Kafka 扮演的3个重要的角色
|
消息中间件
|
系统解耦:上游系统A成功后,需要发送消息到下游BCD;需要嵌入BCD的接口;
解耦A系统成功后就直接把消息放到KafKa中;
BCD系统再去Kafka中去拿
|
削峰填谷:
系统在某些时段,请求量暴增几十倍,可以添加服务器,平时请求很少,增加了就没有发挥真正用处,只在很少时候排上用场;
在服务器很少的时候,将暴增的请求暂存到kafka中,服务器按照合适的速度一个个从kafka中处理请求;达到服务器稳定
|
异步调用:系统A调动B3s,B调用C2s,C调用D50s;
上面是一个调用链路A确认调用成功需要花,55s;
实际只需要A-C即可,C调用D可以之后处理,因为业务上没有紧密的关联性,时间长,所以分开;
B调用C后成功即返回,告诉A处理中,并且存储一个消息到kafka;
C在从kafka中取出据,调用D成功后,告诉A成功;
例子:
叮咚买菜,下单后,付完款,将消息放到kafka,通知客户下单成功,处理中,中台系统从kafka取数据,为这个订单找一个送货小哥(C调用D),找到后,告诉客户小哥位置;
|
|
数据存储
|
是以硬盘存储的,持久化;
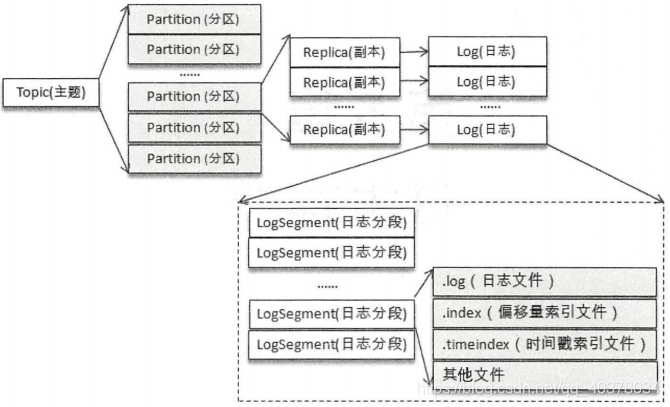
一主题下多分区,保证高效率
分区多副本,保证可靠性
|
|
|
|
流系统的支持
|
|
|
|
kafka中,有broker(主题topic,分区partion,副本),producer生产者,consumer消费者,consumer-group消费组,zookeeper;
broker节点,代表kafka服务端,kafka集群中的一个节点,一台服务器可能对应一个节点,也可能对应多个节点(不同端口);
主题topic,每个主题对应多个分区,可以设置的,一个分区有多个副本,一主多从,主副本leader副本,其他的副本follower副本,
每个leader分区副本应该均衡的分布在 brokerlist上;
|
主题
|
生产者发送需要指定主题;
消费者需要订阅主题
逻辑概念;
|
1个
|
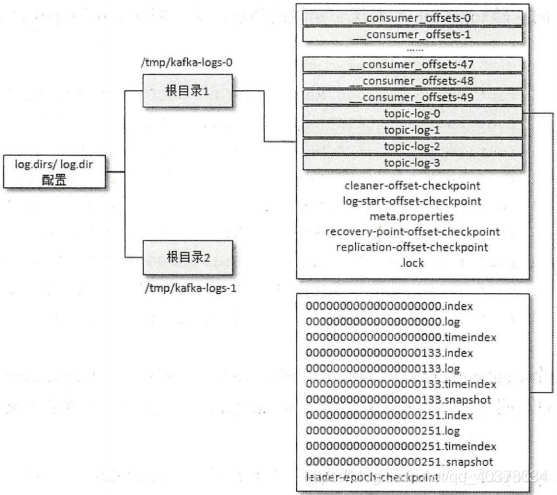
默认有一个consumer_offset主题用来记录各个主题的偏移量提交记录
|
|
分区
|
消息的二次分类,逻辑概念
|
1个主题1或多个分区
|
|
|
分区副本
|
多副本机制,每个分区对应多个副本;
leader副本读写,follower副本负责和leader保持一致;
逻辑概念
|
一个leader副本,其余的都是follower副本
|
leader副本在的机器是leader节点,其余的是follower节点;
AR 所有副本所在节点的broker-id
ISR 和leader副本保持一定同步程度的,是根据一个设定时间,来判断;
OSR,副本的最新时间,大于设定的时间,和leader副本差异过大;
AR = ISR+OSR;
|
|
日志文件
|
物理概念
消息会以追加的形式存到log中持久化
|
一个主题A对应一个A目录,
A目录下有日志文件,3个文件为一组,分别是时间索引文件,偏移量索引文件,log日志文件,命名则是 起始偏移量.log
|
|