在 https://www.cnblogs.com/xyzyj/p/6696545.html 中简单介绍了List和Map中的常用集合,唯独没有CurrentHashMap。原因是CurrentHashMap太复杂了,于是新开一篇,将在这里将隆重介绍。
在java中,hashMap 和hashTable 与 currentHashMap 的关系比较密切,所以LZ在这多啰嗦一下,从hashMap,hashTable说起,再逐渐过渡到CurrentHashMap,以便于读者更能清晰地理解它的来龙去脉。
1.hashMap(JDK 1.7)
1.1 hashMap的数据结构图
大家都知道hashmap的数据结构是由数组+链表实现的,如图:
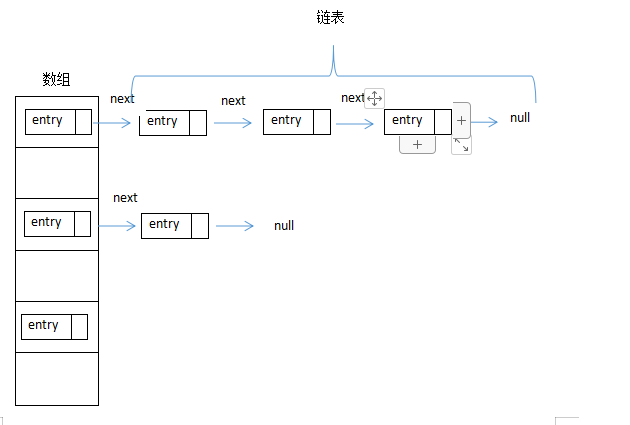
HashMap默认的初始化容量是16,默认加载因子是0.75。扩容就是把一原map结构中的数据一一取出来放在一个更大的map结构中,在操作链表时使用的是头插法。在单线程时,扩容是没有问题的,但是在多线程下,会发生线程安全问题。
1.2 HashMap扩容分析
扩容源码如下:
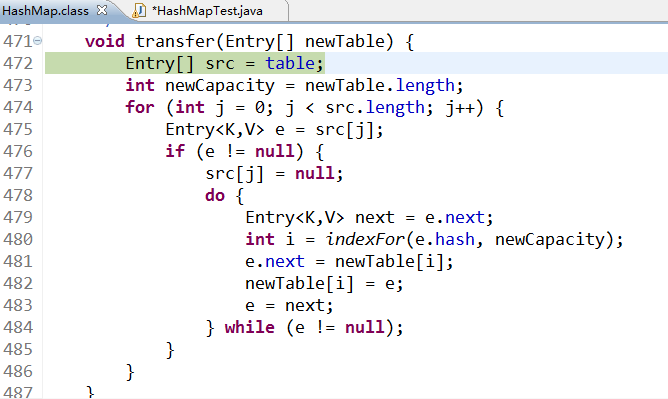
void transfer(Entry[] newTable) { Entry[] src = table; int newCapacity = newTable.length; for (int j = 0; j < src.length; j++) { Entry<K,V> e = src[j]; if (e != null) { src[j] = null; do { Entry<K,V> next = e.next; int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next; } while (e != null); } } }
其中最主要的是红色部分,把这几句代码摘出来,标上序号,方便后文引用,看下执行过程中会发生什么?
