1.源文件转换为可执行文件
源文件经过以下几步生成可执行文件:
- 1、预处理(preprocessor):对#include、#define、#ifdef/#endif、#ifndef/#endif等进行处理
- 2、编译(compiler):将源码编译为汇编代码
- 3、汇编(assembler):将汇编代码汇编为目标代码
- 4、链接(linker):将目标代码链接为可执行文件
编译器和汇编器创建的目标文件包含:二进制代码(指令)、源码中的数据;链接器将多个目标文件链接成一个;装载器吧目标文件加载到内存。
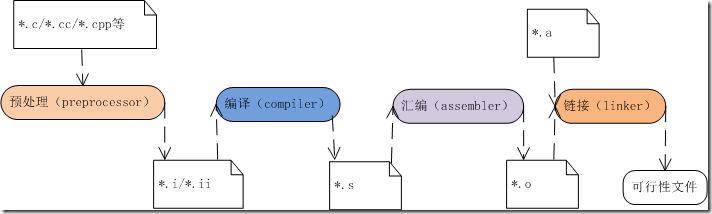
图1 源文件到可执行文件的步骤
2.可执行程序组成及内存布局
通过上面的小节,我们知道将源程序转换为可执行程序的步骤,典型的可执行文件分为两部分:
- 代码段(Code),由机器指令组成,该部分是不可改的,编译之后就不再改变,放置在文本段(.text)。
- 数据段(Data),它由以下几部分组:
- 常量(constant),通常放置在只读read-only的文本段(.text)
- 静态数据(static data),初始化的放置在数据段(.data);未初始化的放置在BSS段(.bss,Block Started by Symbol,BSS段的变量只有名称和大小却没有值)
- 动态数据(dynamic data),这些数据存储在堆(heap)或栈(stack)
源程序编译后链接到一个以0地址为始地址的线性或多维虚拟地址空间。而且每个进程都拥有这样一个空间,每个指令和数据都在这个虚拟地址空间拥有确定的地址,把这个地址称为虚拟地址(Virtual Address)。将进程中的目标代码、数据等的虚拟地址组成的虚拟空间称为虚拟存储器(Virtual Memory)。典型的虚拟存储器中有类似的布局:
- Text Segment (.text)
- Initialized Data Segment (.data)
- Uninitialized Data Segment (.bss)
- The Stack
- The Heap
如下图所示:
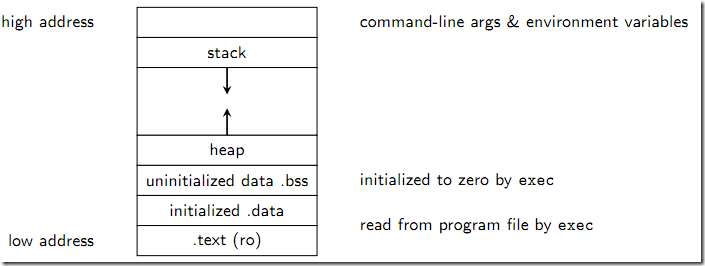
图2 进程内存布局
当进程被创建时,内核为其提供一块物理内存,将虚拟内存映射到物理内存,这些都是由操作系统来做的。
3.数据存储类别
讨论C/C++中的内存布局,不得不提的是数据的存储类别!数据在内存中的位置取决于它的存储类别。一个对象是内存的一个位置,解析这个对象依赖于两个属性:存储类别、数据类型。
- 存储类别决定对象在内存中的生命周期。
- 数据类型决定对象值的意义,在内存中占多大空间。
C/C++中由(auto、 extern、 register、 static)存储类别和对象声明的上下文决定它的存储类别。
3.1 自动对象(automatic objects)
auto和register将声明的对象指定为自动存储类别。他们的作用域是局部的,诸如一个函数内,一个代码块{***}内等。操作了作用域,对象会被销毁。
- 在一个代码块中声明一个对象,如果没有执行auto,那么默认是自动存储类别。
- 声明为register的对象是自动存储类别,存储在计算机的快速寄存器中。不可以对register对象做取值操作“&”。
3.2 静态对象(static objects)
静态对象可以局部的,也可以是全局的。静态对象一直保持它的值,例如进入一个函数,函数中的静态对象仍保持上次调用时的值。包含静态对象的函数不是线程安全的、不可重入的,正是因为它具有“记忆”功能。
- 局部对象声明为静态之后,将改变它在内存中保存的位置,由动态数据--->静态数据,即从堆或栈变为数据段或bbs段。
- 全局对象声明为静态之后,而不会改变它在内存中保存的位置,仍然是在数据段或bbs段。但是static将改变它的作用域,即该对象仅在本源文件有效。此相反的关键字是extern,使用extern修饰或者什么都不带的全局对象的作用域是整个程序。
4.一个实例
下面我们分析一段代码:
1 #include <stdio.h> 2 #include <stdlib.h> 3 4 int a; 5 static int b; 6 7 void func( void ) 8 { 9 char c; 10 static int d; 11 } 12 13 int main( void ) 14 { 15 int e; 16 int *pi = ( int *) malloc ( sizeof ( int )); 17 func (); 18 func (); 19 free (pi ); 20 return (0); 21 }
程序中声明的变量a、b、c、d、e、pi的存储类别和生命期如下所述:
- a是一个未初始化的全局变量,作用域为整个程序,生命期是整个程序运行期间,在内存的bbs段
- b是一个未初始化的静态全局变量,作用域为本源文件,生命期是整个程序运行期间,在内存的bbs段
- c是一个未初始化的局部变量,作用域为函数func体内,即仅在函数体内可见,生命期也是函数体内,在内存的栈中
- d是一个未初始化的静态局部变量,作用域为函数func体内,即仅在函数体内可见,生命期是整个程序运行期间,在内存的bbs段
- e是一个未初始化的局部变量,作用域为函数main体内,即仅在函数体内可见,生命期是main函数内,在内存的栈中
- pi是一个局部指针,指向堆中的一块内存块,该块的大小为sizeof(int),pi本身存储在内存的栈中,生命期是main函数内
- 新申请的内存块在堆中,生命期是malloc/free之间
用图表示如下:
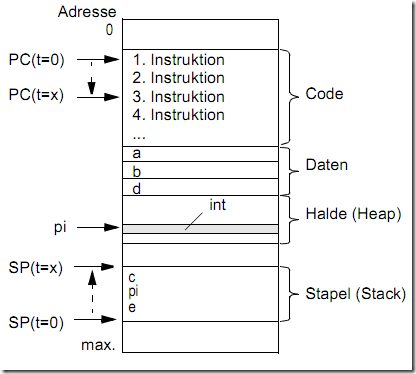
图3 例子的内存布局
综合1~4,介绍了C/C++中由源程序到可执行文件的步骤,和可执行程序的内存布局,数据存储类别,最后还通过一个例子来说明。
可执行程序中的变量在内存中的布局可以总结为如下:
- 变量(函数外):如果未初始化,则存放在BSS段;否则存放在data段
- 变量(函数内):如果没有指定static修饰符,则存放在栈中;否则同上
- 常量:存放在文本段.text
- 函数参数:存放在栈或寄存器中
内存可以分为以下几段:
- 文本段:包含实际要执行的代码(机器指令)和常量。它通常是共享的,多个实例之间共享文本段。文本段是不可修改的。
- 初始化数据段:包含程序已经初始化的全局变量,.data。
- 未初始化数据段:包含程序未初始化的全局变量,.bbs。该段中的变量在执行之前初始化为0或NULL。
- 栈:由系统管理,由高地址向低地址扩展。
- 堆:动态内存,由用户管理。通过malloc/alloc/realloc、new/new[]申请空间,通过free、delete/delete[]释放所申请的空间。由低地址想高地址扩展。
前1~4引自吴秦先生的博文。
作者:吴秦
出处:http://www.cnblogs.com/skynet/
本文基于署名 2.5 中国大陆许可协议发布,欢迎转载,演绎或用于商业目的,但是必须保留本文的署名吴秦(包含链接).
5.内存对齐
5.1 一个例子
先来看一个例子:


1 #include<iostream> 2 using namespace std; 3 4 class test 5 { 6 private: 7 char c = '1'; // 1byte 8 int i; // 4byte 9 short s = 2; // 2byte 10 }; 11 12 int main() 13 { 14 cout << sizeof(test) << endl; 15 return 0; 16 }
输出是12.
1 #include<iostream> 2 using namespace std; 3 4 class test 5 { 6 private: 7 int i; // 4byte 8 char c = '1'; // 1byte 9 short s = 2; // 2byte 10 }; 11 12 int main() 13 { 14 cout << sizeof(test) << endl; 15 return 0; 16 }
输出是8.
我们可以看到,类test和test2的成员变量完全一样,只是定义顺序不一样,却造成了2个类占用内存大小不一样。这就是编译器内存对齐的缘故。
5.2 对齐规则
1、第一个数据成员放在offset为0的地方,以后每个数据成员的对齐按照#pragma pack指定的数值和这个数据成员自身长度中,比较小的那个进行。
2、在数据成员完成各自对齐之后,类(结构或联合)本身也要进行对齐,对齐将按照#pragma pack指定的数值和结构(或联合)最大数据成员长度中,比较小的那个进行。
很明显#pragma pack(n)作为一个预编译指令用来设置多少个字节对齐的。值得注意的是,n的缺省数值是按照编译器自身设置,默认为8。其语法如下:

where:
1 | 2 | 4 | 8 | 16 Members of structures are aligned on the specified byte-alignment, or on their natural alignment boundary, whichever is less, and the specified value is pushed on the stack. nopack No packing is applied, and "nopack" is pushed onto the pack stack pop The top element on the pragma pack stack is popped. (no argument specified) Specifying #pragma pack() has the same effect as specifying #pragma pack(pop).
5.3 例子分析
5.3.1 对于类test的内存空间

内存分配过程:
1)char和编译器默认的内存缺省分割大小比较,char比较小,分配一个字节给它。
2)int和编译器默认的内存缺省分割大小比较,int比较小,占4字节。只能空3个字节,重新分配4个字节。
3)short和编译器默认的内存缺省分割大小比较,short比较小,占2个字节,分配2个字节给它。
4)对齐结束类本身也要对齐,所以最后空余的2个字节也被test占用。
5.3.2 对于类test2的内存空间
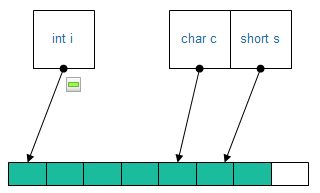
1)int和编译器默认的内存缺省分割大小比较,int比较小,占4字节。分配4个字节给int。
2)char和编译器默认的内存缺省分割大小比较,char比较小,分配一个字节给它。
3)short和编译器默认的内存缺省分割大小比较,short比较小,此时前面的char分配完毕还余下3个字节,足够short的2个字节存储,所以short紧挨着。分配2个字节给short。
4)对齐结束类本身也要对齐,所以最后空余的1个字节也被test占用。
5.3.3 使用#pragma pack(n)
1 #include<iostream> 2 using namespace std; 3 4 #pragma pack(1)//设定为1字节对齐 5 6 class test 7 { 8 private: 9 char c = '1'; //1byte 10 int i; //4byte 11 short s = 2; //2byte 12 }; 13 14 class test2 15 { 16 private: 17 int i; //4byte 18 char c = '1'; //1byte 19 short s = 2; //2byte 20 }; 21 22 int main() 23 { 24 cout << sizeof(test) << endl; 25 cout << sizeof(test2) << endl; 26 return 0; 27 }
输出结果:
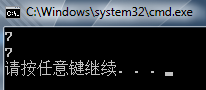
可以看到,当我们把编译器的内存分割大小设置为1后,类中所有的成员变量都紧密的连续分布。
5.4 内存对齐的作用
要严重参考一IBM的文章:Data alignment: Straighten up and fly right,PDF版本可从这里下载得到。
l 平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
l 性能原因:经过内存对齐后,CPU的内存访问速度大大提升。具体原因稍后解释。
图一:

这是普通程序员心目中的内存印象,由一个个的字节组成,而CPU并不是这么看待的。
图二:

CPU把内存当成是一块一块的,块的大小可以是2,4,8,16字节大小,因此CPU在读取内存时是一块一块进行读取的。块大小成为memory access granularity(粒度) 可以把它翻译为“内存读取粒度” 。
假设CPU要读取一个int型4字节大小的数据到寄存器中,分两种情况讨论:
1)数据从0字节开始
2)数据从1字节开始
假设内存读取粒度为4。
图三:

当该数据是从0字节开始时,很CPU只需读取内存一次即可把这4字节的数据完全读取到寄存器中。
当该数据是从1字节开始时,问题变的有些复杂,此时该int型数据不是位于内存读取边界上,这就是一类内存未对齐的数据。
图四:

此时CPU先访问一次内存,读取0—3字节的数据进寄存器,并再次读取4—5字节的数据进寄存器,接着把0字节和6,7,8字节的数据剔除,最后合并1,2,3,4字节的数据进寄存器。对一个内存未对齐的数据进行了这么多额外的操作,大大降低了CPU性能。
这还属于乐观情况了,上文提到内存对齐的作用之一为平台的移植原因,因为以上操作只有有部分CPU肯干,其他一部分CPU遇到未对齐边界就直接罢工了。
5.5 内存对齐对结构体成员变量访问影响
先看下边一小程序:
1 #include <iostream> 2 using namespace std; 3 4 struct MyStruct 5 { 6 int a; 7 int b; 8 int c; 9 }; 10 11 int main() 12 { 13 struct MyStruct myStruct = {1, 2, 3}; 14 15 struct MyStruct *ptr = &myStruct; 16 cout << ptr->a << endl; 17 cout << ptr->b << endl; 18 cout << ptr->c << endl; 19 20 int *pstr = (int *)&myStruct; 21 cout << *pstr << endl; 22 cout << *(pstr + 1) << endl; 23 cout << *(pstr + 2) << endl; 24 25 return 0; 26 }
上边程序中第16~18和第21~23行输出的结果是一样的。但如果我们考虑到字节填充的问题时,采用pstr那种访问方式就不大对了。所以要采用ptr那种访问方式。
6.参考资料
Data alignment: Straighten up and fly right
更多关于C++内存布局请参考: