在上一篇了解了关于 docker 的网络模型后,本篇就基于上一篇的基础来实现 docker 的跨主机通信。
注:环境为 CentOS7,docker 19.03。
本篇会尝试使用几种不同的方式来实现跨主机方式
环境准备
准备两台或以上的主机或者虚拟机,相关环境如下:
- 主机1:配置两张网卡 br0 192.168.10.10,ens33桥接br0,ens37(不需要IP),docker环境
- 主机2:配置两张网卡 br0 192.168.10.11,ens33桥接br0,ens37(不需要IP),docker环境
桥接方式
网络拓扑图如图
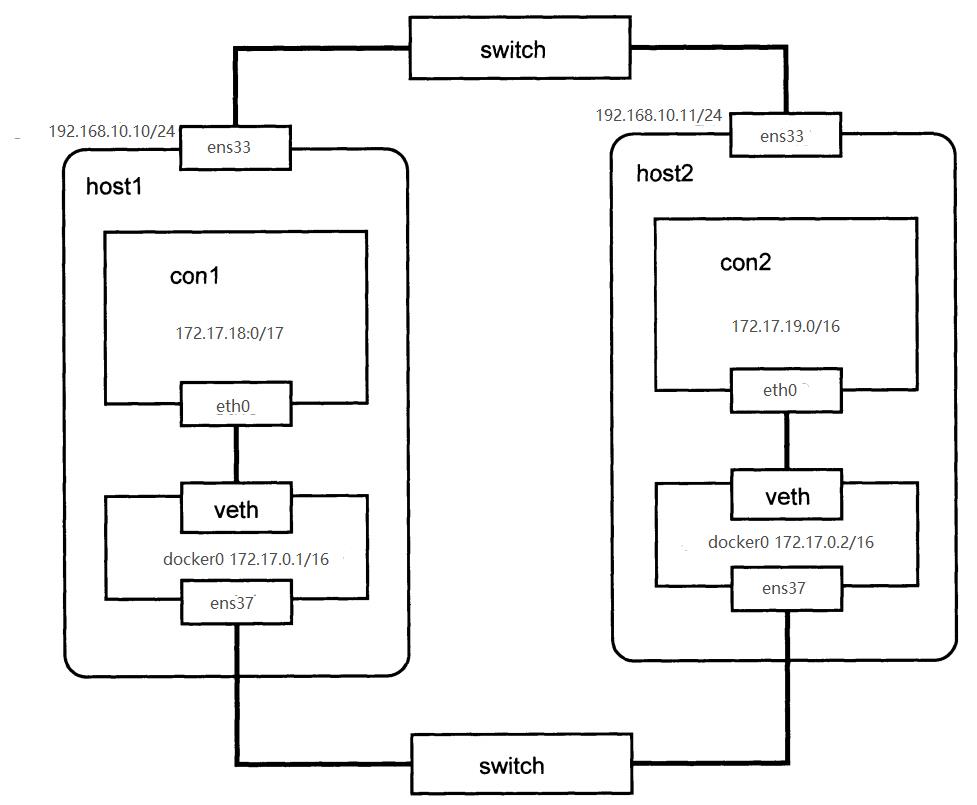
ens33 作为外部网卡,使 docker 容器可以和外部通信,ens37 作为内部网卡,和 docker0 桥接(所以不需要IP)让不同的主机间的容器可以相互通信。配置如下:
主机1上的配置
1.修改 docker 的启动参数文件 /etc/docker/daemon.json 并重启 docker daemon
# vim /etc/docker/daemon.json
{
"bip": "172.17.0.1/16",
"fixed-cidr": "172.17.18.1/24"
}
# systemctl restart docker
2.将 ehs33 网卡接入到 docker0 网桥中
# brctl addif docker0 ens37
3.添加容器con1
# docker run -it --rm --name con1 buysbox sh
主机2上的配置
1.修改 docker 的启动参数文件 /etc/docker/daemon.json 并重启 docker daemon
# vim /etc/docker/daemon.json
{
"bip": "172.17.0.2/16",
"fixed-cidr": "172.17.19.1/24"
}
# systemctl restart docker
2.将 ehs33 网卡接入到 docker0 网桥中
# brctl addif docker0 ens37
3.添加容器con2
# docker run -it --rm --name con1 busybox sh
这时容器 con1 和 con2 既能彼此通信,也可以访问外部IP。
容器con1向容器con2发送数据的过程是这样的:首先,通过查看本身的路由表发现目的地址和自己处于同一网段,那么就不需要将数据发往网关,可以直接发给con2,con1通过ARP广播获取到con2的MAC地址;然后,构造以太网帧发往con2即可。此过程数据中docker0网桥充当普通的交换机转发数据帧。
直接路由
直接路由方式是通过在主机中添加静态路由实现。例如有两台主机host1和host2,两主机上的Docker容器是独立的二层网络,将con1发往con2的数据流先转发到主机host2上,再由host2转发到其上的Docker容器中,反之亦然。
注:这个实现失败!!!