Entry<K,V> next = e.next; ① e.next = newTable[i]; ② newTable[i] = e; ③ e = next; ④
具体过程举一个例子:
单线程情况下的扩容情况:
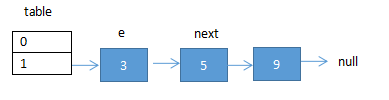
这是一个大小为2的map结构,其中在下标为1的数组上挂了一个长度为3的链表,链表中的3个key分别为 3,5,9 。而这三个key都是 mod(2) 以后放在链表中的。造成一个链过程。此时e节点指向了3,next节点指向了e的下一个节点 5 ,现在要将此map扩容,则将mod(2)变成mode(4)。单线程执行步骤如下:
(1)执行代码①②后结果:e指向了新map的3 ,e的next为空。
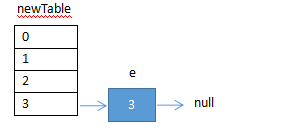
(2)循环执行代码④①后的结果:e指向5,next执行9
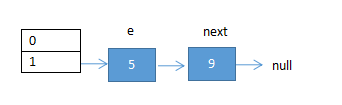
(3)继续循环执行,链表使用头插法,最终的结果如下:e指向了5,next指向了null,5和9的顺序发生了反转,和扩容完毕。
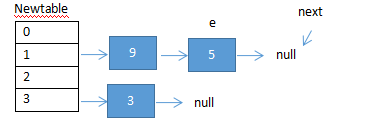
在多线程下的扩容情况:
同样是上面的map结构。有两个线程A和线程B进行扩容,
(1)线程A执行代码①后挂起。此时线程A的指针情况如上图,e指向3,next指向5。
(2)此时线程B执行扩容,直至线程B扩容完毕,新的map结构如单线程中的执行结果:
在这个时候,线程A开始执行,但线程A的指针还是挂起之前的状态,为了方便标识,下面用红色标识A线程,用绿色标识B线程。
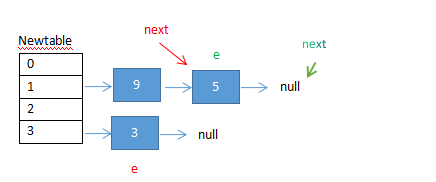
如上图,线程A在挂起之前e指向3,next,指向5,并且这两个节点在原map上,当A挂起后,就像睡了一觉,这是线程B将原map结构上的节点复制到了新的mao结构上,当A醒来之后,它的e和next执行节点没变,但是节点的位置发生了变化,已经在新的map上了,因此会出现上图现象,此时A开始扩容:
(3)A执行②③代码,情况和上图一样,没有变化,依然是将3节点放在newtable[3]上。
(4)A循环执行④①代码,情况如下;
e = next; ④ (3)执行完后的情况如上图,A的next执行 5,所以执行完这行代码后,e指向5。
next = e.next;① 执行完代码④后,e指向了5,而在e挂起之前,5的next指向了9,此时e的next为9,next = e.next = 9。
(5)A在执行②③代码后的情况如下:
e.next = newTable[i]; ② 此时e指向5,i等于1,e.next指向9 (线程B扩完容,9的next指向了5)
newTable[i] = e; ③ 此时,新table[1]指向e,即5
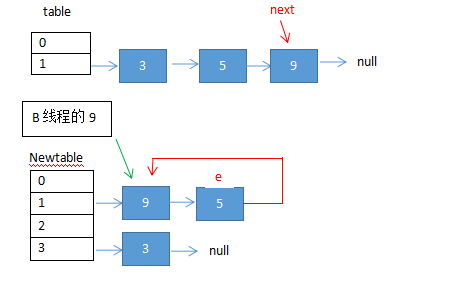
此时出现了环形循环,即死循环。。。
1.3 HashMap扩容时机
从上面知道了HashMap扩容原理,那么hashMap到底是什么时候扩容的呢?
上面提到过,HashMap默认的初始化容量是16,默认加载因子是0.75,什么意思呢?就是16*0.75 = 12,即当向hashMap中通过put()方法存入的数据大于12个的时候就会扩容,扩容后的容量为 16*2 = 32 ,举个简单的例子。
public static void main(String[] args) { Map map = new HashMap<Integer, Integer>(); for(int i = 0;i < 12;i++){ map.put(i, i+1); } }
这是一个很简单的put()操作,然后在扩容源码上打上断点,debug执行完成,没有任何拦截,过程不再演示,下面将for循环中的条件改成 i < 13,debug当put第13个键值对的时候,如下图:
从上图可知,当put的键值对大于12的时候就会进行扩容。
2.hashMap(JDK 1.8)
在1.8中,对hashmap做了优化,在1.7中,有个很容易发生的问题,就是当发生hash冲突的概率比较高时,数组上的某个链表上的数据就会比较多,而其他链表上数据比较少,某个链表将变的非常长,导致查询效率降低。于是,在1.8中,当某个链表上的键值对个数达到8个时,就会将此链表转化为红黑树,我们知道,红黑树的查询效率非常高,主要是用它来存储有序的数据,它的时间复杂度是O(lgn),java集合中的TreeSet和TreeMap以及linux虚拟内存管理就是用红黑树实现的。关于红黑树,这里不再介绍,可以参阅 http://www.360doc.com/content/18/0904/19/25944647_783893127.shtml 。下面看看hashmap的源码。
put()方法源码:
1 /** 2 * Implements Map.put and related methods 3 * 4 * @param hash hash for key 5 * @param key the key 6 * @param value the value to put 7 * @param onlyIfAbsent if true, don't change existing value 8 * @param evict if false, the table is in creation mode. 9 * @return previous value, or null if none 10 */ 11 final V putVal(int hash, K key, V value, boolean onlyIfAbsent, 12 boolean evict) { 13 Node<K,V>[] tab; Node<K,V> p; int n, i; 14 if ((tab = table) == null || (n = tab.length) == 0) 15 n = (tab = resize()).length; 16 if ((p = tab[i = (n - 1) & hash]) == null) 17 tab[i] = newNode(hash, key, value, null); 18 else { 19 Node<K,V> e; K k; 20 if (p.hash == hash && 21 ((k = p.key) == key || (key != null && key.equals(k)))) 22 e = p; 23 else if (p instanceof TreeNode) 24 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); 25 else { 26 for (int binCount = 0; ; ++binCount) { 27 if ((e = p.next) == null) { 28 p.next = newNode(hash, key, value, null); 29 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st 30 treeifyBin(tab, hash); 31 break; 32 } 33 if (e.hash == hash && 34 ((k = e.key) == key || (key != null && key.equals(k)))) 35 break; 36 p = e; 37 } 38 } 39 if (e != null) { // existing mapping for key 40 V oldValue = e.value; 41 if (!onlyIfAbsent || oldValue == null) 42 e.value = value; 43 afterNodeAccess(e); 44 return oldValue; 45 } 46 } 47 ++modCount; 48 if (++size > threshold) 49 resize(); 50 afterNodeInsertion(evict); 51 return null; 52 }
其中红色部分就是当链表上的键值对大于8时,将链表转化为红黑树。TREEIFY_THRESHOLD 的初始化值为8。
3.hashtable是线程安全且效率低的
hashTable其实和hashMap原理相似(1.7,1.8),不同点有四个:
(1).hashTable是线程安全而 HashMap不是线程安全的。 (2).HashTable不允许key和value为null 而 HashMap允许。 (3).hashtable初始化大小为11,默认加载因子为0.75,扩容后容量是原来的2倍+1,而hashMap初始化容量大小为16,默认加载因子为0.75,
扩容后的容量是原来的2倍。
(4).hashtable计算hash是直接使用key的hashcode对table数组的长度直接进行取模,hashmap计算hash对key的hashcode进行了二次hash,
以获得更好的散列值,然后对table数组长度取摸
实现线程安全的方法则是使用synchronized关键字,下面看下hashtable部分源码:
public synchronized int size() { return count; } public synchronized V put(K key, V value) { // Make sure the value is not null if (value == null) { throw new NullPointerException(); } // Makes sure the key is not already in the hashtable. Entry tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { V old = e.value; e.value = value; return old; } } modCount++; if (count >= threshold) { // Rehash the table if the threshold is exceeded rehash(); tab = table; index = (hash & 0x7FFFFFFF) % tab.length; } // Creates the new entry. Entry<K,V> e = tab[index]; tab[index] = new Entry<K,V>(hash, key, value, e); count++; return null; }
可以看出,在源码中,在很多方法汇总都插入了synchronized关键在保证同步,因此,在扩容时,不会出现多个线程同一时间间隔内扩容,所以不会出现死循环。在LZ上篇文中(https://www.cnblogs.com/xyzyj/p/11148497.html)已经详细介绍了synchronized,它一次只允许一个线程执行锁中的代码,故而,hashtable是线程安全且效率低的。
HashMap中只有一条记录可以是一个空的key,但任意数量的条目可以是空的value。如果在表中没有发现搜索键,或者如果发现了搜索键,但它是一个空的值,那么get()将返回null。如果有必要,用containKey()方法来区别这两种情况。
为什么HashTable和ConcurrentHashMap都不允许key和value为null 而 HashMap允许?
