习题来自于: http://www.cnblogs.com/wangfengming/articles/7891939.html
习题答案来自于: https://www.cnblogs.com/wangfengming/articles/7978354.html
需要创建的表结构如下: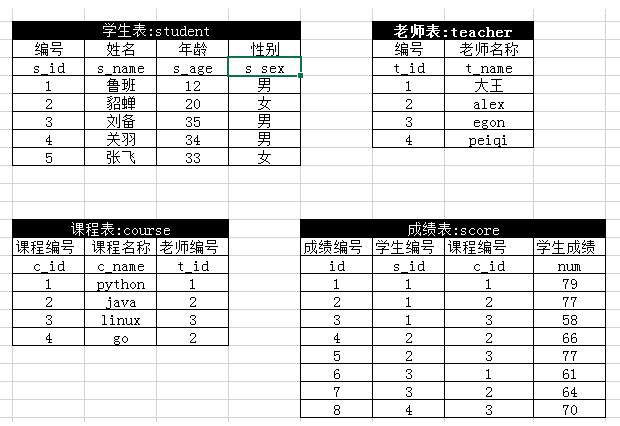
首先创建学生表 student:
-- 创建学生表 create table student( s_id smallint unsigned not null auto_increment primary key, -- 学生编号 s_name varchar(40) not null, -- 姓名 s_age int not null, -- 年龄 s_sex char(2) not null) -- 性别 insert into student(s_name,s_age,s_sex) values("鲁班",12,"男"); insert into student(s_name,s_age,s_sex) values("貂蝉",20,"女"); insert into student(s_name,s_age,s_sex) values("刘备",35,"男"); insert into student(s_name,s_age,s_sex) values("关羽",34,"男"); insert into student(s_name,s_age,s_sex) values("张飞",33,"女"); select * from student; -- 创建老师表 create table teacher( t_id smallint unsigned not null auto_increment primary key,-- 教师编号 t_name varchar(40) not null) -- 教师姓名 insert into teacher(t_name) values("大王"),("alex"),("egon"),("peiqi") -- 创建课程表 create table course( c_id smallint unsigned not null auto_increment primary key, -- 课程编号 c_name varchar(40) not null, -- 课程名字 t_id smallint unsigned not null) -- 教师编号 insert into course(c_name,t_id) values("python",1),("java",2),("linux",3),("go",2) -- 创建成绩表 create table score( id smallint unsigned not null auto_increment primary key, -- 成绩编号 s_id smallint unsigned not null, -- 学生编号 c_id smallint unsigned not null, -- 课程编号 result int not null) -- 成绩得分 insert into score(s_id,c_id,result) values(1,1,79); insert into score(s_id,c_id,result) values(1,2,77); insert into score(s_id,c_id,result) values(1,3,58); insert into score(s_id,c_id,result) values(2,2,66); insert into score(s_id,c_id,result) values(2,3,77); insert into score(s_id,c_id,result) values(3,1,61); insert into score(s_id,c_id,result) values(3,2,64); insert into score(s_id,c_id,result) values(4,3,70);
1. 查询学习课程"python"比课程 "java" 成绩高的学生的学号;
select t1.s_id,t1.id,t1.result as python_result,t2.result as java_result from score as t1 left JOIN -- 把socre表与只取了c_id=2的socre表进行左连接,连接条件是两者的s_id相等, (select s_id,result from score where c_id=2)as t2 -- 筛选条件是t1的c_id=1(选python成绩) 并且t1.result>t2.result(表示python成绩比java成绩高) on t1.s_id=t2.s_id where t1.c_id=1 and t1.result>t2.result;
运行结果:

2. 查询平均成绩大于65分的同学的姓名和平均成绩(保留两位小数);
select s_name,format(result_avg,2)as result_avg from student inner join -- result_avg是平均成绩 format(resulr_avg,2)对平均成绩保留两位小数 (select s_id,avg(result)as result_avg from score group by s_id having result_avg>65 )as t2 -- 对score表按照s_id分组,计算每一组学生的平均成绩(分组条件是result_avg>65) 然后和student表内链接 on student.s_id=t2.s_id -- 内连接条件是两张表的s_id相等;
运行结果:
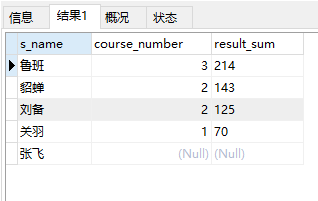
3. 查询所有同学的姓名、选课数、总成绩
select s_name,course_number,result_sum from student left join -- 将student表与score表(基于s_id分组,求出每位学生的选课数count(c_id) 总成绩sum(result)) (select s_id,count(c_id)as course_number,sum(result)as result_sum from score group by s_id) as t2 -- 两表左连接 连接条件是s_id相等 on student.s_id=t2.s_id;
运行结果:
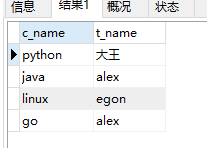
4. 查询所有的课程的名称以及对应的任课老师姓名;
采用左连接查询:
select c_name,t_name from course left JOIN (select t_id,t_name from teacher)as t2 on course.t_id=t2.t_id;
运行结果:
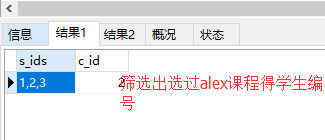
5. 查询没学过“alex”老师课的同学的姓名;
方法一 :(思路是好的,但是最后发现group_concat 来判断根本行不通!!)
