https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
Beautiful Soup 4.4.0 文档¶
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据,查看文档
https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
1、学会网络爬虫的三大基本步骤:网络请求、数据解析、数据存储。
2、学会突破一些经典的反爬措施比如:IP代理、验证码识别、JS加密等。
3、学会如何编写高灵活性、高可维护性的爬虫程序。
设计】
一个完整的爬虫程序,无论大小,总体来说可以分成三个步骤,分别是:
- 网络请求:模拟浏览器的行为从网上抓取数据。
- 数据解析:将请求下来的数据进行过滤,提取我们想要的数据。
- 数据存储:将提取到的数据存储到硬盘或者内存中。比如用mysql数据库或者redis等。
那么本课程也是按照这几个步骤循序渐进的进行讲解,带领学生完整的掌握每个步骤的技术。另外,因为爬虫的多样性,在爬取的过程中可能会发生被反爬、效率低下等。因此我们又增加了两个章节用来提高爬虫程序的灵活性,分别是:
- 爬虫进阶:包括IP代理,多线程爬虫,图形验证码识别、JS加密解密、动态网页爬虫、字体反爬识别等。
- Scrapy和分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫等。
通过爬虫进阶的知识点我们能应付大量的反爬网站,而Scrapy框架作为一个专业的爬虫框架,使用他可以快速提高我们编写爬虫程序的效率和速度。另外如果一台机器不能满足你的需求,我们可以用分布式爬虫让多台机器帮助你快速爬取数据。
Python爬虫-数据提取-BeautifulSoup4
- Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能
- 它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序
- Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
常用数据提取工具的比较
- 1.正则:很快,不好用,不需要安装
https://blog.csdn.net/qq_40147863/article/details/82181151 - 2.lxml:比较快,使用简单,需要安装
https://blog.csdn.net/qq_40147863/article/details/82192119 - 3.BeautifulSoup4(建议):慢,使用简单,需要安装
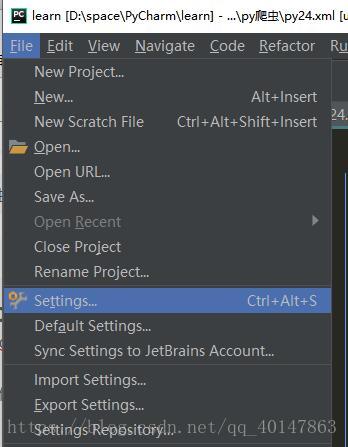
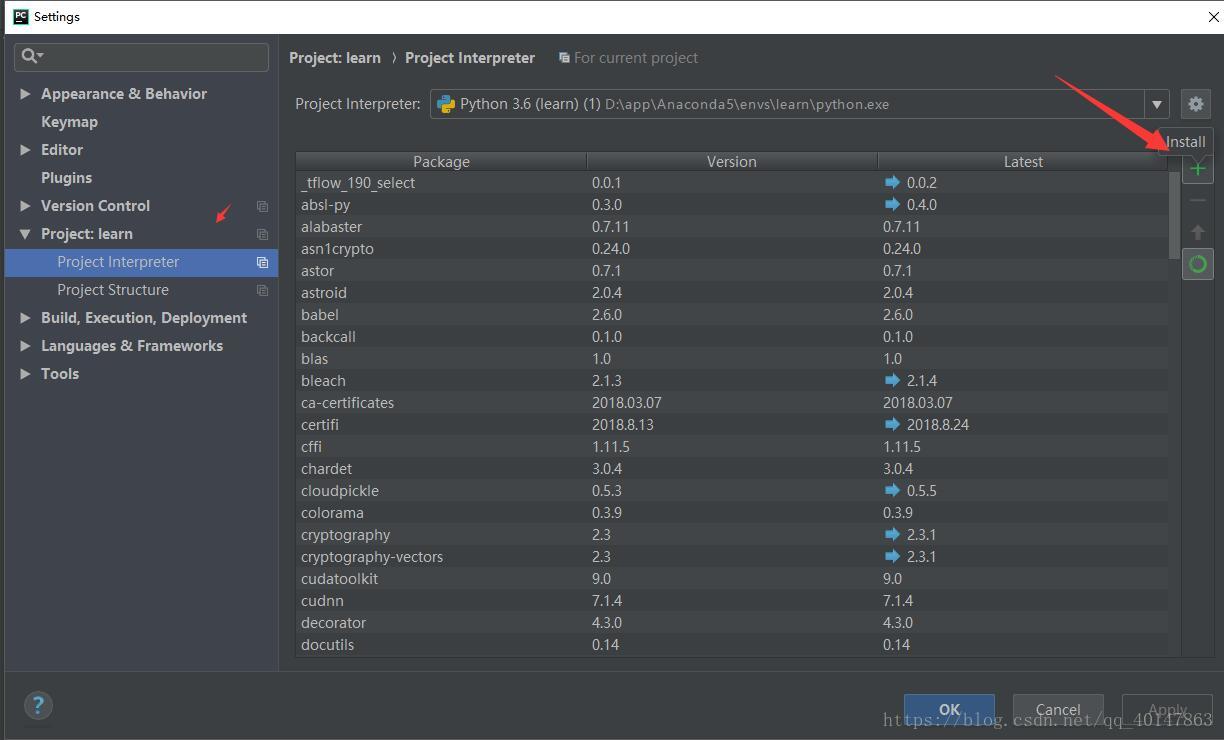
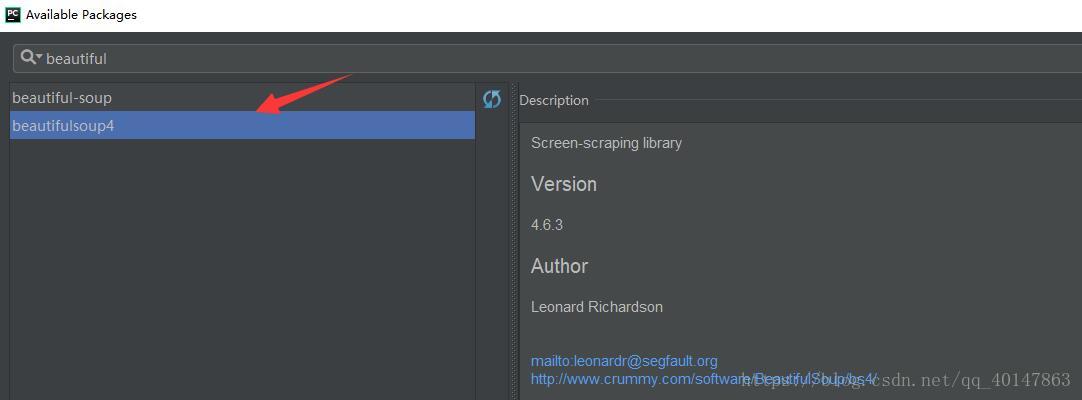
BeautifulSoup4 的安装
- 【PyCharm】>【file】>【settings】>【Project Interpreter】>【+】 >【BeautifulSoup4】>【install】
- 具体操作截图:
BeautifulSoup 的简单使用案例
# BeautifulSoup 的使用案例
from urllib import request
from bs4 import BeautifulSoup
url = 'http://www.baidu.com/'
rsp = request.urlopen(url)
content = rsp.read()
soup = BeautifulSoup(content, 'lxml')
# bs 自动解码
content = soup.prettify()
print(content)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
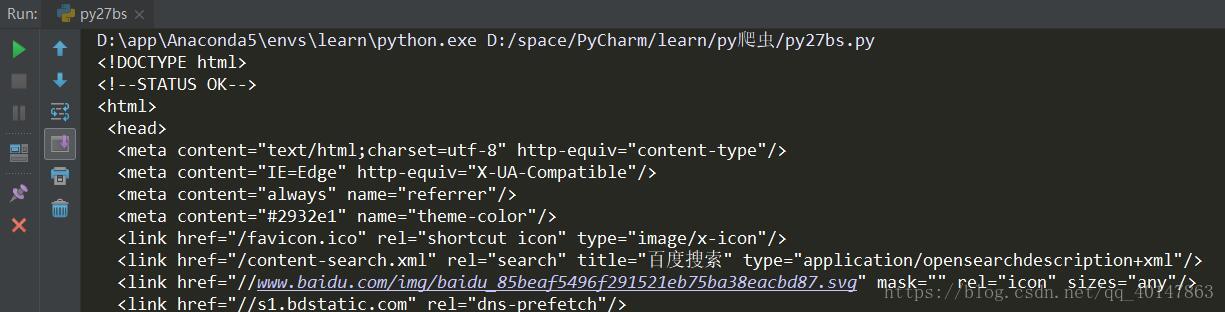
运行结果
BeautifulSoup 四大对象
- 1.Tag
- 2.NavigableString
- 3.BeautifulSoup
- 4.Comment
(1)Tag
- 对应HTML中的标签
- 可以通过soup.tag_name(例如:soup.head;soup.link )
- tag 的属性:
- name :例:soup.meta.name(对应下面案例代码)
- attrs :例:soup.meta.attrs
- attrs[‘属性名’]:例:soup.meta.attrs[‘content’]
- 案例代码27bs2.py文件:https://xpwi.github.io/py/py%E7%88%AC%E8%99%AB/py27bs2.py
# BeautifulSoup 的使用案例
from urllib import request
from bs4 import BeautifulSoup
url = 'http://www.baidu.com/'
rsp = request.urlopen(url)
content = rsp.read()
soup = BeautifulSoup(content, 'lxml')
# bs 自动解码
content = soup.prettify()
# 虽然原文中有多个 meta 但是使用 soup.meta 只会打印出以第一个
print("soup.meta:
", soup.meta)
print("=="*12)
print("soup.meta.name:
",soup.meta.name)
print("=="*12)
print("soup.meta.attrs:
",soup.meta.attrs)
print("=="*12)
print("soup.meta.attrs['content']:
",soup.meta.attrs['content'])
# 当然我们也可以对获取到的数据进行修改
soup.meta.attrs['content'] = 'hahahahaha'
print("=="*5, "修改后","=="*5)
print("soup.meta.attrs['content']:
",soup.meta.attrs['content'])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
运行结果
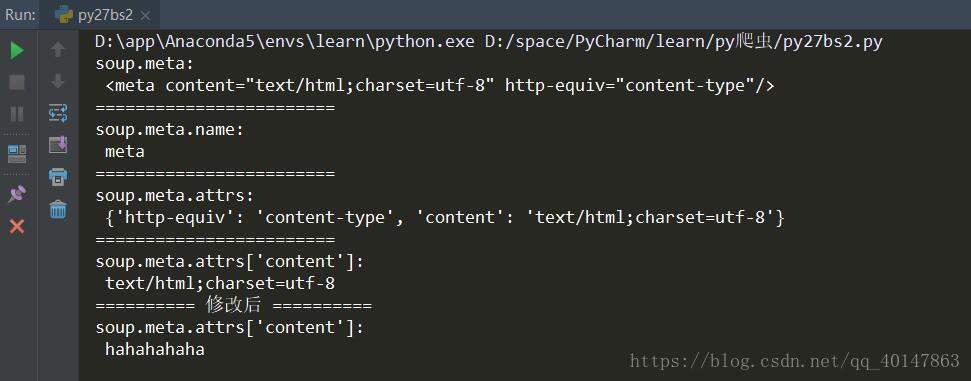
这里结果我们看到,只有一个 meta 标签,而源文档有多个,不是出错,而是这里使用 soup.meta 这种方式,只会打印出以第一个,也就是说数据提取时,1次匹配成功即退出
怎样打印多个 meta 标签呢?使用遍历的方式,具体代码写在下一篇
(2)NavigableString
- 对应内容值
(3)BeautifulSoup
- 表示的是一个文档的内容,大部分可以把它当做 tag 对象
- 不常用