直接路由的网络拓扑图如下:

host1上
1.配置 docker0 ip
# vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://dhq9bx4f.mirror.aliyuncs.com"],
"bip": "172.17.1.254/24"
}
# systemctl restart docker
2.添加路由,将目的地址为172.17.2.0/24的包转发到host2
# route add -net 172.17.2.0 netmask 255.255.255.0 gw 192.168.10.11
3.配置iptables规则
# iptables -t nat -F POSTROUTING
# iptables -t nat -A POSTROUTING s 172.17.1.0/24 ! -d 172.17.0.0/16 -j MASQUERADE
4.打开端口转发
# echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf
5.启动容器con1
# docker run -it --name --rm --name con1 busybox sh
host2上
# vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://dhq9bx4f.mirror.aliyuncs.com"],
"bip": "172.17.2.254/24"
}
# systemctl restart docker
2.添加路由,将目的地址为172.17.1.0/24的包转发到host1
# route add -net 172.17.1.0 netmask 255.255.255.0 gw 192.168.10.10
3.配置iptables规则
# iptables -t nat -F POSTROUTING
# iptables -t nat -A POSTROUTING s 172.17.2.0/24 ! -d 172.17.0.0/16 -j MASQUERADE
4.打开端口转发
# echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf
5.启动容器con2
# docker run -it --name --rm --name con2 busybox sh
以上介绍的两种跨主机通信方式简单有效,但都要求主机都在同一个局域网中。
OVS 划分 VLAN
VLAN(Virtual Local Area Network)即虚拟局域网,按照功能、部门等因素将网络中的机器进行划分,使之属于不同的部分,每一个部分形成一个虚拟的局域网络,共享一个单独的广播域,从而避免因一个网络内的主机过多而产生的广播风暴问题。
VLAN如何在一个二层网络中区分不同流量呢?IEEE 的802.1q协议规定了VLAN的实现方法,即在传统的以太网帧中在添加一个VLAN tag字段,用于标识不同的VLAN。这样,支持VLAN的交换机在转发帧时,不仅会关注MAC地址,还会考虑到VLAN tag字段。VLAN tag中包含TPID、PCP、CFI、VID,其中VID(VLAN ID)部分用来具体指出帧属于哪个VLAN。VID占12为,所以取值范围为0到4095。

