应用kernels来进行非线性分类
非线性分类:是否存在好的features的选择(而不是多项式)--f1,f2,f3....

上图是一个非线性分类的问题,前面讲过,我们可以应用多项式(features)来构造hypothesis来解决复杂的非线性分类问题。
我们将x1,x2,x1x2.....替换成f1,f2,f3......,那么是否有更好的features的选择呢(而不是这些多项式做为features),因为我们知道以这些多项式做为features,次数较高,计算较复杂.
使用Kernel(核函数)来计算新的features

假设现在我们有三个features: x0,x1,x2;我们选择三个标识点(landmarks l(1),l(2),l(3)),通过相似度函数,也称为核函数来计算x与三个标识点之间的相似度
这儿我们使用的核函数是Gaussian(高斯)kernels,核函数有很多种,这儿我们只是选取了其中的一种
核函数也记为小写k(x,l(i)),将旧的features(x0,x1,x2)通过核函数与标识点(landmarks)映射成新的features---f1,f2,f3
Kernels是怎么度量这种相似度的
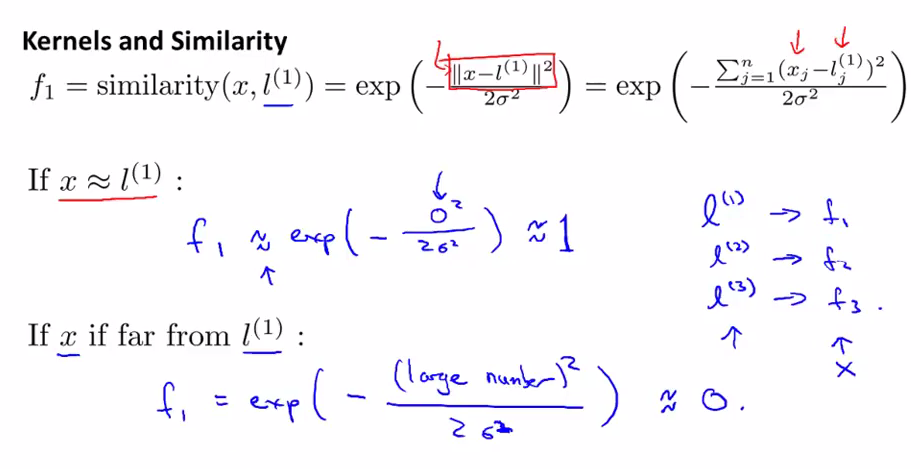
在这个例子中,我们忽略了x0(截距),因为x0总是等于1.
由上面的公式可以看出,当x与我们的一个landmark很近时,它们之间的欧式距离约等于0,这时高斯核函数的值约为1(可以理解为与这个landmark相似)
当x与我们的landmark相距很远时,它们之间的欧式距离很大,这时高斯核函数的值约为0(可以理解为与这个landmark不相似)
这样我们通过三个landmarks(l(1),l(2),l(3))来生成三个新的features: f1,f2,f3.这三个features分别用来度量样本点是否与这三个landmarks是否相似(1/0)
画图来看核函数(与landmarks的相似度)
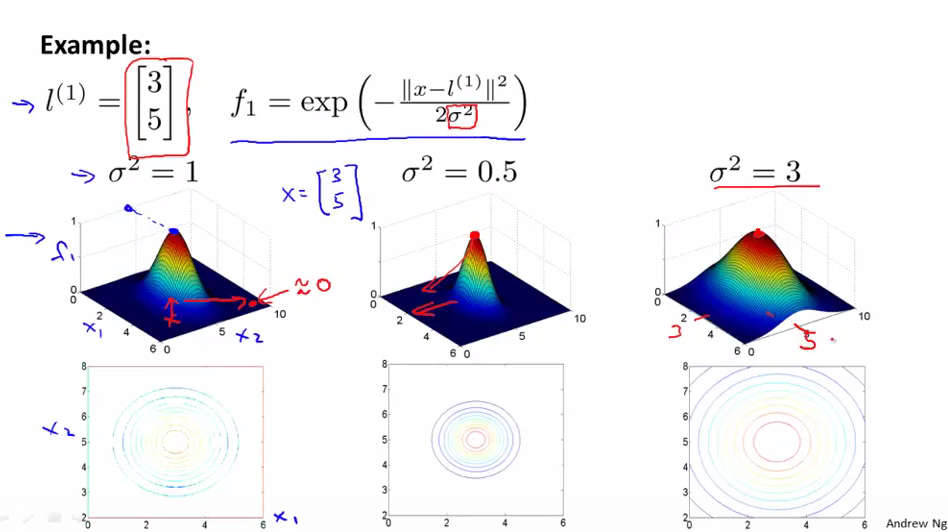
假如现在我们的一个landmark为(3,5),σ2=1,则左边为f1的图,可以看到当x=(3,5)时(即与landmark相等时),f1的值达到最大=1,随着x离(3,5)越来越远,f1的值下降,直到为0(即相距很远)。下面的那个图为上面的图的等值线。
σ2为高斯核函数的parameter(参数),它可以用来调整下降的速度。如当σ2=0.5时,图像会更陡,说明下降上升得越快;当σ2=3时,图像会更平缓,说明下降上升得越慢。
使用了新的features(利用kernel函数)后如何进行预测(画出非线性decision boundary)
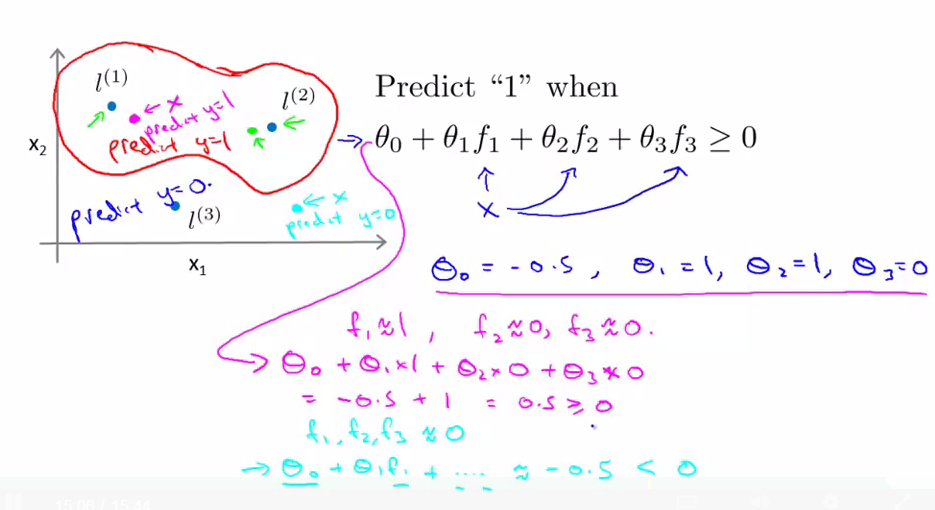
在SVM中的hypothesis是直接对结果进行预测,如上图所示,当θTx>=0时,hypothesis = 1;
利用某种学习算法求得了它的parameters(θ),分别为θ0=-0.5,θ1=1,θ2=1,θ3=0
当我的x(trainning/crossvalidation/test data)距离landmark1(l1)很近时,这时hypothesis=0.5>0,预测值为1;
当我的x(trainning/crossvalidation/test data)距离landmark2(l2)很近时,这时hypothesis=0.5>0,预测值为1;
当我的x(trainning/crossvalidation/test data)距离landmark1(l1)和landmark2(l2)都很远时,这时hypothesis=-0.5<0,预测值为0;
这样我们就可以画出decision boundary大致如上图所示,在红色框里面的点,预测值为1;在框外的点,预测值为0;这样我们就画出了一个非线性的决策边界
那么我们如何选择landmarks呢?以及除了高斯核函数外有其它的核函数吗?---之后会提到
总结
- Kernel(核函数)是用来计算新的features的,从而避免在非线性较复杂的问题时直接使用多项式来做为features(使用多项式计算较复杂)
- 高斯核函数通过x与landmarks的距离远近来度量这种相似度(越近表明越相似越接近于1,越远表明越不相似,越接近于0),取值范围在0-1之间。这样就映射出了新的features(这种features表明与landmarks的相似的度量)