一下都是MySQL在实际开发中,经常容易让人忽视的点,希望对您有帮助,帮您越过这些坑。
一:MySQL AND优先级大于OR
今天上班时在写一个业务的时候又发现了一个MySQL的问题:
我们的业务是这样的,用户可以修改自己的行数据,但这些行数据中有些数据是不能重复的,举个例子比如我们如果要开公司就要去工商局注册公司名,这时工商局可能就有一个《公司名》的表,这个表有一个主键id字段,然后有一个公司名称字段,公司英文名称字段,以及公司地点字段等等其他的数据字段,很明显这里的公司名以及公司英文名必须是唯一,因为不能有同名的公司。然后我们的业务提供给这个公司一个修改自己这条行数据的功能,比如你可以修改自己公司的中文名称或英文名称,或者地址等等,但是因为公司名是唯一的,所以在我们update数据前,我们先做了一个判断,看是否用户提交的数据中的公司名称以及英文是否已经存在,如果已经存在则告诉他,中文公司名或者是英文名已存在,请修改后重新提交。这里看似业务没有问题,但其实我们稍加测试后就发现了问题:
当用户在修改数据时只修改了中文名称或者英文名称时,此时就会有问题,比如用户想更改自己的英文公司名,因为用户提交的数据的中文名称还是原来的,所以我们在查询时发现这个中文名已经存在,所以会返回修改失败。
比如我们的判断语句是:select * from base_pop where name=$name or en-name=$en-name;只要这个查询返回结果集,就说明修改后的公司名已存在,修改失败。但是我们这里并没有考虑到局部修改的问题,甚至是如果你只想修改公司地址这种可以重复的信息,而没有更改时中英文名称时,这条SQL都会有返回集,所以都会返回修改不成功。
所以后来我们SQL更改为:select * from base_pop where name=$name or en-name=$en-name and id!=$id;这样修改后,基本上就没有问题了。已经可以完成大部分的业务需求,然而这里却引出了MySQL另外的一个问题,也就是我们今天的主题!
请看下图:


从上面这两张图中我们可以看到,当我们写:(A,B,C为三个表达式,如name=1这种),
where A and/or B and/or C; 这种where条件是有时候他的返回集和 where (A and/or B) and/or C; 的返回集一样,而有的时候又和where A and/or (B and/or C); 的返回集一样。这是什么情况呢,这里和我们设想的应该和C语言一样,自左向右运算的想法并不一样。到底MySQL自己的运算机制是自左向右还是自右向左的呢,怎么有的时候是向左有的时候是向右呢?
然而我们仔细查看后返现,会发现上面两种图有一个共性,不管是自作向右还是自右向左,我们发现返回结果集相同的SQL语句的括号总是括这包含and的语句,难道MySQL默认是先执行and语句的?
于是我们查看《MySQL手册》,得出以下结论:

我们发现,果然和我们的猜想一样,AND的操作符优先级就是比OR高,MySQL是用C语言写的,其实C语言在这里也是一样的,在C中&&的操作符优先级就是比||高,所以MySQL这里也是一样的,并不仅仅是简单的左结合性的问题。
这个在开发中也是比较常见的,有的时候会使用不至两个表达式。
二:MySQL中文乱序
今天上班,发现了一个有趣的东西,我们有一张表存的是国内运营商的资料,如id,name之类的。我们有一个业务,需要让用户选择自己对应的运营商,所以后台需要向前端返回运营商的名字以及id,name用来给用户展示,id用来记录用户选择了什么。如下图:
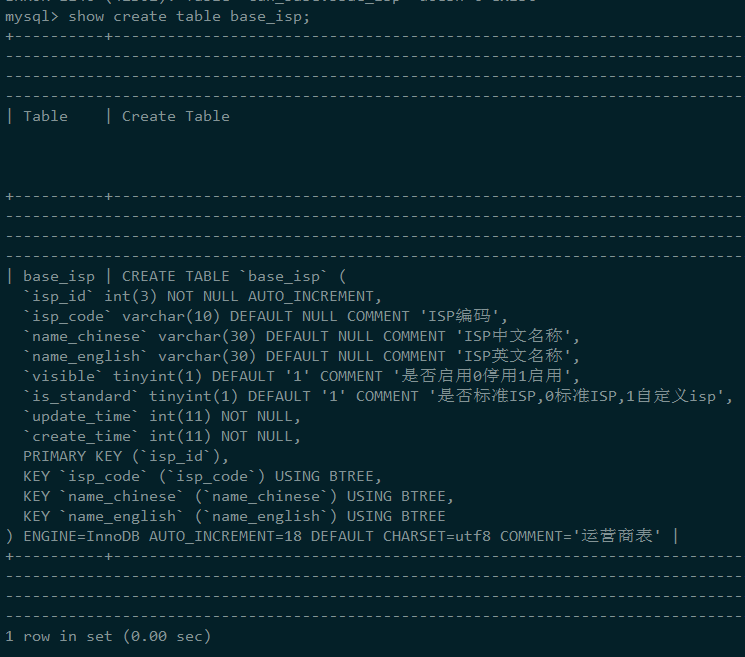
首先,标的结构如下:
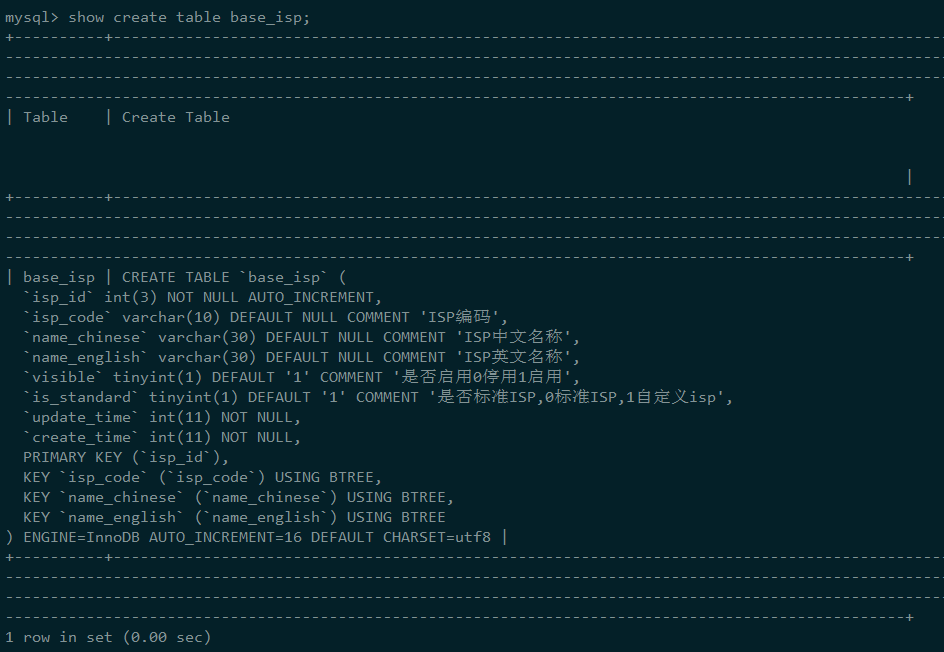
表里的数据如下:
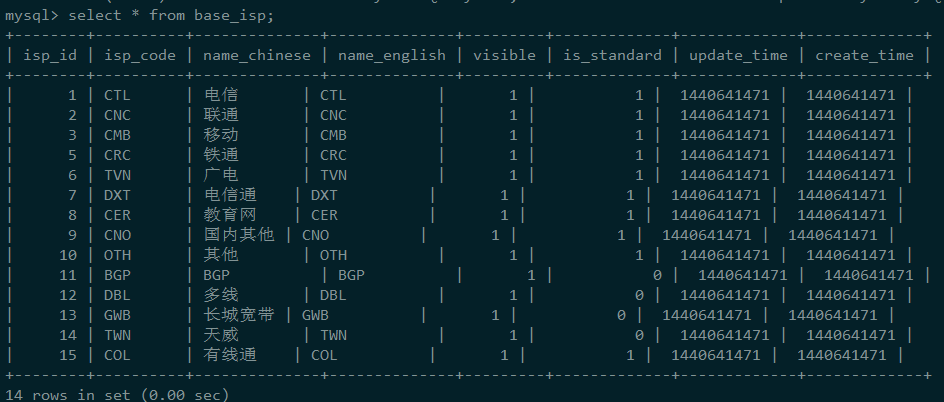
根据业务,我们写入了如下的SQL语句:
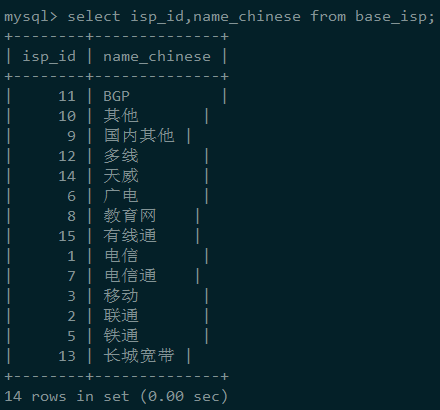
没想到返回的结果街竟然是这样的,为什么会是乱序的呢?为什么id和name都没有呈现出一定的顺序?
仔细看了看,我发现返回的结果集只有两个字段,这不仅让我想起了InnoDB的非聚集索引的结构,(可参看《数据库为什么要用B+数结构--MySQL索引结构的实现》),难道是因为这条SQL使用了name字段上的非聚集索引?所以主键相对无序,但是name字段也没有表现出顺序啊,但是如果我们的查询语句是这样写的,按理说应该就是使用的非聚集索引。此时我有想到哦了MyISAM的倒排索引的全文索引,的确,InnoDB的B+树索引在处理中文的时候是会有一点问题。于是我们做出如下测试:
我们先在表中插入几条测试数据,让这几条数据是英文的:

然后再执行之前的查询语句,
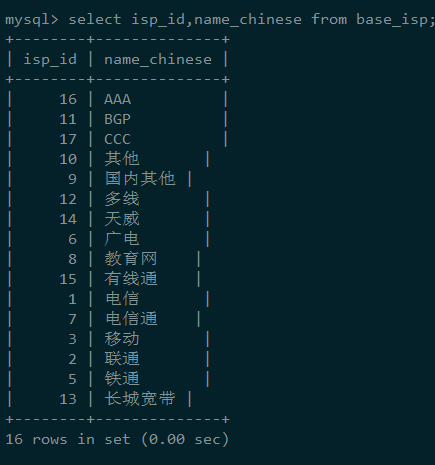
果不其然,这里我们新插入的a,b,c确实表现出的他应该有的顺序。
所以这里的中文应该是有序排列的,只不过没有对应拼音,这应该和中文字符的编码有关系,我们都知道gbk,utf-8等等,汉字在计算机中的存储并不是用拼音,所以没有展现出有序性,如果我们把这些汉字转换成2进制,应该就能看到他们是有序排列的。所以我们在开发中如果要有序,需要自己加上order by:
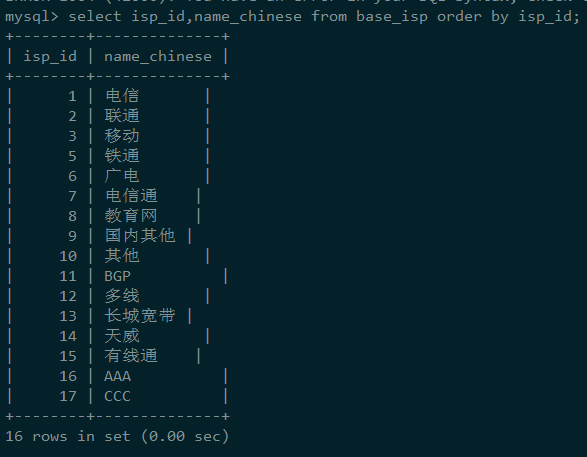
最后,我们再做一个测试,看看我们的猜想对不对,是否使用的非聚集索引:如下
首先,表中的索引有:
我们的SQL使用的索引是:
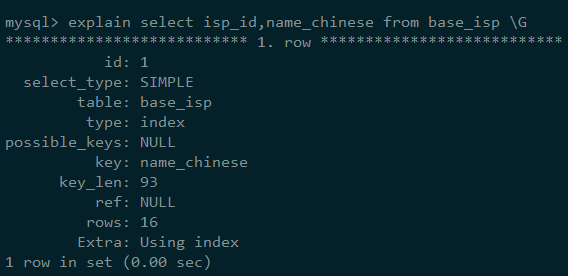
果不其然,使用的就是name字段的索引。
这个在实际开发中还是挺常见的,在InnoDB中当我们使用中文的时候,还是要多加注意。