1.在python2默认编码是ASCII, python3里默认是unicode。可以识别中文
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
unicode 万国码。一个字符(中英)占2个字节16位,一个中文占3字节
utf-8可变长的unicode子集。
acssi 只能存英文,个字符占1个字节8位。不能存中文
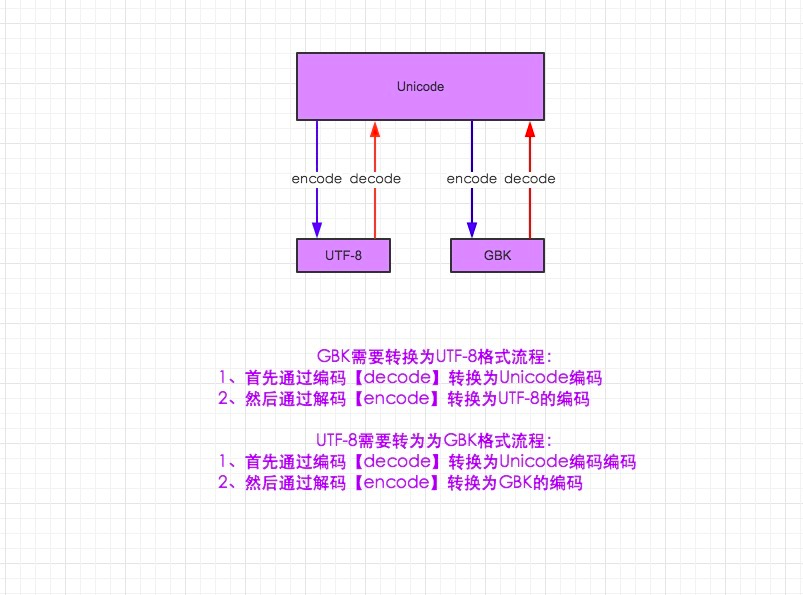
s默认为acssi编码转换为gbk编码
s="你好"
s-to-gbk=s.decode("utf-8").encode("gbk")
decode解码默认都是unicode编码
encode解码默认都是字节类型