项目背景:
现在是一名大三生,在早早的为实习做准备。一直向往着互联网之都—杭州,实习也准备投往杭州。到了杭州肯定得租房
住,那么许多租房的问题也接踵而至:房租贵、位置偏、房屋旧、房东一言不合就涨租等问题,且也经常听学长抱怨:“早知道
公司附近租房这么贵,当初谈薪资的时候就报个更高的价格了,生活负担更重了”。我在想,要是事先知道当前杭州市场租房 价格的合理统计范围或可视化,那就会避免这些问题,减轻自己负担。正是了解到这些情况,所以用自己所学知识来分析了下杭州的租房价格情况~
项目简介:
数据:从国内的房天下网站上爬取了近万条杭州的租房信息,来探索分析影响房租价格的原因。希望能帮助像我一样准备实习或刚参加工作的同学来避开租房上的坑,以更少的钱住性价比更高的房。
数据集
本项目使用的数据集是通过八爪鱼采集器从房天下网站上爬取的2018年12月份的部分租房信息。八爪鱼是款通过内置采集模板和可视化设置便能快速准确采集数据的工具。(正在学习爬虫框架中~)房天下 网站的信息时效性和真实性较高,且数据源整洁、规范,数据质量高,可以减少前期数据清理工作。
本项目数据集包含以下字段:楼盘名称 building_names 、租凭方式lease_way、户型house_type、面积areas、朝向orientation、房租rent、房源信息source、城市city、区域area、街道street、小区cell、地址address、公交traffic、主图链接picture_url、楼盘详情链接building_url、页面网址url、标签tags。
目的
希望通过本项目的分析提供一些有依据的参考数据,来帮助跟我一样准备实习或刚工作的同学们
解决租房问题。
主要针对:1.面积,是租单间还是整租,什么面积合适?
2.地段,哪个地段合适且房租较便宜?
3.朝向、户型、房源对房价有什么影响?
4.租房的标签
工具
本项目以python为基础,在jupyter notebook上运用pandas,numpy,matplotlib等库进行数据清理、探索分析、可视化等处理。也用了tableau创建了交互式面板,更加方便大家去发现探索自己关心的问题。
数据清理
1.评估数据
#加载库、数据集
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
df=pd.read_csv('rent_data.csv')
df_clean=df.copy()
#评估数据
df_clean.shape #数据框维度
df_clean.info() #总体数据简明摘要
df_clean=df_clean.rename(columns={'ares':'areas'})#有一处列名错误,修改为areas
type(df_clean.areas[0]),type(df_clean.rent[0]) #更加详细查看areas、rent的数据类型
df_clean.head() #查看数据前五行
输出:
RangeIndex: 8145 entries, 0 to 8144
Data columns (total 18 columns):
building_name 7879 non-null object
lease_way 7879 non-null object
house_type 7879 non-null object
ares 7866 non-null object
orientation 7381 non-null object
rent 7879 non-null object
source 1966 non-null object
time 8145 non-null object
city 8145 non-null object
area 8145 non-null object
street 8145 non-null object
cell 7879 non-null object
address 7879 non-null object
traffic 2006 non-null object
picture_url 7879 non-null object
building_url 7879 non-null object
url 8145 non-null object
tags 6764 non-null object
dtypes: object(18)
memory usage: 1.1+ MB
(str,str)
存在问题:
- 发现有18列,8144行,但其中只有7879行是有楼盘名称的有
效数据。 - 发现本该为整数类型的areas(面积),rent(房租)两列为字符串类型。
- 去除对本项目分析无效的图片链接、楼盘详情链接、页面地址等列。
- 把标签列按符号‘/’分成两列。
2.清理数据
#针对问题 1
df_clean.dropna(subset=['building_name'],inplace=True)
df_clean.shape
输出:(7879,18) #确实跟判断的一样,只有7879行数据有效
#针对问题 2
#areas列
df_clean.dropna(subset=['areas'],inplace=True) #把areas列中空行去掉
df_clean['areas']=df_clean.areas.str.strip('㎡') #整列字符串去掉‘㎡’字符
df_clean['areas']=df_clean['areas'].astype(int) #数据类型转换成整型
#rent列
df_clean.dropna(subset=['rent'],inplace=True) #把rent列中空行去掉
df_clean['rent']=df_clean.rent.str.extract(r'(\d+)') #采用正则化法提取每月房租价格
df_clean['rent']=df_clean['rent'].astype(int) #数据类型转换成整型
#针对问题 3