错误:
select t1.s_ids,t1.c_id from -- 两张临时表左连接 连接字段是c_id score ,这样可以基于两张临时表筛选出t1.s_ids c_id就是选过alex课得学生编号 (select GROUP_CONCAT(s_id)as s_ids,c_id from score group by c_id) as t1 -- 首先按照c_id分组得到t1表 inner join (select c_id from course where t_id =(select t_id from teacher where t_name="alex"))as t2 -- course表中基于t_id=2的条件筛选的c_id得到的t2表 on t1.c_id=t2.c_id;
select s_id,s_name from student where s_id not in (select t1.s_ids from -- 两张临时表左连接 连接字段是c_id score ,这样可以基于两张临时表筛选出t1.s_ids c_id就是选过alex可得学生编号 (select GROUP_CONCAT(s_id)as s_ids,c_id from score group by c_id) as t1 -- 首先按照c_id分组得到t1表 inner join (select c_id from course where t_id =(select t_id from teacher where t_name="alex"))as t2 -- course表中基于t_id=2的条件筛选的c_id得到的t2表 on t1.c_id=t2.c_id)
运行结果:(错误版本):
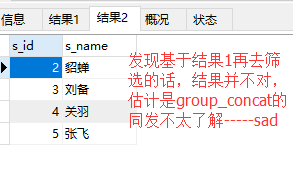
方法二:(啊 我要崩溃了,先跳过,写不出来了23333)
嗯,我吃完饭回来很随意的写出来了,,,,(所以是刚才饿的宝宝大招没使出来???)
select s_name from student where s_id not in (select s_id from score left join (select c_id as cid from course where t_id=(select t_id from teacher where t_name="alex")) as t2 on score.c_id=t2.cid where cid is not null);
(其实应该用内连接,这样最后cid字段非空的条件就不用加了)
思路就是:首先把 teacher表中t_name 为alex的t_id选出来,然后根据t_id 去course表中找到该老师相应的课程,将该临时表与score表进行连接,连接条件是c_id相等,然后筛选出来的就是上过该老师课的学生s_id ;
接下来就直接去student表中过滤就行了~
6 . 查询学过'python'并且也学过编号'java'课程的同学的姓名;
这个题跟上面那个题思路差不多:
select s_id,s_name from student where s_id in ( select s_id from score -- 将score表与筛选出c_id的临时表进行内链接 inner join (select c_id as cid from course where c_name in ("java","python"))as t2 -- 首先把c_name=java python的c_id 从course表筛选出来 on score.c_id=t2.cid group by s_id having count(c_id)>=2 -- 将连接之后的表按照s_id分组,然后查找count(c_id)>2的那些s_id就是同时选了python和java的同学 );
运行结果: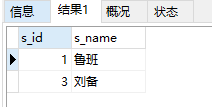
7. 查询学过“alex”老师所教的全部课程的同学的姓名;
(查询结果应该是null 因为alex教了两门课 go没人上)
select s_id,s_name where s_id in ( select s_id from score inner JOIN (select c_id as cid from course where t_id in (select t_id from teacher where t_name ="alex")) as t2 on score.c_id=t2.cid -- 将两张表内连接,条件是c_id相等(内连接取交集) group by s_id having count(c_id)>=(select count(c_id) from course where t_id in (select t_id from teacher where t_name ="alex")) -- 根据t_id查找该老师教的课程c_id; -- 将连接之后的表 按照s_id分组,取包含c_id大于2(也是根据t_id找到的c_id的数目代表该老师所教的课程)的同学s_id(代表上过t_id的所有课) )
注:
这个结果在这里运行是报错的,因为内层的select找不到这样的s_id (所以外层再根据s_id 查找student表时 是会报错)
8. 查询挂科超过两门(包括两门)的学生姓名;
(数据写的不好,这里认为<70挂科)
select s_id,s_name from student where s_id in ( (select s_id from(select * from score where result<70) as t1 group by s_id having count(c_id)>=2) )
思路: 首先根据result<70 筛选出score表的信息,然后按照s_id分组,挑选组内包含c_id个数>=2的s_id 就代表该同学至少两门课成绩小于70;
运行结果:
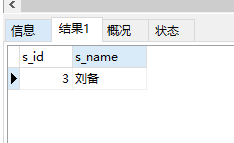