(4)Comment
- 特殊类型的 NavigableString 对象
- 对其输出,则内容不包括注释符号
爬虫网络请求方式:urllib(模块), requests(库), scrapy, pyspider(框架)
爬虫数据提取方式:正则表达式, bs4, lxml, xpath, css
测试HTML代码:

首先导入
from bs4 import BeautifulSoup序列化HTML代码
# 参数1:序列化的html源代码字符串,将其序列化成一个文档树对象。
# 参数2:将采用 lxml 这个解析库来序列化 html 源代码html = BeautifulSoup(open('index.html', encoding='utf-8'), 'lxml')开始查找标签和属性
获得HTML的title和a标签
print(html.title)
print(html.a)获取一个标签的所有(或一个)属性
#示例标签a: {'href': '/', 'id': 'result_logo', 'onmousedown': "return c({'fm':'tab','tab':'logo'})"}
print(html.a.attrs)
print(html.a.get('id'))
获取多个标签,需要遍历文档树
print(html.head.contents)
# print(html.head.contents)是list_iterator object
for ch in html.head.children:
print(ch)
查找后代(desceants)标签
# descendants(后代)
print(html.head.descendants)获取标签内所有文本,包含子标签:get_text()
print(html.select('.two')[0].get_text())根据标签名查找一组元素:find_all()
res = html.find_all('a')
print(res)查找一个元素:find()
find(name, attrs, recursive, text, **wargs) # recursive 递归的,循环的
这些参数相当于过滤器一样可以进行筛选处理。不同的参数过滤可以应用到以下情况:
- 查找标签,基于name参数
- 查找文本,基于text参数
- 基于正则表达式的查找
- 查找标签的属性,基于attrs参数
- 基于函数的查找
#可以传递任何标签的名字来查找到它第一次出现的地方。找到后,find函数返回一个BeautifulSoup的标签对象。
producer_entries = soup.find('ul')
print(type(producer_entries))
输出结果: <class 'bs4.element.Tag'>
#直接字符串的话,查找的是标签。如果想要查找文本的话,则需要用到text参数。如下所示:
producer_string = soup.find(text = 'plants')
print(plants_string)select支持所有的CSS选择器语法:select()
res = html.select('.one')[0]
print(res.get_text())
print(res.get('class'))
res = html.select('.two')[0] print(res) print('----',res.next_sibling) #next_sibling:下一个兄弟标签