1.hashlib 是一个提供很多摘要算法的模块;
其实我们在使用摘要算法进行加密时,可以有三种方式:
1. 普通加密:
import hashlib md5=hashlib.md5() # 使用md5摘要算法进行加密 md5.update(bytes("xuanxuan",encoding='utf-8')) print(md5.hexdigest())
运行结果:

但是其实对于一些特别简单的密码,比如123456 直接使用上面的md5摘要算法进行加密时,是很容易被破解的,就是有一群很无聊的人,会去把很多简单的字符串使用md5摘要算法加密之后的结果放到一个库中,然后当你来一个对简单密码进行md5摘要算法加密的结果,就会把这个结果和库进行比对,从而还原用户输入的明文密码,专业点也叫撞库;
于是:
2. 摘要算法加密的第二种方式----加盐:
import hashlib md5_salt=hashlib.md5(bytes("加盐(当然你也可以写其他的字符,俗称加盐)",encoding='utf-8')) # 加盐操作 md5=hashlib.md5() # 这里就没有加盐 md5.update(bytes("xuanxuan",encoding='utf-8')) md5_salt.update(bytes("xuanxuan",encoding='utf-8')) # md5.update()中的内容才是真正需要加密的内容; print(md5_salt.hexdigest()) # 加盐之后再对字符串xuanxuan使用md5摘要算法进行加密的结果 print(md5.hexdigest()) # 未加盐操作,对字符串xuanxuan进行md5加密之后的结果
运行结果:
3. 动态加盐
但其实上面那种方式也不是最安全的,,,我们可以采用动态加盐的方式,对所需加密的字符串使用摘要算法动态加密;比如用户在注册时,需要输入用户名和密码,我们在对密码使用摘要算法进行加密是就可以动态加盐,就是把用户名或者用户名的一部分作为“盐”:当然在我们进行用户登录验证时,也需要使用相同的动态加盐方式对用户登录时输入的密码进行加密,这样才能比较~
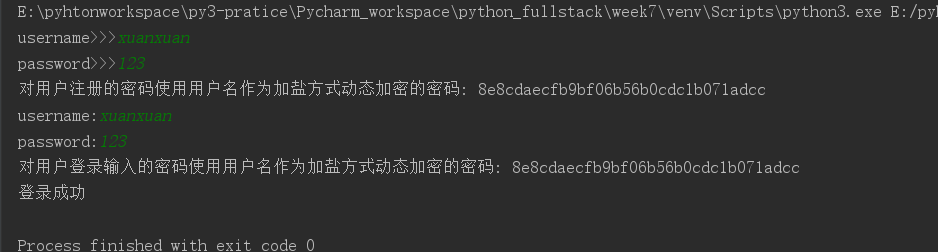
import hashlib # 使用动态加盐方式模拟用户注册,把用户名和加密后的密码写入文件 username=input("username>>>") password=input("password>>>") with open("info1",'w',encoding='utf-8') as file: md5=hashlib.md5(bytes(username,encoding='utf-8')) # 动态加盐,使用用户名加盐 md5.update(bytes(password,encoding='utf-8')) # 这才是对密码进行加密 md5_salt=md5.hexdigest() file.writelines((username,"|",md5_salt)) # 把用户名和动态加盐方式加密后的密码写进文件 print("对用户注册的密码使用用户名作为加盐方式动态加密的密码:",md5_salt) # 模拟用户登陆,将密码使用相同的动态加盐方式加密,将加密后的结果和原来存入文件时的加密后的密码进行比对 usm=input("username:") pwd=input("password:") with open("info1",'r',encoding='utf-8') as file: for line in file: username,password=line.split("|") # 存入文件的用户名和密码(使用动态加盐加密的) md5=hashlib.md5(bytes(usm,encoding='utf-8')) # 使用相同的动态加盐方式 md5.update(bytes(pwd,encoding='utf-8')) # 对输入的密码进行加密 md5_salt=md5.hexdigest() print("对用户登录输入的密码使用用户名作为加盐方式动态加密的密码:",md5_salt) if username==usm and password==md5_salt: print("登录成功") else: print("登录失败")
运行结果:
2. hashlib的md5摘要算法在对密码等进行加密时(使用update)可以多次update
import hashlib md5=hashlib.md5() md5.update(bytes("xuan",encoding='utf-8')) md5.update(bytes("xuan",encoding='utf-8')) #对同一个字符串xuanxuan 分两次update,每次只update一部分 print(md5.hexdigest()) md5_2=hashlib.md5() md5_2.update(bytes("xuanxuan",encoding='utf-8')) # 和对xuanxuan字符串进行一次update print(md5_2.hexdigest())
运行结果:

所以对同一个字符串进行一个update 和拆开每次只update其中的一部分,分多次update得到的加密后的结果是一样的~
我们在进行文件一致性校验时,因为文件太大,就可以每次都一部分,把读到的一部分进行update,然后分多次update,跟一下读所有内容(字符串)进行一次update加密后的结果是一样的~
3. 对一个文件进行多次摘要算法,多次update计算出这个文件的md5值
import hashlib md5=hashlib.md5() # 得到一个使用md5摘要算法的对象md5 with open("info",'r',encoding='utf-8') as file: for line in file: # 每次只读一行,然后对一行内容(字符串)进行update ,分多次update 和把文件所有内容一下读出来进行一次update得到的加密后的结果是一样的 if line: print(line.strip()) # 打印每一行的内容 md5.update(bytes(line.strip(),encoding='utf-8')) # md5对象不断调用update方法,一行一行读文件内容,一行一行update加密(算上之前读到的内容一起加密) print(md5.hexdigest()) # 到此行为止(算上前面读到的内容)读到的文件中内容的加密方式 print(md5.hexdigest()) # 将多次update()后的加密结果打印(其实得到的是整个文件的md5值)
运行结果:
