
# -*- encoding: utf-8 -*-
"""
@date: 2021/4/2 1:14 下午
@author: xuehuiping
"""
import selectivesearch
import cv2
from PIL import Image, ImageDraw
img = cv2.imread('WechatIMG92.jpeg')
img_label, regions = selectivesearch.selective_search(img, scale=500, sigma=0.9, min_size=100)
print(regions[:10])
im = Image.open('WechatIMG92.jpeg')
draw = ImageDraw.Draw(im) # 实例化一个对象
for region in regions:
rect = region['rect']
# 'rect': (left, top, width, height)
x1, y1, x2, y2 = rect
x2 = x1 + x2
y2 = y1 + y2
draw.polygon([(x1, y1), (x1, y2), (x2, y2), (x2, y1)], outline=(255, 0, 0))
im.show()
所有结果
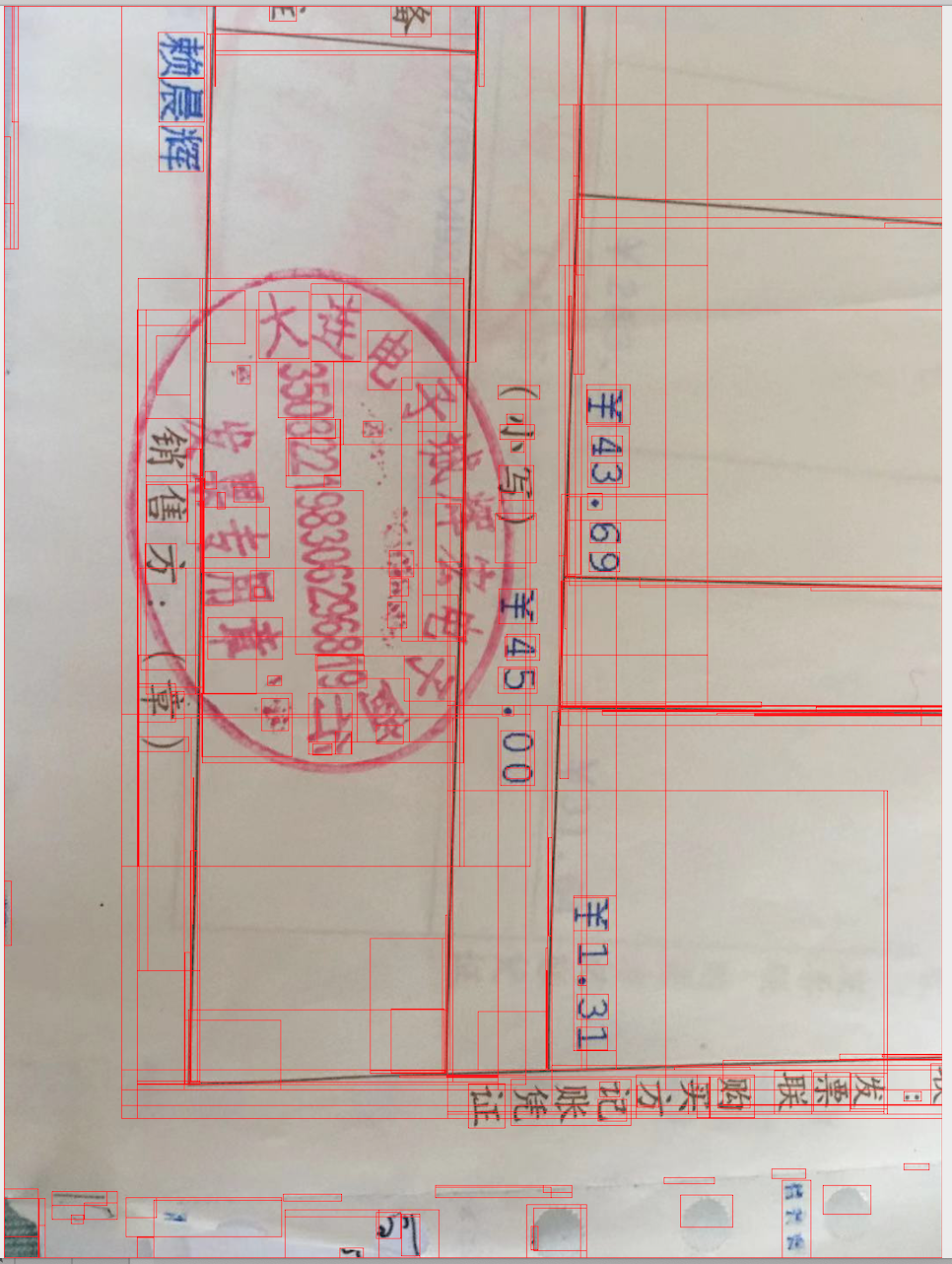
去除篇幅过大的
# 太大的框,不要了
if width > width_all / 10:
continue
if height > height_all / 10:
continue
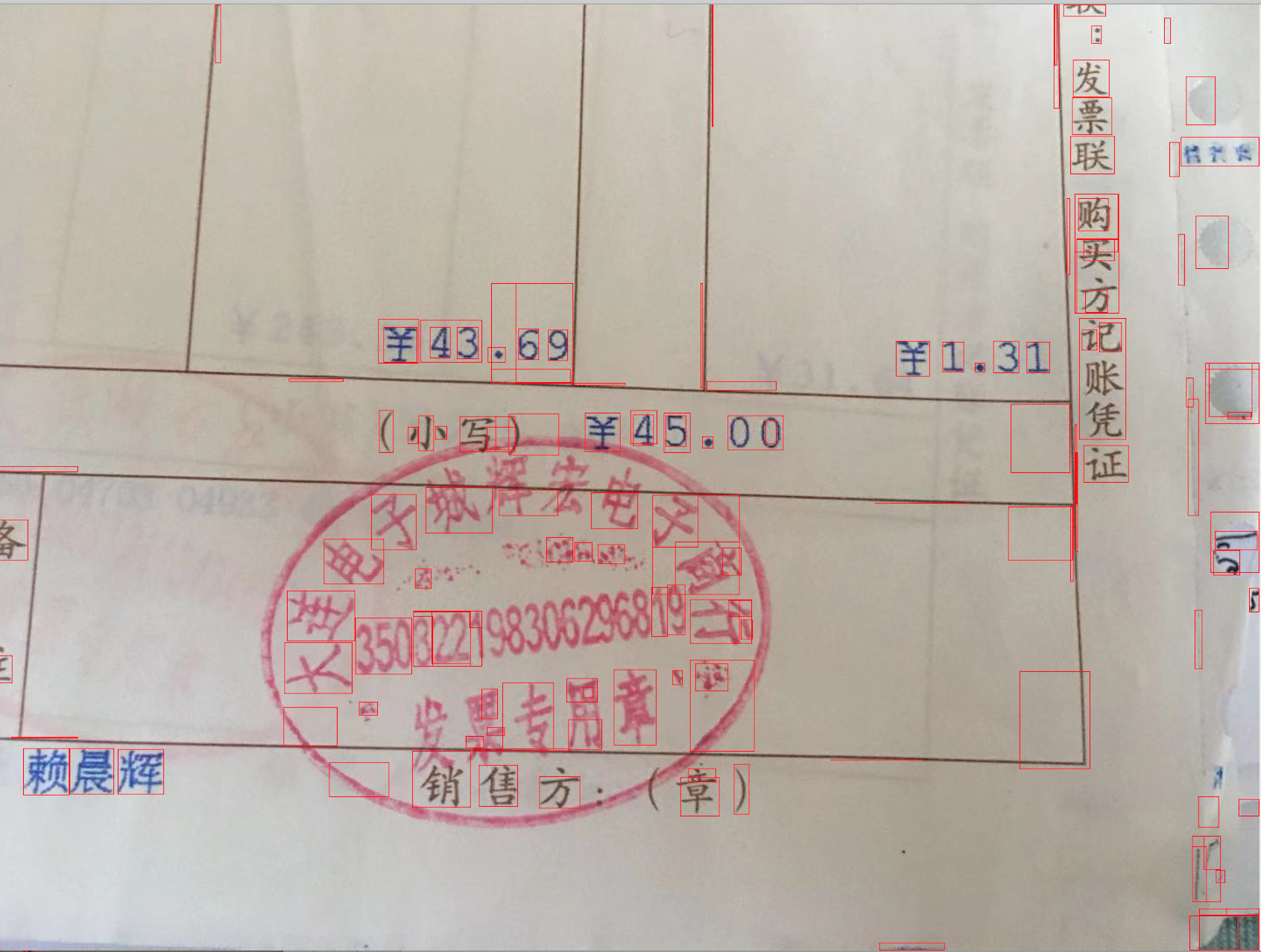
再去除过长过宽的
# 不方正的,不要了
if width / height > 2 or height / width > 2:
continue
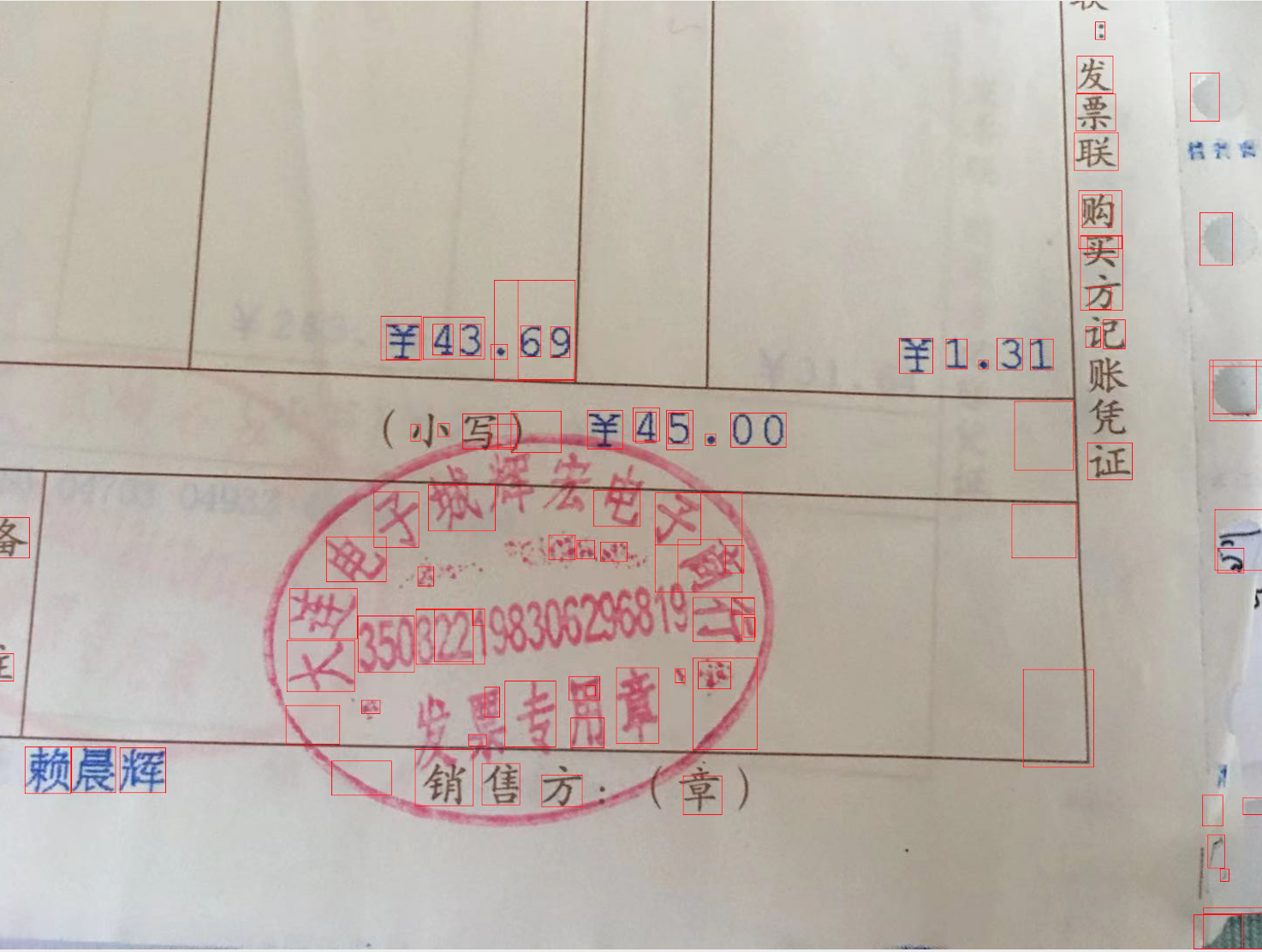
思考
若是能提前将蓝色、绿色、黑色的去掉,效果能更好一些