9. 查询有课程成绩小于70分的同学的姓名;
select s_id,s_name from student where s_id in ( select distinct s_id from score where result<70 -- 筛选课程成绩<70的score表中的信息 )
运行结果: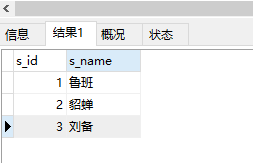
10. 查询选修了全部课程的学生姓名;
select s_id from score inner join course -- 将course 表与score表进行连接 on score.c_id=course.c_id -- 连接条件是两者的c_id 相等 group by s_id -- 将连接好的表按照s_id分组 having count(course.c_id)>(select count(c_id)from course); -- 筛选出分组后小组内c_id数目大于 课程表course中c_id总数目的学生s_id
运行结果: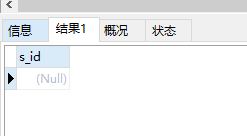
11. 查询至少有一门课程与“貂蝉”同学所学课程相同的同学姓名
select s_id from student where s_name="貂蝉";-- 筛选出貂蝉同学的s_id select c_id from score where s_id=(select s_id from student where s_name="貂蝉"); -- 根据貂蝉同学的s_id 筛选出 c_id select s_id,s_name from student where s_id in ( select distinct s_id from score -- 从score表中筛选出c_id 为貂蝉所选的课对应的c_id的同学编号(不包括貂蝉本人) where c_id in (select c_id from score where s_id=(select s_id from student where s_name="貂蝉")) and s_id <>(select s_id from student where s_name="貂蝉") )
运行结果: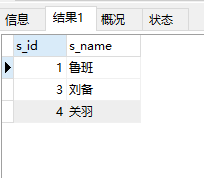
12. 查询学过'貂蝉'同学全部课程 的其他同学姓名;
select s_id,s_name from student where s_id in( select s_id from score -- 将score表 和 根据貂蝉查找的s_id 再根据s_id查找的c_id 临时表 进行内连接 (这样就获得了修过貂蝉全部课程的s_id) inner join (select c_id as cid from score where s_id =(select s_id from student where s_name="貂蝉"))as t2 on score.c_id=t2.cid where s_id <>(select s_id from student where s_name="貂蝉") group by s_id having count(c_id)>=2 )
运行结果: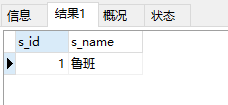
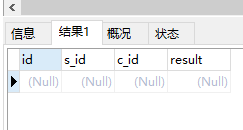
13. 查询和'貂蝉'同学学习的课程完全相同的,其他同学姓名;
select * from score group by s_id -- 对score表按照s_id 分组 having count(c_id)=2 -- 筛选条件一: 分组后count(c_id)=2 (因为是课程完全一致,不能多也不能少)--这只是从数量上对不合理的s_id进行删除,还有可能有人选了3,4而不是2,3 但都是两门课 and c_id in (select c_id from score where s_id =(select s_id from student where s_name="貂蝉")) -- 需要该s_id 的每一门c_id 都得在 貂蝉所选课的c_id中 and s_id <> (select s_id from student where s_name="貂蝉"); -- 还要把貂蝉本人去掉
运行结果:
14. 按平均成绩倒序显示所有学生的“python”、“java”、“linux”三门的课程成绩,按如下形式显示: 学生ID,python,java,linux,课程数,平均分;
select s_id,avg(result)as result_avg, (case when c_id=1 then result else "null" end)as "python", (case when c_id=2 then result else "null" end) as "java", (case when c_id=3 then result else "null" end) as "linux" from score group by s_id order by result_avg desc;
这一题竟然被我做出来了,,,2333
运行结果: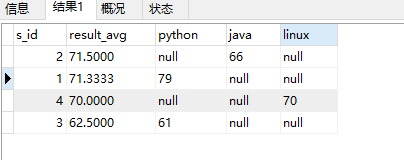
16. 统计各科各分数段人数.显示格式:课程ID,课程名称,[100-85],[85-70],[70-60],[ <60] ;
select score.c_id,c_name, sum(case when result between 85 and 100 then 1 else 0 end) as "[100-85]", sum(case when result between 70 and 85 then 1 else 0 end )as "[70-85]", sum(case when result between 60 and 70 then 1 else 0 end ) as "[60-70]", sum(case when result <60 then 1 else 0 end ) as "[<60]" from score left join course on score.c_id=course.c_id group by c_id;
这一题竟然也被我写出来了,,好了好了今晚加鸡腿
运行结果: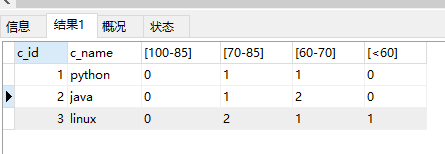
废话:
这种类型题目的思路一般都是,你想对这一列进行什么样的操作,比如【100-85】就是想统计成绩在85-100之间的人数,那我们就可以when 条件 then 满足条件时执行的结果 else 不满足条件的结果 end;
很明显这里的条件应该是result在85-100之间 then 后面跟的1 else 后面 跟0 是因为我们想统计同一组中位于这个分数段的人数,其实分组之后,比如c_id=1这一组,他仍然是包含三个人的信息(id=1,2,3) case之后python列对应的就是相应id 的相应result放在case中执行的结果,比如这里就是0,0,0 嘛(因为c_id=1的这三个人result全都是小于85分 所以对这三个人的result进行case得到的三个结果都是0,就是c_id那一组中三个0 ) 所以sum之后仍然是0,也就是该c_id组 分数result位于85-100之间的人数为0
其他的以此类推
之前分组一直没搞懂,其实是分组仍然保留着原来的信息,可以对组内”显示会重叠的项“正常操作!!!相当于是很多个项被压在一个方块里了~~(说成这样我好庸俗啊,嫌弃.jpg)可以正常的count ,max min 或者case() 对多个数据项操作的函数 可以用在分组之后的字段中*(包含多个id的信息,数据同一类的分组)
16. 查询每门课程被选修的次数;
思路: score表对c_id分组,统计s_id的个数--选修该门课的人数,应该就是代表该门课被选修的次数;
select score.c_id,c_name ,count(s_id)as times from score right join course on score.c_id=course.c_id -- 右连接,因为是统计所有课程 group by c_id;
运行结果: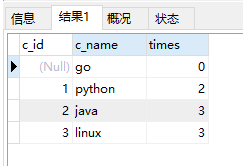
17. 查询出只选修了一门课程的学生的学号和姓名;
select s_id,s_name from student where s_id in( select s_id from ( select s_id,count(c_id)as num from score group by s_id) as t2 where num=1 ); select s_id,s_name from student where s_id in ( select s_id from score group by s_id having count(c_id)=1 ); -- 注意基于分组后想要有条件判断筛选数据用的是having 而不是where;
运行结果: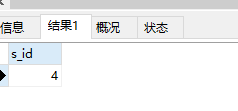
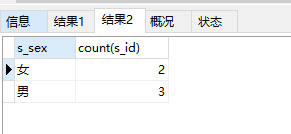
18. 查询学生表中男生、女生各有多少人;
select s_sex,sum(case when s_sex="男" then 1 else 0 end) as "男生人数", sum(case when s_sex="女" then 1 else 0 end )as "女生人数" from student group by s_sex; select s_sex,count(s_id) from student group by s_sex;
运行结果: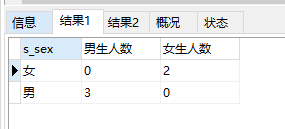
(发现自从熟悉了分组,就喜欢秀case)
19. 查询每门课程的平均成绩,结果按平均成绩升序排列,平均成绩相同时,按课程号降序排列;
select c_id,avg(result)as result_avg from score group by c_id order by result_avg asc,c_id desc; -- order后面跟多个条件时先根据前面的条件排序,重复的按照后面的条件排序
运行结果:
测试:
create table info ( id int not null auto_increment primary key, score int not null, num int not null) insert into info(score,num) values(100,2),(90,3),(30,2),(100,4) select * from info; select * from info order by score desc,num desc; select * from info order by score desc,num asc;
运行结果:
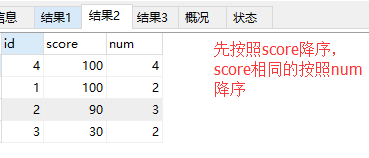
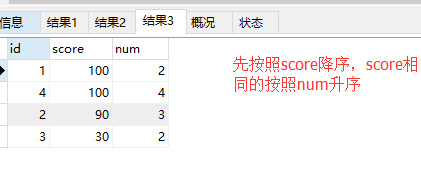
20. 查询课程名称为“python”,且分数低于70的学生姓名和分数;
select student.s_id,s_name,c_name,result from score left join course on score.c_id=course.c_id left join student on score.s_id=student.s_id where c_name="python" and result<70;
思路:score 表,student表,course表连接然后根据c_name result筛选合适的数据;
运行结果:
