第一篇:初识Redis
一、Redis是什么?
Redis 是一个开源(BSD许可)的,使用ANSI C语言编写的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如:字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动分区(Cluster)提供高可用性(high availability)。
二、Redis的八大特性
1、速度快
Redis是使用C语言编写的基于内存型的单线程数据库,相比于基于磁盘型的数据库要快很多,官方给出的数据每秒支持10W次的读写操作。
2、持久化
Redis的持久化可以保证将内存中的数据每隔一段时间就保存在磁盘中,重启的时候会重新加载到内存中。持久化方式有RDB和AOF。(后面的章节会详细介绍RDB和AOF)
3、支持多种数据结构
Redis支持五种基础数据类型:String(字符串)、(Hash)哈希、(List)列表、(Set)集合、(Sorted Set)有序集合。
我们可以用一张图形象的描述下Redis支持的基础数据结构
衍生的数据结构:
BitMaps:位图(用于活跃用户数统计等)
HyperLogLog:超小内存唯一值计数
GEO:地理信息定位
4、支持多种编程语言
支持Java、PHP、Python、Ruby、Lua、Nodejs。
5、功能丰富
支持发布订阅、Lua脚本、事物、Pipeline(管道,即当指令到达一定数量后,客户端才会执行)
6、简单
不依赖外部库、单线程、只有23000行的Code。
7、支持主从复制
主节点的数据做副本、这是做高可用的基石。
8、高可用、分布式
Redis-Sentinel(v2.8)支持高可用、Redis-Cluster(v3.0)支持分布式。
三、Redis典型应用场景
1、缓存系统
一般在开发中经常被使用的Redis缓存可以分为两大类,一是热点数据缓存,二是权限认证信息缓存。
热点数据缓存:对经常会被查询,但是不经常被修改或者删除的数据缓存,例如:商品的分类、用户的基本信息、组织架构信息、全页缓存等。
Session共享:PHP默认Session是保存在服务器的文件中,如果是集群服务,同一个用户过来可能落在不同机器上,这就会导致用户频繁登陆,采用Redis保存Session后,无论用户落在那台机器上都能够获取到对应的Session信息。
API防重放:为了防止接口被非法用户截取用于重放攻击,重放攻击是什么呢?就是把你的请求原封不动地再发送一次,两次...n次,一般正常的请求都会通过验证进入到正常逻辑中,为了防止重放我们一般用Redis缓存记录第一次访问,如果该请求被截获,发生第二次请求则视为非法请求,一般防重放和URL签名一起使用,后续章节里会告诉大家具体如何实现。
2、计数器/限速器
命令:INCRBY
由于INCRBY的自增是原子性的,可以避免并发问题,保证不会出错,而且100%毫秒级性能。
计数器:可以统计类似用户点赞数、用户访问数、文章转发数、视频播放数、评论数等,这类操作如果用MySQL实时的读写会给数据库带来相当大的压力,一般先放到Redis中用脚本程序定时去回写MySQL;
限速器:比较典型的使用场景是限制某个用户访问某个API的频率
例如:
1、抢购时,防止用户疯狂点击带来不必要的压力;
2、用户登陆时需要让用户输入手机验证码,从而确定是否是用户本人,但是为了短信接口不被频繁访问,会限制用户每分钟获取验证码的频率,例如一小时内不能超过5次。
3、排行榜
有序集合比较典型的使用场景就是排行榜系统,例如视频网站需要对用户上传的视频做排行榜,榜单的维度可能是多个方面的:按照时间、按照播放数量、按照获得的赞数。
排行版的场景关键在于怎么拼接score,score是double类型的,我们可以利用这点,组装一个浮点数,整数部分是热度的值,小数部分是时间,这里要注意的是,Redis里面精度应该是小数6位。
4、消息队列
除了Redis自身的发布/订阅模式,我们也可以利用List来实现一个队列机制,比如:到货通知、邮件发送之类的需求,不需要高可靠,但是会带来非常大的DB压力,完全可以用List来完成异步解耦;
5、社交网络
利用集合的一些命令特点,比如求交集、并集、差集等,可以方便搞定一些共同好友、共同爱好之类的功能;
6、位操作(大数据处理)
用于数据量上亿的场景下,例如几亿用户系统的签到,去重登录次数统计,某用户是否在线状态等等。
想想一下10亿用户,要几个毫秒内查询到某个用户是否在线,你能怎么做?千万别说给每个用户建立一个key,然后挨个记(你可以算一下需要的内存会很恐怖,而且这种类似的需求很多,腾讯光这个得多花多少钱。。)好吧。这里要用到位操作——使用setbit、getbit、bitcount命令。
原理是:
Redis内构建一个足够长的数组,每个数组元素只能是0和1两个值,然后这个数组的下标index用来表示我们上面例子里面的用户id(必须是数字哈),那么很显然,这个几亿长的大数组就能通过下标和元素值(0和1)来构建一个记忆系统,上面我说的几个场景也就能够实现。
7、SETNX实现分布式锁
现在分布式的应用场景很多,为了保持数据的一致性,经常碰到需要对资源加锁的情形, 利用Redis单线程的特点实现分布式锁就是其中的一种实现方案。
利用SETNX的特性,很容易的想到,在需要加锁的时候,调用SETNX命令,如果返回了1,表示设置成功,获得了当前锁,之后做一些想要的操作,完成之后调用DEL命令释放锁。
8、秒杀时避免超卖
要解决“超卖”问题,核心在于保证检查库存时的操作是依次执行的,形象的说就是把“多线程”转成“单线程”。即使有很多用户同时到达,也是一个个检查并给与抢购资格,一旦库存抢尽,后面的用户就无法继续了。
我们需要使用Redis的原子操作来实现这个“单线程”。首先我们把库存存在goods:1这个列表中,假设有10件库存,就往列表中push10个数,这个数没有实际意义,仅仅代表一件库存。抢购开始后,每到来一个用户,就从goods:1中pop一个数,表示用户抢购成功。当列表为空时,表示已经被抢光了。因为列表的pop操作是原子的,即使有很多用户同时到达,也是依次执行的。
四、 Redis和Memcached对比
1、Memcached所有的值均是简单的字符串,Redis支持更为丰富的数据类型
2、Redis可以持久化其数据
3、 Redis支持数据的备份,即master-slave模式的数据备份。
4、使用底层模型不同,它们之间底层实现方式 以及与客户端之间通信的应用协议不一样。Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
5、Redis单个value的最大限制是1GB,而Memcached则只能保存1MB内的数据。
6、 Memcache在并发场景下,能用cas保证一致性,而Redis事务支持比较弱,只能保证事务中的每个操作连续执行。
7、 Memcached的内存管理不像Redis那么复杂,元数据metadata更小,相对来说额外开销就很少。Memcached唯一支持的数据类型是字符串string,非常适合缓存只读数据,因为字符串不需要额外的处理。
简单介绍:
主从模式
主从模式的应用场景有点类似于数据库的主从集群,主从往往是为了读写分离、backup 等目的才使用的,所谓主从模式简单的说就是有多个节点,里面包含主节点和从节点,结构如下图:
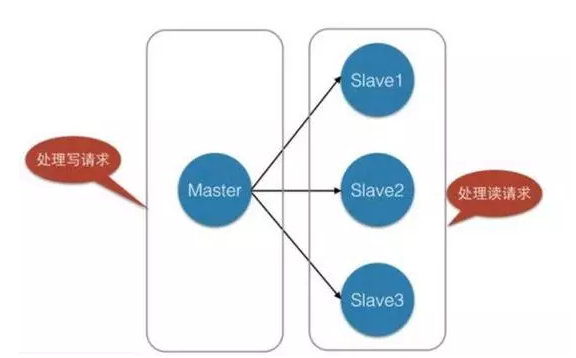
从节点在保持连接后每隔一个时间节点会主动的和主节点通信并发送同步请求,而后进行同步。
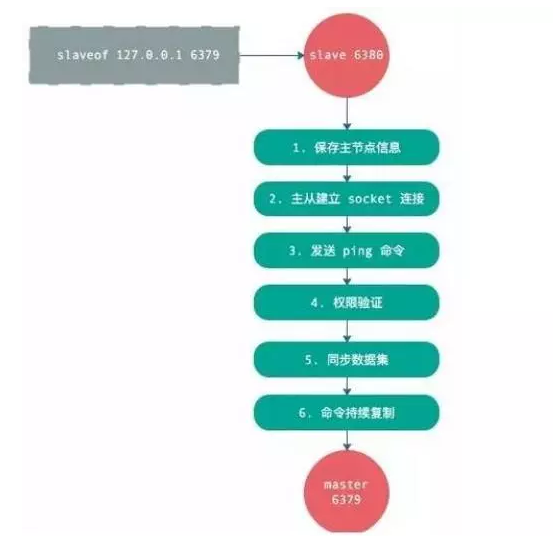
其实在整个流程中,最需要主要的就是数据间的同步,主要的同步方式有两种也就是全量同步和增量同步。
全量同步:全量同步一般使用在从节点刚接入主节点时进行全量复制,当然你也可以根据你的需求进行主动的全量同步
增量同步:Redis增量复制是指从节点初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令,一般使用缓冲区、队列(先进先出)等方式辅助进行增量的同步。
哨兵模式
哨兵模式是为了保证redis的高可用产生的架构,简单地说就是通过构建1个或多个哨兵对节点进行监控,如果master发生故障下线之后,哨兵之间会进行投票,在2.8之后使用的是Raft算法进行master选举,关于这个算法其实这个算法也应用于zookeeper和某些网络拓扑中,简单说就是在选举的过程可通信节点达成共识后那个投票选举master,而后进行故障转移操作。
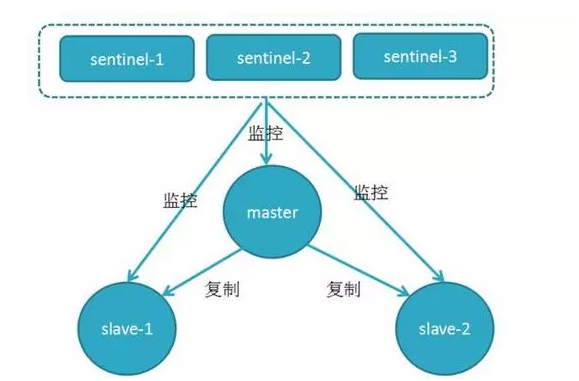
哨兵是作为一个进程单独运行在redis中,哨兵之间也是通过该进程进行通信的,这一点和zookeeper的原理也是类似的,假设一个6节点3个哨兵的集群的结构应该如下图:
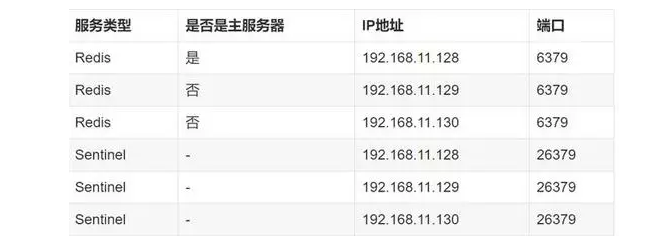
那么哨兵是如何监控master下线的呢?
前面也有看到哨兵之间会进行集群的检测和哨兵之间的互相监测,但是哨兵不用做什么配置,因为哨兵巧妙的利用了master的发布/订阅机制去自动发现其它也监控了统一master的sentinel节点,在监测master方面一般分为两种:
主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断。
客观下线(Objectively Down, 简称 ODOWN)指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断, 并且通过命令互相交流之后, 得出的服务器下线判断。一个 Sentinel 可以通过向另一个 Sentinel 发送命令来询问对方是否认为给定的服务器已下线。
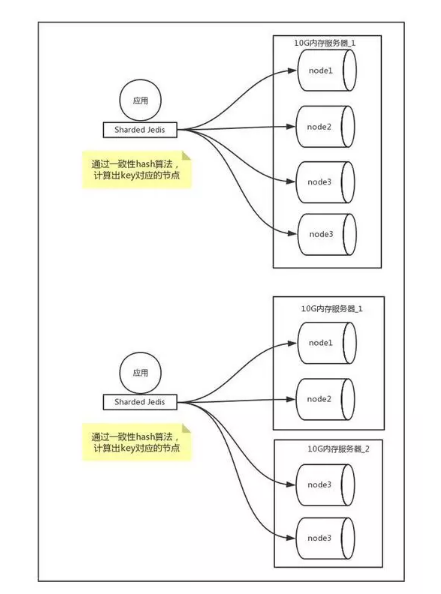
分片集群
在上面的部分不管redis主从,还是高可用的 sentinel 哨兵模式。我们所做的这些工作只是保证了数据备份以及高可用,目前为止我们的程序一直都是向1台redis写数据,其他的redis只是备份而已。在实际使用中一般分片集群使用较多,我为什么要特意强调是分片集群呢,其实上面所说的主从和哨兵都是集群但是他们都是备份式的集群,实际数据是由一台进行控制的,所谓分片其实是将不同的数据按照一定的分布规则分布在不同的机器上

在redis中,我们的应用在存取数据的时候需要根据一定的算法(一致性hash)进行计算和存取 ,那么在redis中如何实现数据分片的呢? 首先Redis至少存在三个数据分片,每个分片称为master,假设整个cluster有N个节点,那么每个节点都和其他N-1个节点保持连接和心跳,节点之间相互通信主要确认节点是否存活、节点的数据版本、投票选择新的master等

那么我们最终的集群结构大致如下: