一、程序在内存中被执行的过程
流程说明
1、操作系统把物理硬盘代码load到内存
2、操作系统把c代码分成四个区
3、操作系统找到main函数入口执行
二、四区的说明
一个由c/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack):由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式同数据结构中的栈(FILO)。
2、堆区(heap: 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。
(需要malloc-free;new-delete;new[]-delete[])
3、数据区:主要包括静态全局区和常量区,如果要站在汇编角度细分的话还可以分为很多小的区。
全局区(静态区)(static):全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 程序结束后有系统释放
常量区 :常量字符串就是放在这里的。 程序结束后由系统释放。
4、代码区:存放函数体的二进制代码。
5、内存的物理结构
一般内存四区中的栈的开口方向是向下的。为什么要这样设计呢,因为设计栈的方向向下,可以给应用程序设定栈的大小,这样就可以避免栈溢出。
不管栈是开口向上还是开口向下,BUFF的增长方向都是向上的。可以通过代码测出来。
如果栈的开口方向向下,那么BUFF的基址在下面,如果栈的开口方向向上,BUFF的基址也在下面,也就是说,不管栈的开口方向朝那里,BUFF的基址都在下面
三、函数调用说明
在操作系统调用main函数的时候,会将main函数的返回地址和参数入栈,然后开始直行main函数,如果在main函数中调用了其他函数,会先将main函数的运行状态入栈,然后将被调用函数的返回值入栈,被调用函数的参数入栈,然后去执行被调用函数,如果还有其他调用函数,过程也是类似的。
在main函数中分配的内存,被调用函数是可以使用的。
main函数可以在栈上,堆上,全局区上进行分配内存,这些内存是可以被函数中被调用函数使用的。
而在被调用函数中栈上分配的内存,不能被主调函数使用,像堆上,还有全局区上分配的内存,都可以供主调函数使用,通过间接赋值的方式将内存的首地址传递出来就可以了。
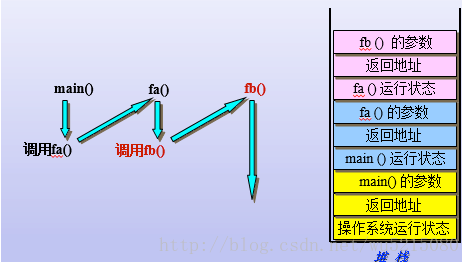
四、总结
1、主调函数分配的内存空间(堆,栈,全局区)可以在被调用函数中使用,可以以指针作函数参数的形式来使用
2、被调用函数分配的内存空间只有堆区和全局区可以在主调函数中使用(返回值和函数参数),而栈区却不行,因为栈区函数体运行完之后内存管理器自动释放。
3、一定要明白函数的主被调关系以及主被调函数内存分配回收