交换机有两种类型的端口access端口和trunk端口。图中,Port1、Port2、Port5、Port6、Port8为access端口,每个access端口都会分配一个VLAN ID,标识它所连接的设备属于哪一个VLAN。当数据帧从外界通过access端口进入交换机时,数据帧原本是不带tag的,access端口给数据帧打上tag(VLAN ID即为access端口所分配的VLAN ID);当数据帧从交换机内部通过access端口发送时,数据帧的VLAN ID必须和access端口的VLAN ID一致,access端口才接收此帧,接着access端口将帧的tag信息去掉,再发送出去。Port3,Port4为trunk端口,trunk端口不属于某个特定的VLAN,而是交换机和交换机之间多个VLAN的通道。trunk端口声明了一组VLAN ID,表明只允许带有这些VLAN ID的数据帧通过,从trunk端口进入和出去的数据帧都是带tag的(不考虑默认VLAN的情况)。PC1和PC3属于VLAN100,PC2和PC4属于VLAN200,所以PC1和PC3处于同一个二层网络中,PC2和PC4处于同一个二层网络中。尽管PC1和PC2连接在同一台交换机中,但它们之间的通信时需要经过路由器的。
VLAN tag又是如何发挥作用的呢?当PC1向PC3发送数据时,PC1将IP包封装在以太帧中,帧在目的MAC地址为PC3的地址,此时帧并没有tag信息。当帧到达Port1是,Port1给帧打上tag(VID=100),帧进入switch1,然后帧通过Port3,Port4到达Switch2(Port3、Port4允许VLAN ID为100、200的帧通过)。在switch2中,Port5所标记的VID帧相同,MAC地址也匹配,帧就发送到Port5中,Port5将帧的tag信息去掉,然后发给PC3。由于PC2、PC4于PC1的VLAN不同,因此收不到PC1发出的帧。
单主机docker容器的VLAN划分
docker默认网络模式下,所有容器都连在docker0网桥上。docker0网桥是普通的Linux网桥,不支持VLAN功能,这里就使用Open vSwitch代替。
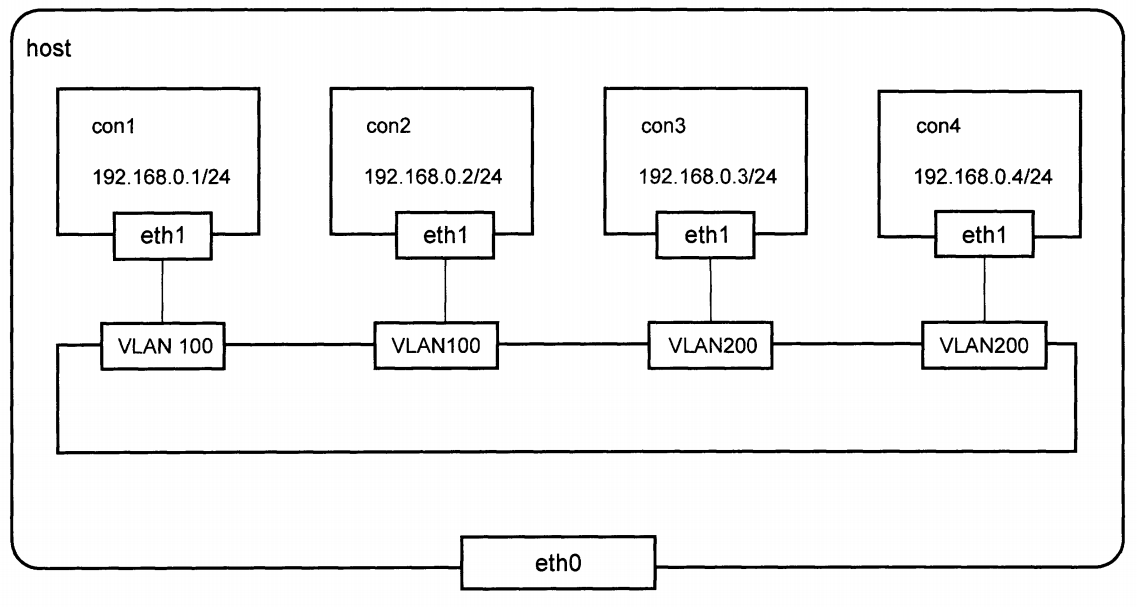
接下来我们就来尝试在主机1上实现图中的效果:
1.在主机上创建4个 docker 容器 con1、con2、con3、con4。
# docker run -itd --name con1 busybox sh
# docker run -itd --name con2 busybox sh
# docker run -itd --name con3 busybox sh
# docker run -itd --name con4 busybox sh
2.下载open vswitch,并启动
# yum install -y openvswitch
# systemctl start openvswitch
3.使用pipework将con1、con2划分到一个VLAN中
# pipework ovs0 con1 192.168.0.1/24 @100
# pipework ovs0 con2 192.168.0.2/24 @100
4.使用pipework将con3、con4划分到一个VLAN中
# pipework ovs0 con3 192.168.0.3/24 @200
# pipework ovs0 con4 192.168.0.4/24 @200
这样一来con1和con2,con3和con4就也是互相通信,但con1和con3是互相隔离的。
使用Open vSwitch配置VLAN,创建access端口和trunk端口的命令如下:
# ovs-vsctl add port ovs0 port1 tag=100
# ovs-vsctl add port ovs0 port2 trunk=100,200
多主机docker容器的VLAN划分