网上找到的答案是这样的:ConcurrentHashmap和Hashtable都是支持并发的,这样会有一个问题,当你通过get(k)获取对应的value时,如果获取到的是null时,你无法判断,它是put(k,v)的时候value为null,还是这个key从来没有做过映射。HashMap是非并发的,可以通过contains(key)来做这个判断。而支持并发的Map在调用m.contains(key)和m.get(key),m可能已经不同了。
4.优秀的ConcurrentHashMap
在涉及到Java多线程开发时,如果我们使用HashMap可能会导致死锁问题,使用HashTable效率又不高。而ConcurrentHashMap既可以保持同步也可以提高并发效率,所以这个时候ConcurrentHashmap是我们最好的选择。
CurrentHashMap底层是一个复杂的数据结构,先看图。
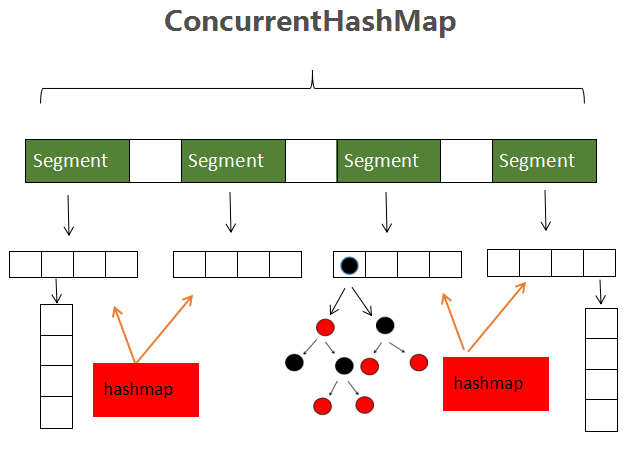
上图就是ConcurrenthashMap(1.8)的数据结构图,它是由Segment数组和hashMap组成的。其中每一个Segment都对应一个hashmap,由Segment,在jdk1.7中,ConcurrentHashMap使用的hashmap是jdk1.7中的hashMap,在jdk1.8中,ConcurrentHashMap使用的HashMap是jdk1.8中的hashMap,其原理类似,且Jdk1.7中的hashMap上文已经做过介绍,故,在此只介绍1,8中的ConcurrentHashMap。
ConcurrentHashMap的优点是使用了Segment数组,Segment数组的每一个元素对用一个hashmap。Segment继承了ReentrantLock ,使用ReentrantLock 对数组某些元素加锁,即只对部分hashMap加锁,从而实现了只对需要加锁的的某一段数进行加锁,实现了多线程并发的操作,这种加锁方式就是分段锁。
Segment继承了ReentrantLock的源码如下:
/** * Stripped-down version of helper class used in previous version, * declared for the sake of serialization compatibility */ static class Segment<K,V> extends ReentrantLock implements Serializable { private static final long serialVersionUID = 2249069246763182397L; final float loadFactor; Segment(float lf) { this.loadFactor = lf; } }
一些默认的参数:
/* * 最大可能的扩容数量为1 << 30,即2的30次方。 * 说明: * 1.HashMap在确定数组下标Index的时候,采用的是( length-1) & hash的方式, * 只有当length为2的指数幂的时候才能较均匀的分布元素 * 2.由于HashMap规定了其容量是2的n次方,所以我们采用位运算<<来控制HashMap的大小。 * 使用位运算同时还提高了Java的处理速度。HashMap内部由Entry[]数组构成, * Java的数组下标是由Int表示的。所以对于HashMap来说其最大的容量应该是不超过int最大值的一个2的指数幂, * 而最接近int最大值的2个指数幂用位运算符表示就是 1 << 30 */ private static final int MAXIMUM_CAPACITY = 1 << 30; /* * 默认初始表容量。 必须是2的幂,(即至少为1)且最多为MAXIMUM_CAPACITY。 * 所以HashMap规定了其容量必须是2的n次方 */ private static final int DEFAULT_CAPACITY = 16; /* * 最大可能(非幂2)阵列大小,需要使用toArray和相关方法。 * MAX_VALUE = 0x7fffffff; * 数组作为一个对象,需要一定的内存存储对象头信息,对象头信息最大占用内存不可超过8字节 */ static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; /* * 此表的默认并发级别。即Segment数组的大小, * 也就是默认会创建 16 个箱子,箱子的个数不能太多或太少。 * 如果太少,很容易触发扩容,如果太多,遍历哈希表会比较慢。 */ private static final int DEFAULT_CONCURRENCY_LEVEL = 16; /* * 默认加载因子, * 当键值对的数量大于 16 * 0.75 = 12 时,就会触发扩容 */ private static final float LOAD_FACTOR = 0.75f; /* * 计数阈值,当链表中的数量大于等于8时,链表转化为红黑树 * 因为红黑树需要的结点至少为8个 */ static final int TREEIFY_THRESHOLD = 8; /* * 在哈希表扩容时,如果发现链表长度小于 6,则会由树重新退化为链表 */ static final int UNTREEIFY_THRESHOLD = 6; /* * 在转变成树之前,会做一次判断,只有键值对数量大于 64 才会发生转换。 * 这是为了避免在哈希表建立初期,多个键值对恰好被放入了同一个链表中而导致不必要的转化。 */ static final int MIN_TREEIFY_CAPACITY = 64;
