论文链接:
前一篇随笔AI教父的自监督直觉——SimCLR中介绍了自监督任务的一些动机以及Hinton的方法。在这一篇随笔中,我们来观摩下MoCo,该方法在整体形式上更加丰富,动机也十分清晰。文章的作者阵容可以说十分华丽,Kaiming He 以及 Ross Girshick 等都是业界元佬。
主干思路提炼
了解文章的方法全貌只需要看伪代码足矣。文章的伪代码使用Pytorch形式,非常接地气。
'''
f_k与f_q是将输入信息映射到特征空间的网络,特征空间由一个长度为C的向量表示。
这里的k可以看作模板,q看作查询元素,每一个输入未知图像的特征由f_q提取,
现在给一系列由f_k提取的模板特征(比如狗的特征、猫的特征),就能使用f_q与f_k的度量值来确定f_q是属于什么。
在早先的比较学习中,f_k与f_q使用的是同一个网络,这篇文章的创新点就是,将两者分开,并且两者的参数更新方式是不同的。
'''
f_k.params = f_q.params # 初始化
for x in loader: # 输入一个图像序列x,包含N张图,没有标签
x_q = aug(x) # 用于查询的图(数据增强得到)
x_k = aug(x) # 模板图(数据增强得到),自监督就体现在这里,只有图x和x的数据增强才被归为一类
q = f_q.forward(x_q) # 提取查询特征,输出NxC
k = f_k.forward(x_k) # 提取模板特征,输出NxC
# 不使用梯度更新f_k的参数,这是因为文章假设用于提取模板的表示应该是稳定的,不应立即更新
k = k.detach()
# 这里bmm是分批矩阵乘法
l_pos = bmm(q.view(N,1,C), k.view(N,C,1)) # 输出Nx1,也就是自己与自己的增强图的特征的匹配度
l_neg = mm(q.view(N,C), queue.view(C,K)) # 输出Nxk,自己与上一批次所有图的匹配度(全不匹配)
logits = cat([l_pos, l_neg], dim=1) # 输出Nx(1+k)
labels = zeros(N)
# NCE损失函数,就是为了保证自己与自己衍生的匹配度输出越大越好,否则越小越好
loss = CrossEntropyLoss(logits/t, labels)
loss.backward()
update(f_q.params) # f_q使用梯度立即更新
# 由于假设模板特征的表示方法是稳定的,因此它更新得更慢,这里使用动量法更新,相当于做了个滤波。
f_k.params = m*f_k.params+(1-m)*f_q.params
enqueue(queue, k) # 为了生成反例,所以引入了队列
dequeue(queue)
疑点:为什么矩阵乘法可以算匹配度?
比如输入有N个样本每个样本有C个特征,它可被表示成NxC得矩阵。
现在有一系列模板样本,比如M个,那么它可以被表示为MxC矩阵。
现在将这两个矩阵相乘,得到一个NxM得匹配度矩阵,那么矩阵中i-行,j-列得值就对应输入的第i个样本与模板的第j个样本的相关性。
相关性被记作两个向量的内积,两向量方向越趋同(在此基础上模越大),相关性也就越大。
训练细节
在第一篇文章中的训练batch开的很大为256,使用八张卡训练了53个小时,具体细节比较多,复现可参照原论文。
值得注意的是,批正则化层(BN)使用了一种叫做 Shuffing BN 的方法。 (f_q以及f_k都使用了BN层)
Shuffing BN 方法为:在f_k将参数分散到多卡前(分散是Pytorch基本操作)洗牌其样本顺序,然后再前向传播后整回原状。
具体来说,在命令 k = f_k.forward(x_k) 执行前后进行这个操作,这样保证了每次BN所需的统计信息不仅局限于同一张图的衍生(x_q及x_k的对应项都是由同一张图衍生出来的,如果BN都在这种相似的分布下采样一定会出问题)
重要结果
以下结果是在Imagenet-1M下无监督训练的,并在验证集上测试分类。测试分类之前,把f_q固定住,外加一个全连接层训练一小会儿。可以看到得到的特征表示效果还可以。

下面这个对比主要来看MoCo的动量式(因子0.999)更新f_k方法与直接梯度更新f_k(end-to-end)的对比。

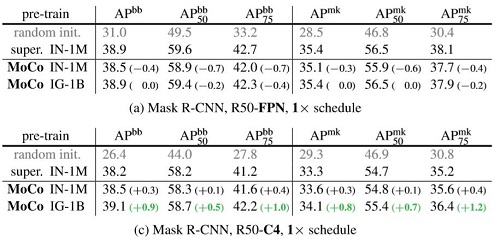
以下为其中一项迁移学习效果,在1M对照下看起来并没有太多的提升。
分析一波
文章主要还是探讨了用于产生模板特征的f_k以及用于产生查询特征的f_q的参数更新方式。其实这个问题在很多工作中都有探讨,在GAN中,有的时候可能先fix住判别器然后再fix住生成器这样的交替方式易于收敛,也比如在强化学习Actor-Crictic中,用于评价当前步骤好坏的网络以及用于产生决策的网络也不是同步更新的(往往fix住一个更新另一个)。这里的方法是采用动量方式去更新f_k,使得用于比较的一端更加稳定,会起到更好的效果。