一、线性回归
线性回归输出是一个连续值,适用于回归问题。回归问题在实际中很常见,如预测房屋价格、气温、销售额等连续值的问题。与回归问题不同,分类问题中模型的最终输出是一个离散值。我们所说的图像分类、垃圾邮件识别、疾病检测等输出为离散值的问题都属于分类问题的范畴。softmax回归则适用于分类问题。
1.1 线性回归基本要素
模型定义:确定输入要素:输入值X :[X1,X2,X3……Xn] 权重系数 W:[W1,W2,W3……Wn],偏差 b :[b1,b2……bm]
例: 设房屋的面积为 x1x_1x1,房龄为 x2x_2x2,售出价格为 yyy。我们需要建立基于输入 x1x_1x1 和 x2x_2x2 来计算输出 yyy 的表达式,也就是模型(model)。顾名思义,线性回归假设输出与各个输入之间是线性关系:
其中 w1和 w2 是权重(weight),b 是偏差(bias),且均为标量。它们是线性回归模型的参数(parameter)。模型输出 y_hat 是线性回归对真实价格 yyy 的预测或估计。
1.2 模型训练
(1)确定模型
(2)数据来源:Sample包括 features和labels
(3)损失函数:线性回归采用平方损失(square loss):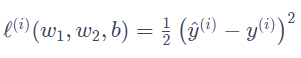
用训练数据集中所有样本误差的平均来衡量模型预测的质量,即:
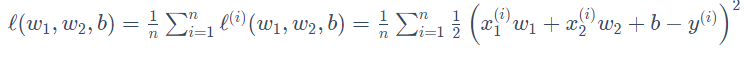
(4)算法优化:
在求数值解的优化算法中,小批量随机梯度下降(mini-batch stochastic gradient descent)在深度学习中被广泛使用。它的算法很简单:先选取一组模型参数的初始值,如随机选取;接下来对参数进行 多次迭代,使每次迭代都可能降低损失函数的值。在每次迭代中,先随机均匀采样一个由固定数目训练数据样本所组成的小批量(mini-batch)B,然后求小批量中数据样本的平均损失有关模型参数的导数(梯度),最后用此结果与预先设定的一个正数的乘积作为模型参数在本次迭代的减小量。
在训练本节讨论的线性回归模型的过程中,模型的每个参数将作如下迭代:
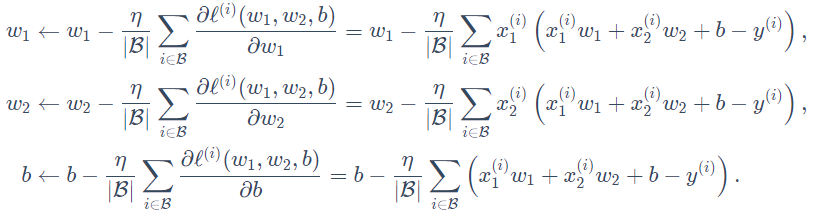

二、线性回归实现
2.1 确定模型
输入因素features的个数(X1, X2)
输出因素个数(y_hat)
权重weight(2 X 1)W1 W2
样本个数num_samples
偏差bais
2.2 数据集生成
模拟一个数据生成,其中输入因素采用的标准正态分布,偏差采用均值0,标准差0.01的正态分布:
1 num_inputs = 2 2 num_samples = 1000 3 num_outputs = 1 4 5 bais_true = 4.2 6 weight_true = torch.tensor([[2],[-3.4]]) 7 features = torch.randn(num_samples,num_inputs,dtype=torch.float) 8 #labels_1 = features[:,0]*weight_true[0]+features[:,1]*weight_true[1]+bais_true 9 labels = torch.mm(features,weight_true)+bais_true 10 print(features[:,1].numpy()) 11 print(labels.numpy()) 12 plt.scatter(features[:,0].numpy(),labels.numpy(),10, c='b') 13 plt.scatter(features[:,1].numpy(),labels.numpy(),10, c='g') 14 plt.show()
2.3 数据读取:
小批量读取样本,流程:随机打乱样本方法是获取样本下标,按照下表读取数据,记住批量读取数据,防止最后下标溢出需要使用min函数
1 def data_iter(batch_size,features,labels): 2 indices = list(range(num_samples)) 3 random.shuffle(indices) 4 for i in range(0,num_samples,batch_size): 5 j = torch.LongTensor(indices[i:min(i+batch_size,num_samples)]) 6 yield features.index_select(0, j), labels.index_select(0, j)
2.4 初始化模型参数
模型参数即:权重,偏差
1 # 赋0值 2 b = torch.zeros(dtype=torch.float,size=labels.size(),requires_grad=True) 3 # 正态分布 4 w = torch.tensor(np.random.normal(0,0.01,size=(num_inputs,1)),dtype=torch.float,requires_grad=True)
2.5 定义模型
1 def net(x,w,b): 2 return torch.mm(x,w)+b
2.6 损失函数
1 def squred_loss(y_hat,y): 2 return 1/2*(y_hat-y.view(y_hat.size()))**2
2.7 算法优化
1 def sgd(params, lr, batch_size): 2 for param in params: 3 param.data -= lr * param.grad / batch_size
2.8 训练
1 lr = 0.03 2 num_epochs = 10 3 loss = squred_loss 4 batch_size = 100 5 def train_mode(num_epochs,batch_size,lr,features, labels): 6 for epoch in range(num_epochs): 7 train_l = 0.0 8 for X, y in data_iter(batch_size, features, labels): 9 y_hat = net(X, w, b) 10 l = loss(y_hat, y).sum() 11 12 l.backward() 13 14 sgd([w, b], lr, batch_size) 15 w.grad.data.zero_() 16 b.grad.data.zero_() 17 train_l += l 18 print('epoch %d ,loss %.4f' % (epoch + 1, train_l)) 19 print(f'权重weight:{w},偏差bais{b}') 20
运行结果:
1 epoch 1 ,loss 12566.5957 2 权重weight:tensor([[ 0.4546], 3 [-0.8807]], requires_grad=True),偏差baistensor([1.0837], requires_grad=True) 4 epoch 2 ,loss 6957.7007 5 权重weight:tensor([[ 0.8132], 6 [-1.5377]], requires_grad=True),偏差baistensor([1.8875], requires_grad=True) 7 epoch 3 ,loss 3851.4001 8 权重weight:tensor([[ 1.0897], 9 [-2.0230]], requires_grad=True),偏差baistensor([2.4836], requires_grad=True) 10 epoch 4 ,loss 2135.0503 11 权重weight:tensor([[ 1.3029], 12 [-2.3814]], requires_grad=True),偏差baistensor([2.9259], requires_grad=True) 13 epoch 5 ,loss 1184.0327 14 权重weight:tensor([[ 1.4670], 15 [-2.6463]], requires_grad=True),偏差baistensor([3.2539], requires_grad=True) 16 epoch 6 ,loss 657.1237 17 权重weight:tensor([[ 1.5928], 18 [-2.8424]], requires_grad=True),偏差baistensor([3.4973], requires_grad=True) 19 epoch 7 ,loss 364.7702 20 权重weight:tensor([[ 1.6891], 21 [-2.9873]], requires_grad=True),偏差baistensor([3.6781], requires_grad=True) 22 epoch 8 ,loss 202.5418 23 权重weight:tensor([[ 1.7629], 24 [-3.0945]], requires_grad=True),偏差baistensor([3.8123], requires_grad=True) 25 epoch 9 ,loss 112.5923 26 权重weight:tensor([[ 1.8194], 27 [-3.1738]], requires_grad=True),偏差baistensor([3.9119], requires_grad=True) 28 epoch 10 ,loss 62.5563 29 权重weight:tensor([[ 1.8625], 30 [-3.2325]], requires_grad=True),偏差baistensor([3.9859], requires_grad=True)
调整参数 lr = 0.04 ,迭代40次即可。