ConcurrentHashMap和hashMap的原理类似,下面是一些重要的类:
Node:
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; volatile V val; volatile Node<K,V> next; Node(int hash, K key, V val, Node<K,V> next) { this.hash = hash; this.key = key; this.val = val; this.next = next; }
Node类是构造链表或者红黑树的结点的类,主要包含key,value,hash和next。
TreeNode:
static final class TreeNode<K,V> extends Node<K,V> { TreeNode<K,V> parent; // red-black tree links TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; // needed to unlink next upon deletion boolean red; TreeNode(int hash, K key, V val, Node<K,V> next, TreeNode<K,V> parent) { super(hash, key, val, next); this.parent = parent; } Node<K,V> find(int h, Object k) { return findTreeNode(h, k, null); } /** * 返回给定键的TreeNode(如果未找到,则返回null) * 从给定的根开始。 */ final TreeNode<K,V> findTreeNode(int h, Object k, Class<?> kc) { if (k != null) { TreeNode<K,V> p = this; do { int ph, dir; K pk; TreeNode<K,V> q; TreeNode<K,V> pl = p.left, pr = p.right; if ((ph = p.hash) > h) p = pl; else if (ph < h) p = pr; else if ((pk = p.key) == k || (pk != null && k.equals(pk))) return p; else if (pl == null) p = pr; else if (pr == null) p = pl; else if ((kc != null || (kc = comparableClassFor(k)) != null) && (dir = compareComparables(kc, k, pk)) != 0) p = (dir < 0) ? pl : pr; else if ((q = pr.findTreeNode(h, k, kc)) != null) return q; else p = pl; } while (p != null); } return null; } }
TreeNode类是对红黑树的描述,主要方法是返回给定键的TreeNode。
再看put方法:
final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); int hash = spread(key.hashCode()); int binCount = 0; for (Node<K,V>[] tab = table;;) { //初始化数组 Node<K,V> f; int n, i, fh; if (tab == null || (n = tab.length) == 0) tab = initTable(); //找到具体的数组下标,如果此位置没有值,那么直接初始化一下 Node ,并把值放在这个位置 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); else { V oldVal = null; synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0) { binCount = 1; //将结点加入到链表中 for (Node<K,V> e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } //将结点加入到红黑树中 else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { if (binCount >= TREEIFY_THRESHOLD) //如果结点个数大于等于8,则转化为红黑树 treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } addCount(1L, binCount); return null; }
参考资料: