TF的概念是Term Frequent,是一个单词出现的频率,是一个局部概念,就是这个单词在指定文件中出现的频率,公式如下:
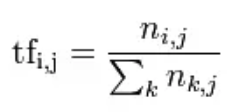
但是呢,这个TF其实很没有说服力,比如the,a之类的频率很高,但是其实不能实现很好地分类标志,尽管可以在停用词中进行禁用,但是很多单词还是无法全部禁用干净;这个时候就引入了IDF,Inverse Document Frequent,反向文档频率(我称之为区分度公式),公式是
idf = log(N/d)
N是文档数量,存在该单词的文档的个数,这里IDF是一个全局概念,是一个单词在全局的分布情况,分布的越少,idf的值越高;IDF实现了"对于出现频率低"的单词赋予比较高的权重,比如"越位",是一个专业术语,一般只是出现在足球相关的文章中,那么,这个词的IDF就会比较大,或者说这个词的区分度会比较大。
TFIDF = TF(t, d) * IDF(t)
这里强调一下,TFIDF是一种评分,TFIDF计算出来的结果是要作为特征值写入到稀疏矩阵的。
下面说一下对于新闻分类的套路;首先是加载所有的新闻训练样本,然后进行分词,将分词(term)放入到一张大表中,这是第一张大表:Term(特征)字典表;Term字典表的形成过程:计算每个Term的TFIDF(看到了,TFIDF是term的,在NPL中,每个term就是一个特征,或者说一个维度);这样就形成了一张key-value表,key就是term的hash值,value就是term的tfidf的值;这里解释一下,所谓的Hash算法,是指对于每个分词进行Hash取值,这个值就是分词的索引;在这个字典表的索引;在文本挖掘里面,每个分词就是特征,对于分词取Hash之后,其实就是特征索引值,然后找到对应的特征做统计;为什么要做这么做?简化流程,否则需要遍历整张表来查找匹配Term;如果采用Hash的方式,取要查找的分词的hansh值,直接过去到了索引,将term的比较转化为了索引值的定位,简化的查询的过程;
第一张字典表有了,下面就是形成第二张大表:样本表;新闻分类是要进行训练的;来了一条样本之后,需要进行分词,然后取各个分词的hash值,拿着hash值到字典表中找对应的tfidf值,然后把tfidf填充到样本表中同字典表索引的位置;如此形成一行;所以一条样本(新闻)其实不会填充几个term,很多单元格都是空着的;如果多条记录之后,形成了什么?形成了稀疏矩阵。
采用hash算法获取索引,那么碰撞了怎么办?所以这张哈希表一定要大,默认的是2.18,分析云用的是2.20
比如"美国",这个特征,取hash值为242,首先到字典表索引242中找到tfidf值;然后在样本(稀疏表)的列索引242的位置设置tfidf值;这样,就形成了一个特征向量(一个稀疏的向量/矩阵)。
train的这些样本都是可以作为未来比较的原始样本;设想新来了一条新闻记录,然后从任意类别中抽出来一个(特征向量),将两个特征向量基于余弦相似度衡量,根据余弦值来判断是否是同类新闻;什么是余弦相似度?
cos(x) = x * y / ||x|| * ||y||
对于稀疏矩阵场景,需要使用余弦定理,对于为0的特征,分子是0,所以适用(不过两者都是0就跪了)
对于新闻场景还可以继续进行训练,就是基于贝叶斯来计算一段文字是某个分类新闻的概率;这个原理就是,计算某段文字中各个单词是每一种分类的概率,然后把这些概率做相乘;那么怎么计算概率呢?这里采用其实是一半贝叶斯公式,我们知道贝叶斯公式如下:
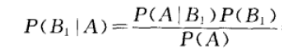
在这里,B代表类别,A代表具体的某个文档(由各个分词组成);在贝叶斯公式中,文档A是分类B的概率的计算是可以转化为P(A1|B) * P(A2|B) * P(A3|B)...*P(B),Ai是文档A的分词;根据条件我们是可以把类别B某个具体分词的概率统计出来,分类B占全局分类的概率P(B)也是可以求出来;对于P(A),因为所有的元素P(A)的概率都是一样的,所以这里可以忽略不记。直接比较分子,谁大,那么谁就是该分类。
在我们日志分析云中并没有采用这种(朴素贝叶斯)方式,因为该方式是应用于分类已经很清晰的场景下;而我们的场景下是会有新的日志类型产生。