df_clean.drop(['picture_url','building_url','url'],axis=1,inplace=True) #删除无用列
#针对问题 4
df_clean['tag1'],df_clean['tag2']=df_clean.tags.str.split('/',1).str
df_clean.drop(['tags'],axis=1,inplace=True) #把标签列拆分成多列标签
pd.DataFrame(df_clean).to_csv('rent_data_clean.csv') #保存成新数据集
探索分析
加载初始数据
df=pd.read_csv('rent_data_clean.csv')
df_clean=df.copy()
df_clean['price_sq_m']=df_clean['rent']/df_clean['areas']
df_clean=df_clean[df_clean.areas<250] #除去超级大house、高档装潢、富人区,不在我们租房考虑范围内
df_clean=df_clean[df_clean.price_sq_m<500]
问题一:面积因素
#面积问题
sns.set_style('darkgrid')
a=df_clean.groupby(df_clean.areas).price_sq_m.mean()
fig=plt.figure(figsize=(12,6))
plt.xticks(np.arange(0,249,10))
plt.plot(a)
plt.xlabel(u'面积/㎡',fontproperties = myfont,fontsize=15)
plt.ylabel('每平方米价格(均值) /元',fontproperties = myfont,fontsize=15)
plt.title('租单间or整租?',fontproperties = myfont,fontsize=18)

当面积为10平米时均价最高,在40—100平米这个区间平均租金比较便宜。其中30、45、60、100这几个面积租房均价较低,推荐合租或整租时选择这几种面积。在面积超过100后小区、装修都比较高档,所以价格会更高。推荐同学们可以找好朋友一起去整租100平以下的租房。
问题二:户型、朝向、房源因素
1.户型因素
#户型
df_clean_price_mean=pd.DataFrame(df_clean.groupby(['house_type']).price_sq_m.mean())
df_clean_price_mean.reset_index('house_type',inplace=True)
new_name=list(df_clean_price_mean.columns)
new_name[-1]='mean_price'
df_clean_price_mean.columns=new_name
df_clean_price_mean.sort_values(by='mean_price',ascending=False,inplace=True)
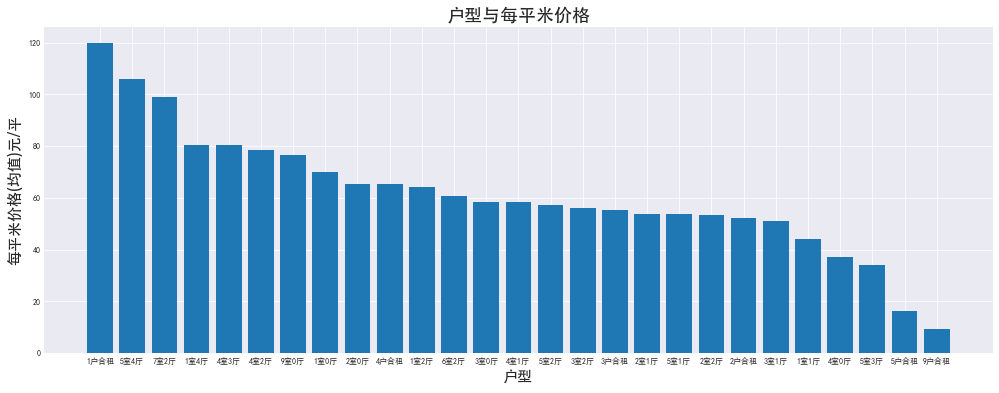
租房时,只有
1户合租 5室4厅 7室2厅这几种户型均价偏高,其他户型价格差异不大。避开前三种户型,然后选择什么类型的户型完全看个人喜好了~
2.朝向因素
#朝向
df_orientation=df_clean.query('areas==30')
df_orientation=pd.DataFrame(df_orientation.groupby(['orientation']).price_sq_m.mean())
df_orientation.reset_index('orientation',inplace=True)
df_orientation.sort_values('price_sq_m',ascending=False,inplace=True)
plt.xticks(arange(len(df_orientation.orientation)),df_orientation.orientation)
plt.bar(arange(len(df_orientation.orientation)),df_orientation.price_sq_m)
plt.xlabel('朝向',fontsize=15)
plt.ylabel('每平均价 平/元',fontsize=15)
plt.title('朝向与每平价格(30平为例)',fontsize=18)

以面积为30平的为例,
朝南朝北的价格要高于朝东,朝西的价格。道理也是,朝南的,朝北的南北通透,采光通风要好。差距在每平10~20元左右。但是我分析也发现:面积不同的房间,对应的的最高价格朝向也不相同,原因可能是与楼层有关,高楼层房间会遮挡低楼层的阳光。
3.房源因素
#房源
df_clean.source.fillna('平台房源',inplace=True)
df_source=df_clean.query('areas==30')
df_source=pd.DataFrame(df_source.groupby(['source']).price_sq_m.mean())
df_source.reset_index('source',inplace=True)
plt.bar(df_source.source,df_source.price_sq_m)
plt.xlabel('房源',fontsize=15)
plt.ylabel('每平价格 平/元',fontsize=15)
plt.title('房源与每平价格(平/元)',fontsize=18)

个人房源与平台房源的房租价格非常接近,价格差很小。对租房的影响不大,原因是其中的个人房源大部分也是掌控在中介手中,导致价格与平台价格相似。
问题三:地段,哪个地段适合租房(西湖区)?
运用Tableau制作交互式面板,以杭州市西湖区为例,可看出出租房房源密度,价格。颜色深度,图形大小代表着房租的每平价格。颜色深、形状大则房租高。
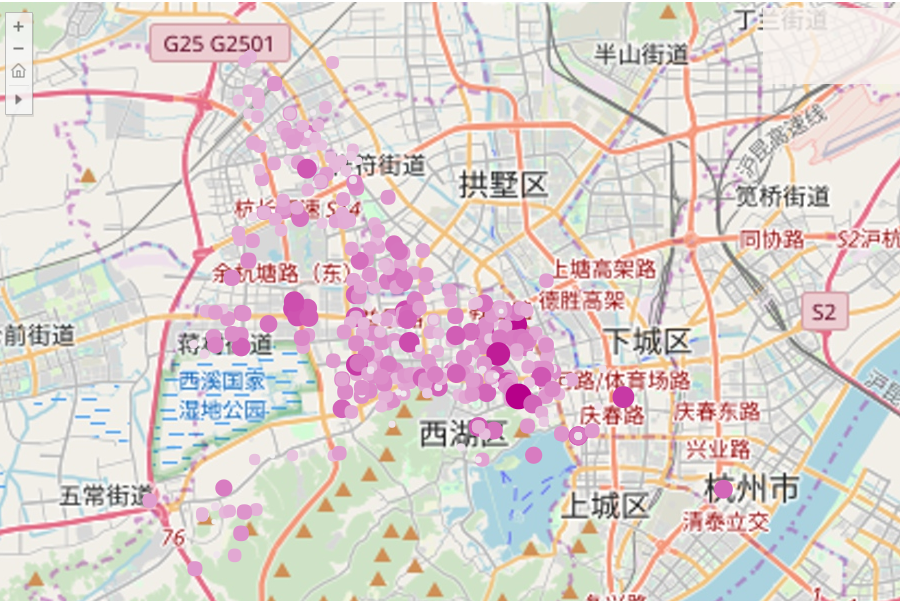
西湖区中,在
西湖-益乐路、教工路、杭长高速、中和路/体育场路周围房源最多,从密度就可以看出。
在这其中,在西湖—西溪诚园、西湖—益乐路和以教工路为中心的古荡、杭州电子科技大学、北山的嘉华商务中心周围房租价是高于平均房租,租房时尽量避开这些地点。其他地方的交通虽没这些地方方便,但考虑到房价后性价比还是较高的。
交互式面板连接:https://public.tableau.com/profile/.65007288#!/vizhome/_28305/1_1
可探索发现自己关心问题。
问题四: 租房的标签词云图
#问题四:标签词云图
from scipy.misc import imread
from wordcloud import WordCloud
from wordcloud import ImageColorGenerator
a=df_clean.tag1.dropna()
b=df_clean.tag2.dropna()
f_list=[]
df1_clean1=a.reset_index(drop=True)
df1_clean2=b.reset_index(drop=True)
for i in range(len(df1_clean1)):
f_list.append(str(df1_clean1[i]+' '))
for i in range(len(df1_clean2)):
f_list.append(str(df1_clean2[i]+' '))
f_list
#把f_list数组,放入df1_text.txt文本中。
file_name=open('df_text.txt',mode='w',encoding='utf-8')
file_name.writelines(f_list)
background_image =imread('temp.png')
f= open(u'df_text.txt','r',encoding='utf-8').read()
wordcloud = WordCloud(
mask=background_image,
font_path='C:\Windows\Fonts\AdobeHeitiStd-Regular.otf',
).generate(f)
# 绘制图片
plt.imshow(wordcloud)
# 消除坐标轴
plt.axis("off")
# 展示图片
plt.show()

租房标签中,
随时看房、拎包入住、家电齐全、精装修、南北通透的标签是最多的,可看出人们在租房时最注重的是方便、通透。
结论
根据上面数据,与人合租40—100平米的租房价格较低,房型上避开1户合租、5室4厅、7室2厅这三种户型,其他价格相差不大。房源与房间朝向对房租价的影响不大,具体结合自己情况来。西湖区为例,其房源主要集中在益乐路、教工路、杭长高速、中和路/体育场路。远离学校、商务中心等房租价格偏贵地区;从标签词云看出,房间是否‘方便’、‘通透’是租户最为关心的问题。
希望这篇简单的房租数据分析文章能够帮助像我一样准备前往杭州实习,或刚参加工作的同学提前洞悉杭州租房市场价格影响因素,找到合适的房源来减轻点租金带来的生活负担~