# host1上
# docker run -itd --net=none --name con1 busybox sh
# docker run -itd --net=none --name con2 busybox sh
# pipework ovs0 con1 192.168.0.1/24 @100
# pipework ovs0 con2 192.168.0.2/24 @200
# ovs-vsctl add-port ovs0 eth1
# host2上
# docker run -itd --net=none --name con3 busybox sh
# docker run -itd --net=none --name con4 busybox sh
# pipework ovs0 con3 192.168.0.3/24 @100
# pipework ovs0 con4 192.168.0.4/24 @200
# ovs-vsctl add-port ovs0 eth1
OVS隧道模式
使用VLAN来隔离docker容器网络有多方面的限制:
- VLAN是在二层帧上,要求主机在同个网络中
- VLAN ID只有12比特单位,可用的数量只有4000多个
- VLAN配置较繁琐。
因此现在比较普遍的解决方式为Overlay虚拟化网络技术。
Overlay技术模型
Overlay网络也就是隧道技术,它将一种网络协议包装在另一种协议中传输。隧道被广泛应用于连接因使用不同网络而被隔离的主机和网络,使用隧道技术搭建的网络就是所谓的Overlay网络,它能有效地覆盖在基础网络上。在传输过程中,将以太帧封装在IP包中,通过中间地因特网,最后传输到目的网络中再解封装,这样来保证二层帧头再传输过程中不改变。在多租户情况下,就采用不同租户不同隧道地方式进行隔离。
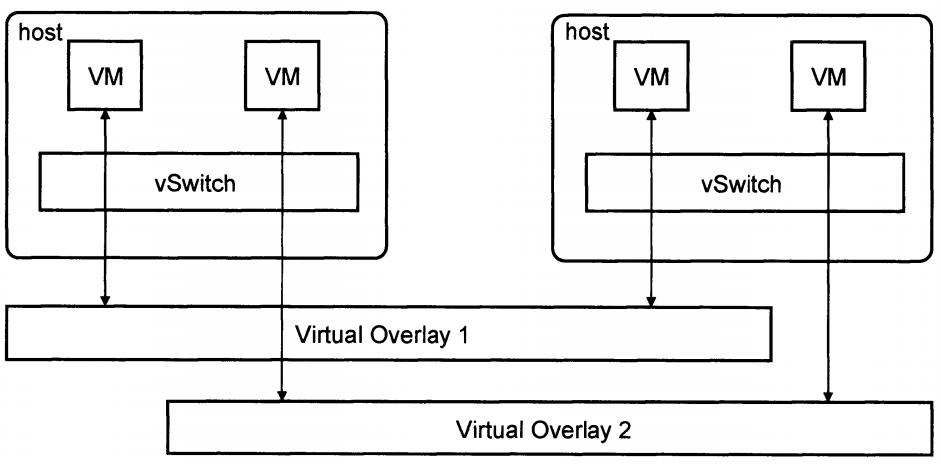
目前Overlay技术有VXLAN(Virtual Extensible LAN)和NVGRE(Network Virtualization using Generic Routing Encapsulation)。VXLAN是将以太网报文封装在UDP传输层上地一种隧道转发模式,它采用24位比特标识二层网络分段,称为VNI(VXLAN Network Idenfier),类似于VLAN ID地作用。NVGRE同VXLAN类似,它使用GRE方法来打通二层与三层之间的通路,采用24位比特的GRE key来作为网络标识(TNI)。
GRE简介
NVGRE使用GRE协议来封装需要传送的数据。GRE协议可以用来封装其他网络层的协议。
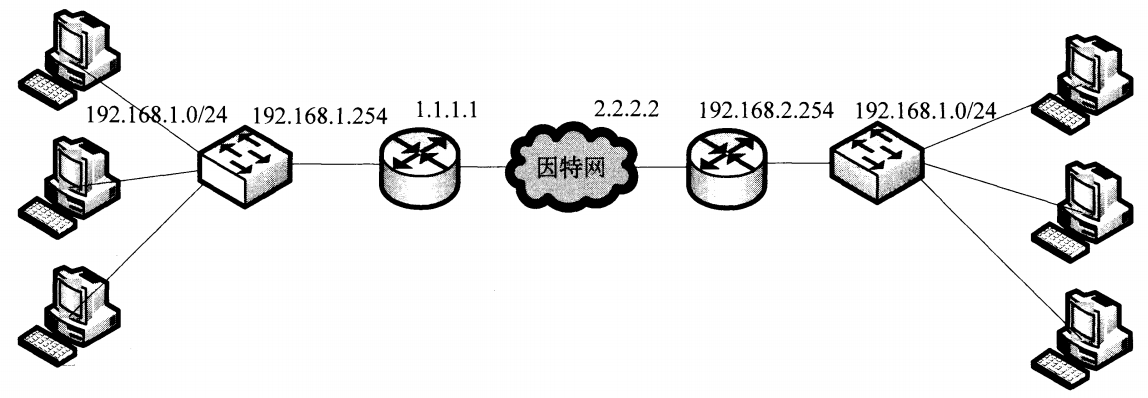
如图的网络如何通信呢?通过在双方路由器上配置GRE隧道实现。从IP地址为192.168.1.1/24的主机A ping IP地址为192.168.2.1/24的主机B中,主机A构造好IP包后,通过查看路由表发现目的地址和本身不在同一个子网中,要将其转发到默认网关192.168.1.254上。主机A将IP包封装在以太网帧中,源MAC地址为本身网卡的MAC地址,目的MAC地址为网关的MAC地址。
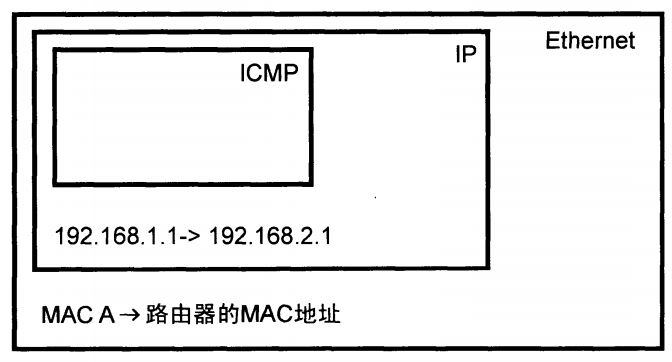
网关路由器收到数据帧后,去掉帧头,将IP取出,匹配目的IP地址和自身的路由表,确定包需要从GRE隧道设备发出,这就对这个IP包做GRE封装,即加上GRE协议头部。封装完成后,该包是不能直接发往互联网的,需要生成新的IP包作为载体来运输GRE数据包,新IP包的源地址为1.1.1.1,目的地址为2.2.2.2。并装在新的广域网二层帧中发出去。在传输过程中,中间的节点仅能看到最外层的IP包。当IP包到达2.2.2.2的路由器后,路由器将外层IP头部和GRE头部去掉,得到原始的IP数据包,再将其发往192.168.2.1。对于原始IP包来说,两个路由器之间的传输过程就如同单链路上的一样。
