k折交叉验证
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
#加载iris数据集
iris = load_iris()
X = iris.data
y = iris.target
#分割数据并
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=4)
#建立模型
knn = KNeighborsClassifier()
#训练模型
knn.fit(X_train, y_train)
#将准确率打印出
print(knn.score(X_test, y_test))
# 0.973684210526
#加入交叉验证CV
from sklearn.model_selection import cross_val_score
#使用k折交叉验证
scores = cross_val_score(knn, X, y, cv=5, scoring='accuracy')
print scores
"""
[ 0.96666667 1. 0.93333333 0.96666667 1. ]
"""
print scores.mean()
"""
0.973333333333
"""
#用准确率来判断分类模型的好坏
import matplotlib.pyplot as plt
#建立测试参数集
k_range = range(1, 31)
k_scores = []
#迭代不同的参数对模型的影响, 并返回交叉验证后的平均准确率
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, X, y, cv=10, scoring='accuracy')
k_scores.append(scores.mean())
plt.plot(k_range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated Accuracy')
plt.show()
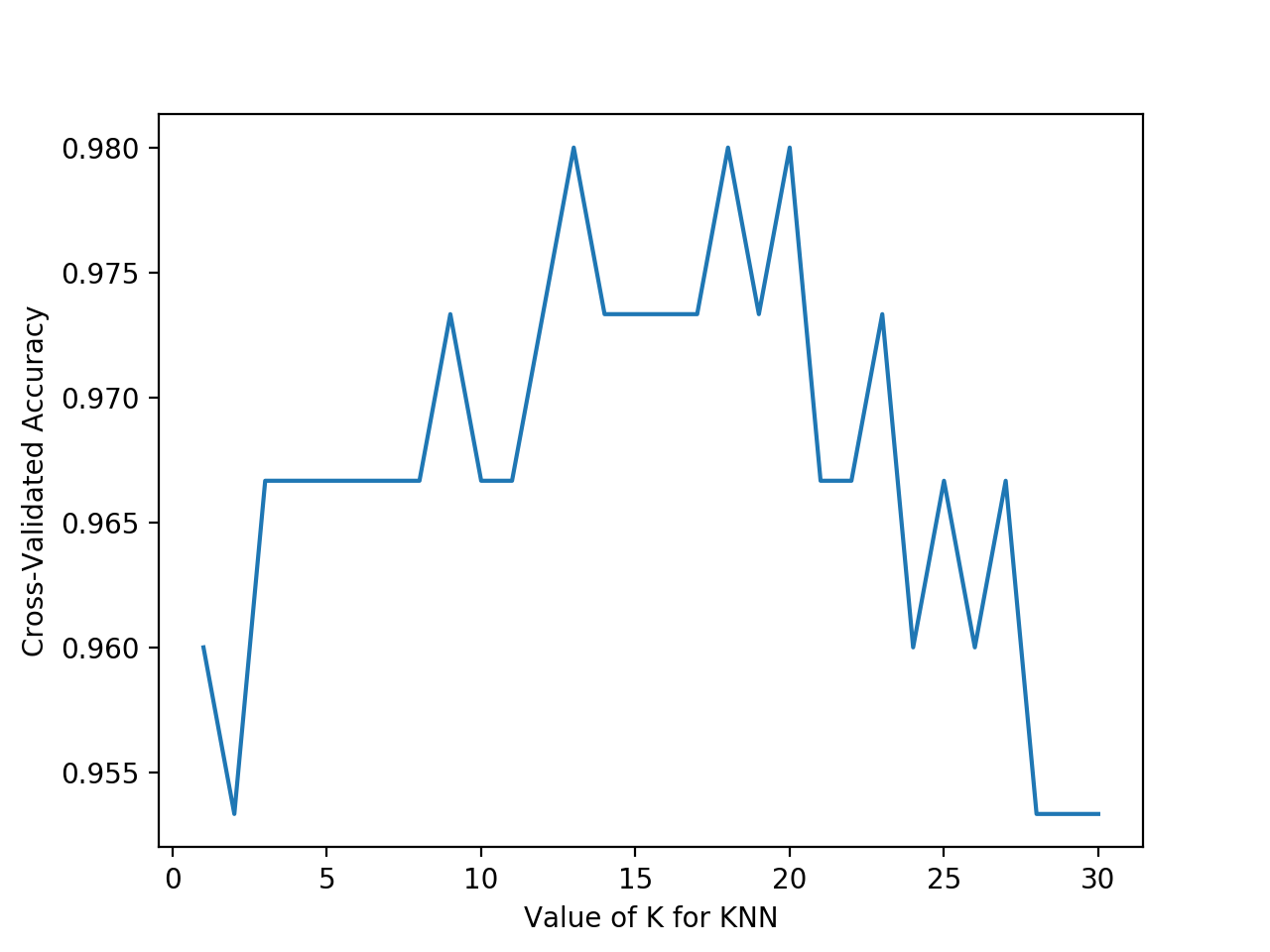
验证损失函数对模型好坏的评价
#选择模型参数,MSE做损失函数
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
loss = -cross_val_score(knn, X, y, cv=10, scoring='neg_mean_squared_error')
k_scores.append(loss.mean())
plt.plot(k_range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated MSE')
plt.show()
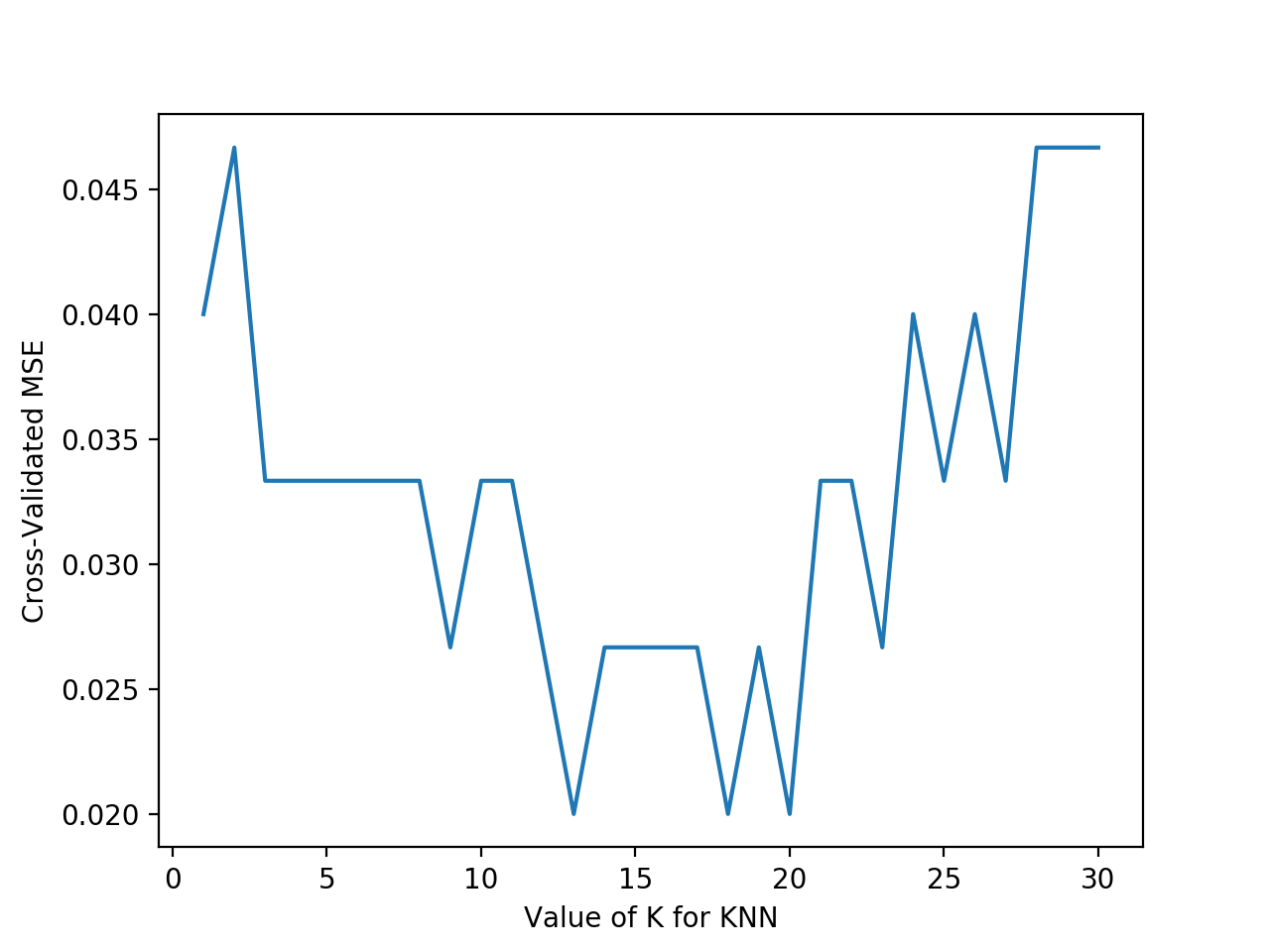
由图可以得知,平均方差越低越好,因此选择13~18左右的K值会最好。