)对于只需要1个字节的字符,UTF-8采用ASCII码的编码方式,最高位补0来表示。
2)而对于n个字节的字符(n>1),即大于一个字节的字符,采用第一个字节前n位补1。第n+1位填0,后面字节的前两位一律设为10。
剩下的没有提及的二进制位,全部为这个符号的unicode码。
例如:汉字严的Unicode码是4E25转换成二进制就是01001110 00100101共15位,根据上表可知使用UTF-8字符编码后占3个字节(因为如果只用两个字节,剩余位就11位)。
因此前3位是1,第4位(n+1位)是0,后面两个字节中每个字节的前两位都是10,即1110 xxxx 10 xxxxxx 10xxxxxx。填充进去后就变成了1110 0100 10 111000 10 100101
共计24位占3个字节。
由此可见,英文在UTF-8字符编码后只占1个字节,中文占了3个字节。
虽然UTF-8编码没有GBK编码占的空间小,但他胜在面向全世界,至于使用哪一种编码还是取决于具体的使用环境。
------------------------------------------------------------------------分割线------------------------------------------------------------------------
在编程过程中,有三个地方都涉及到编码方式:源码编码方式(.py文件的字符集),执行编码方式,运行环境编码方式。
源码字符集:the source character set,是指源代码文件是使用何种编码字符集保存的。
执行字符集:the execution character set,是指源代码经过编译、链接后的可执行文件是使用何种编码字符集保存的,程序实际执行时,内存中的字符串编码就是执行字符集。
运行环境编码:是指操作系统(或者当前控制台环境)用于显示文字的编码字符集。
所以程序编译执行这一过程需要经过两次解码:
-
编译器在编译源代码时,会将源码字符集转化为执行字符集,如果编译器不能正确识别源码字符集,就得不到正确的字符串数据。
-
可执行文件在实际运行环境中执行时,为了在控制台(或者其他UI)上显示出字符串,就要将执行字符集转化为运行环境的字符集。如果两者编码方式不同,即导致乱码。
# -*- coding:utf-8 -*-
s = "这是一段中文"
s.decode("utf-8").encode("GBK") # 这句不理解可以先看下面内容
print(s) # 显示乱码,原因应该是运行环境编码不是 gbk
现在来解释下python中的第二行代码:
# -*- coding:utf-8 -*-
这一行是为了告诉 Python 解释器,按照 UTF-8 编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。先解码后,再编码为执行字符集。
Python2中默认的执行编码格式是 ASCII 格式,而python3,默认的编码方式就是 utf-8, 所以也就不用加这一行了。
申明了 UTF-8 编码并不意味着你的.py 文件就是 UTF-8 编码的,必须并且要确保文本编辑器正在使用 UTF-8 without BOM 编码。
如果.py文件本身使用UTF-8编码,并且也申明了# -*- coding: utf-8 -*-,打开命令提示符测试就可以正常显示中文
如果源文件是gbk格式,但是开头xxx为utf-8,那么python解释器将会以utf-8编码读取gbk格式的文件,严重时将会导致错误。
所以,一定要保证xxx和源文件的编码方式一致,即执行编码方式和源码编码方式一致。

------------------------------------------------------------------------分割线------------------------------------------------------------------------
理解了上述内容之后,接下来详述一下python内部字符串的一些问题。
先介绍python的两个方法:
1)str.encode(encoding="utf-8"): Return an encoded version of the string as a bytes object.
2)bytes.decode(encoding="utf-8"): Return a string decoded from the given bytes.
python解释器按默认或者指定的编码方式来解析源代码文件,当然也包括表示所有的字符串。
字符串和字节串是不一样的:Unicode才是真正的字符串,而用ASCII、UTF-8、GBK等字符编码表示的是字节串。
怎么理解呢?由第一部分的内容可知,如果没有utf-8/16/32这些编码方法,unicode每个字符会占四个字节,对于一串unicode的字节序列,就不会再
等同于其它字节序列,比如求长度,对unicode串求长度会是字符串的长度(内部将字节长度除以4),而对其它字节串求长度则是字节数。
a. 我们先来看下python2中的字符串。需要在字符串前面显示地加上u才能表示unicode字符串,即python2中的str类型其实只是字节串。
在 python2 中将一个字符串decode后得到的便是unicode字符串(真正的字符串)。
# Python2
a = 'Hello,中国' # 字节串,长度为字节个数 = len('Hello,') + len('中国') = 6 + 2 * 2 = 10
b = u'Hello,中国' # 字符串,长度为字符个数 = len('Hello,') + len('中国') = 6 + 2 = 8
print(type(a), len(a))
print(type(b), len(b))
"""
output:
(<type 'str'>, 10)
(<type 'unicode'>, 8)
"""
b. Python3中对字符串支持的改进,不仅仅是更改了默认编码,而是重新进行了字符串的实现,而且它已经实现了对 unicode 的内置支持。
可以认为Python3中的str和unicode合二为一了。此时str类型其实就是unicode类型。
a = '你好'
b = u'你好'
c = '你好'.encode('gbk')
print(type(a), len(a))
print(type(b), len(b))
print(type(c), len(c))
"""
output:
<class 'str'> 2
<class 'str'> 2
<class 'bytes'> 4
"""
unicode 字符串可以与任意字符编码的字节进行相互转换,我们也是基于这一点来做字节串的转换。
# python2
#-*- coding:utf-8 -*-
utf_8_a = '我爱中国' # 指定utf-8,则字符串是 utf-8 字节串
gbk_a = utf_8_a.decode('utf-8').encode('gbk')
print(gbk_a.decode('gbk'))
# 在 python2 中我们将 utf-8 的字符串直接 encode 成 gbk 编码的字节串,也会在 encode() 函数调用前先隐
# 式的以默认方式(即使指定了utf-8)调用 decode()。但由于 python2 的默认执行编码方式为 ascii,decode() 调
# 用时默认传递的参数也规定为 ascii,所以将导致解码失败(以ascii字符集来解码utf-8导致的失败),下一步编码
# 也就无法进行。要想成功,必须通过显示调用str.decode("utf-8").encode("gbk"),显示指定解码。
str = "你好"
print(str.encode("gbk")) # 报错,相当于 str.decode("ascii").encode("gbk")
"""
output:
我爱中国
"""
#------------------------------------------------------------------------------------------------------------
# python3
utf_8_a = '我爱中国'
gbk_a = utf_8_a.encode('gbk') # Python3中定义的字符串默认就是unicode,因此不需要先解码,可以直接编码成新的字符编码
print(gbk_a.decode('gbk'))
"""
output:
我爱中国
"""