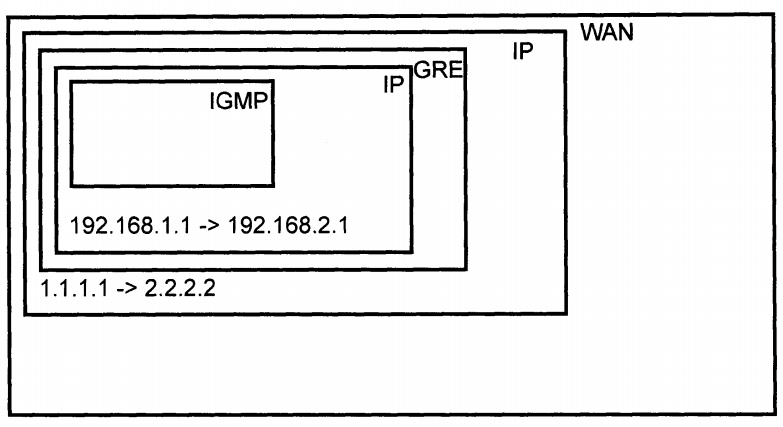
GRE实现 docker 容器跨网络通信(容器在同一子网中)
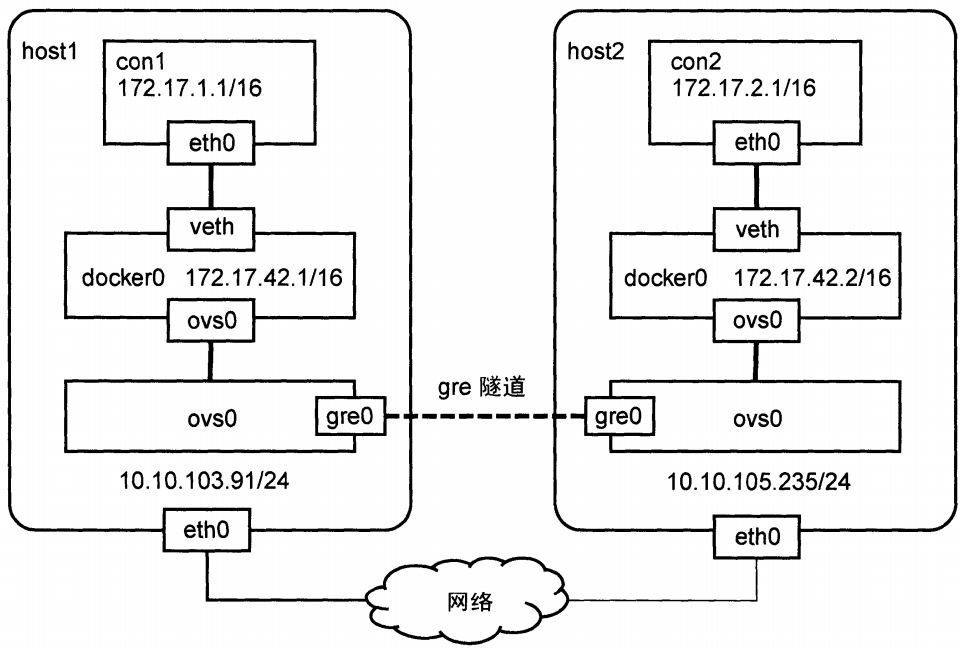
host1上
1.修改docker配置文件
# vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://dhq9bx4f.mirror.aliyuncs.com"],
"bip": "172.17.42.1/16",
"fixed-cidr": "172.17.1.1/24"
}
# systemctl restart docker
2.创建ovs0网桥,并将ovs0连在docker0上
# ovs-vsctl add-br ovs0
# brctl addif docker0 ovs0
3.在ovs0上创建GRE隧道
# ovs-vsctl add-port ovs0 gre0 -- set interface gre0 type=gre options:remote_ip=10.10.105.235
host2上
1.修改docker配置文件
# vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://dhq9bx4f.mirror.aliyuncs.com"],
"bip": "172.17.42.1/16",
"fixed-cidr": "172.17.1.1/24"
}
# systemctl restart docker
2.创建ovs0网桥,并将ovs0连在docker0上
# ovs-vsctl add-br ovs0
# brctl addif docker0 ovs0
3.在ovs0上创建GRE隧道
# ovs-vsctl add-port ovs0 gre0 -- set interface gre0 type=gre options:remote_ip=10.10.105.91
验证
创建容器
# host1上
# docker run -it --rm --name con1 busybox sh
# ping 172.17.2.0
# host2上
# docker run -it --rm --name con2 busybox sh
# ping 172.17.1.0
con1向con2发送数据时,会发送ARP请求获取con2的MAC地址。APR请求会被docker0网桥洪泛到所有端口,包括和ovs0网桥相连的ovs0端口。ARP请求达到ovs0网桥后,继续洪泛,通过gre0隧道端口到达host2上的ovs0中,最后到达con2。host1和host2处在不同网络中,该ARP请求如何跨越中间网络到达host2呢?ARP请求经过gre0时,会首先加上一个GRE协议的头部,然后再加上一个源地址为10.10.105.91、目的地址为10.10.105.235的IP协议头部,再发送给host2。这里GRE协议封装的是二层以太网帧,而非三层IP数据包。con1获取到con2的MAC地址之后,就可以向它发送数据,发送数据包的流程和发送ARP请求的流程类似。只不过docekr0和ovs0会学习到con2的MAC地址该从哪个端口发送出去,而无需洪泛到所有端口。
GRE实现docker容器跨网络通信(容器在不同子网中)

host1上
1.修改docker配置文件
# vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://dhq9bx4f.mirror.aliyuncs.com"],
"bip": "172.17.1.254/16",
"fixed-cidr": "172.17.1.1/24"
}
# systemctl restart docker
2.创建ovs0网桥,并将ovs0连在docker0上
# ovs-vsctl add-br ovs0
# brctl addif docker0 ovs0
3.在ovs0上创建一个internal类型的端口rou0,并分配一个不引起冲突的私有IP
# ovs-vsctl add-port ovs0 rou0 -- set interface rou0 type=internal
# ifconfig rou0 192.168.1.1/24
# 将通往docker容器的流量路由到rou0
# route add -net 172.17.0.0/16 dev rou0
4.在ovs0上创建GRE隧道
# ovs-vsctl add-port ovs0 gre0 -- set interface gre0 type=gre options:remote_ip=10.10.105.235
5.删除并创建iptables规则
# iptables -t nat -D POSTROUTING -s 172.17.0.0/24 ! -o ens33 -j MASQUERADE
# iptables -t nat -A POSTROUTING -s 172.17.0.0/24 ! -o ens33 -j MASQUERADE
host2上
1.修改docker配置文件
# vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://dhq9bx4f.mirror.aliyuncs.com"],
"bip": "172.17.2.254/16",
"fixed-cidr": "172.17.2.1/24"
}
# systemctl restart docker
2.创建ovs0网桥,并将ovs0连在docker0上
# ovs-vsctl add-br ovs0
# brctl addif docker0 ovs0
3.在ovs0上创建一个internal类型的端口rou0,并分配一个不引起冲突的私有IP
# ovs-vsctl add-port ovs0 rou0 -- set interface rou0 type=internal
# ifconfig rou0 192.168.1.1/24
# 将通往docker容器的流量路由到rou0
# route add -net 172.17.0.0/16 dev rou0
4.在ovs0上创建GRE隧道
# ovs-vsctl add-port ovs0 gre0 -- set interface gre0 type=gre options:remote_ip=10.10.103.91
5.删除并创建iptables规则
# iptables -t nat -D POSTROUTING -s 172.17.0.0/24 ! -o eth0 -j MASQUERADE
# iptables -t nat -A POSTROUTING -s 172.17.0.0/24 ! -o eth0 -j MASQUERADE
overlay配合consul实现跨主机通信
环境准备
准备两台或以上的主机或者虚拟机,相关环境如下:
- 主机1:配置两张网卡 ens33 192.168.10.10,docker环境
- 主机2:配置两张网卡 ens33 192.168.10.11,docker环境
- 主机3:consul 环境 192.168.10.12:8500
单通道实现容器互通
在两主机上配置docker启动的配置文件
# vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://dhq9bx4f.mirror.aliyuncs.com"],
"cluster-store": "consul://192.168.10.12:8500",
"cluster-advertise": "ens33:2376"
}
# systemctl restart docker
同样生效的是启动脚本:/etc/systemd/system/docker.service.d/10-machine.conf
[Service]
ExecStart=
ExecStart=/usr/bin/dockerd -H tcp://0.0.0.0:2376 -H unix:///var/run/docker.sock --storage-driver overlay2 --tlsverify --tlscacert /etc/docker/ca.pem --tlscert /etc/docker/server.pem --tlskey /etc/docker/server-key.pem --label provider=generic --cluster-store=consul://192.168.10.12:8500 --cluster-advertise=ens33:2376
Environment=
这个时候,在192.168.10.12:8500的consul上就存储了docker的注册信息了
在主机1上创建网络
# docker network create -d overlay ov-net1
# docker network ls
NETWORK ID NAME DRIVER SCOPE
ce13051e6bff bridge bridge local
ff8cf4a7552a host host local
8514568883d2 none null local
adef0a0c4d39 ov-net1 overlay global
这是我们在主机2上也能看到新建的网络ov-net1,因为ov-net1网络已经存储到consul上,两个主机都可以看到该网络
两个主机上容器
# host1上
# docker run -itd --name con1 --network ov-net1 busybox
# host2上
# docker run -itd --name con2 --network ov-net1 busybox
容器上分别生成两张网卡eth0 10.0.0.2/24,eth1 172.18.0.1/24,eth0连接外部网络,走overlay模式;eth1连接内部网络,连接docker-gwbridge。
overlay网络隔离
那overlay这么实现网络的隔离呢?其实也很简单,就是利用多个overlay网络实现,不同overlay网络之间就存在隔离
# docker network create -d overlay --subnet 10.22.1.0/24 ov-net2
--subnet 参数用来限制分配子网的范围。
# docker run -itd --name con3 --network ov-net2 busybox
# docker exec -it con3 ping 172.18.0.2
PING 172.18.0.2 (172.18.0.2): 56 data bytes
创建容器con3并绑定网络ov-net2,con3不能ping通con1。