机器学习的思路梳理一下:机器学习的分类,分类和预测;分类这里包括逻辑回归,贝叶斯分类,决策树分类,adaboost几种;回归则包括:线性回归,本质是根据样本来推测系数(权重,weight),基于损失函数,不断地调整系数以实现损失函数值最小,说的了损失函数,我们就来讨论一下有哪几类损失函数,因为损失函数本质是为了求解损失函数极值来调整参数值,所以,损失函数主要是用于回归预测;
这里包括sigmod,Gradent,对数;怎么来求解呢?一般采用Gradent,梯度下降的方式来进行求解。但是这里注意了,每种损失函数都是尤其特定的使用场景的,介绍如下。
回归的损失函数包括:
最小均方差(min square equal,L2误差)
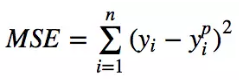
平均绝对值误差(L1误差)
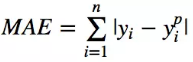
注意,MSE因为是误差的平方,所以对于误差较大的值比较敏感;所以如果训练数据中有比较多的偏差(方差比较大),那么MAE的效果将会比较好;因为如果异常点存在导致“用力过度”,将会导致其他正常的样本训练效果受到影响。但是MSE的优势是偏差大,MSE也大,偏差小,MSE也小,这个在梯度下降的时候非常好用,即使是使用固定的学习率,也可以有比较好的收敛,所以MSE经典实现中都是用MSE来作为损失函数(通过对MSE来进行求导推出公式来进行后续计算)。
这里有一个问题澄清一下,回归并不一定都是预测,回归可以用于分类,比如逻辑回归就是用于分类的,而且上述很多算法都是·预测和分类通吃,比如决策树可以用于分类,可以用于预测。回归的本质是连续,逻辑回归是指自变量和因变量都是连续的,但是根据因变量的范围来判断(二元)分类。关于逻辑回归就要提到了sigmod函数,这个函数实现了基于连续数据的分类,看过了sigmod函数图你就知道为什么它可以分类了。作为一个入门级的分类函数,我们可以把sigmod写成:z = W.T * X,X就是样本,那么下面就是要求解系数矩阵W了,怎么求解W,此时就是用了经典“优化算法”,所谓优化就是指针对W这个系数矩阵的优化(很多人翻译成权重矩阵,理解为针对各个特征求解他们的权重),这个优化的目的就是让基于求解的模型,一定程度的拟合训练样本(不是尽量,否则容易过拟合)。这里最常见的优化算法就是梯度下降。
关于梯度下降还是要单独讲述一下,因为它实在是太重要了。继续上面的话题,我们想要优化W,那么就需要求f(x, y)的极值,求极值用到的就是高等数学里面的偏导数,分别对x和y进行求导,这个过程我们可以想象为几何中的求切线的法线,目标就是不断的接近原点;角度可以通过切线的法线来进行不断的调整,每次进步的大小则是通过学习率来进行设置的。
讲过了梯度下降,梯度下降本质上迭代+最小二乘法,那么我们就来说一下另外一个很重要优化算法:最小二乘法(OLS, Ordinary Least Square)
最小二乘法原理就是,yi = a0xi + a1,那么怎么确定a0和a1呢?OLS认为在尝试a0和a1的过程中,满足真实值(y0)和计算值(y1)差的平方和(即误差/残差平方和)最小的即是a0和a1的最佳值。
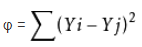
这里备注一下,优化的方法有很多,梯度下降本身就有很多种方法:共轭梯度法和BFGS、L-BFGS,还有经典的极大似然求解等。
svm的分类方式和其他的不太一样,不再是求权重,而是求一个最大宽度,这个最大宽度则是基于SMO算法来求解而得,svm里面采用了拉格朗日的对偶的算法,这个可以介绍如下。
贝叶斯分类方式则是基于概率1角度来计算每种分类的可能性,这个和其他的分类方式又有些不同,贝叶斯求解需要获取先验概率,然后才能够获知后验概率。他的隐喻就是开始的时候知道的局部概率,然后根据局部概率推断出全局概率。
决策树分类方式则是基于特征熵的原理来搞的;总是选择熵值最小的那个列来进行分类,决策树理论认为熵值最高的那一列的区分度是最高的。
关于Adaboost,和其他几个不同,其他几个都是单一分类器,aboost则是集成分类器,他是汇聚多个弱分类器,然后根据训练阶段每个分类器的学习的效果。
因为我们分类搞着搞着,就会面临过拟合问题,这里牵涉到了岭回归。L1,L2都是啥?
那么我们再来聊一聊如何来评估机器学习,ROC,混淆矩阵等,还有那个validate+train曲线都是啥。
作为评估,首先要明白对于样本要进行划分,划分为训练数据以及测试数据;前者负责建立模型,后者用于验证模型;怎么来利用这两类数据,最常见的就是N折交叉验证(N-folder Cross Validation),N一般取值10,即将数据分成10份,所以常用的10折交叉验证。验证的过程就是每次取出不同一份数据作为测试数据,其他9份作为训练数据;所以也称之为“留一法(Leave-One-Out)”。但是在分类中,数据划分要注意,需要使用分层采样法来进行采样,保证被划分的分类能够按照比例划分到每一份中;否则数据不均匀,不能很好的体现数据分布,将会影响训练效果。
ROC曲线也是作为二分类性能的一种度量,横轴是判断为正阳的准确率,纵轴代表判断为阳性的错误率;可以通过ROC曲线来看,主要是评估左上角部分面积程度,因为左上角是理想的状态,准确率高,错误率第。所以有个说法就是AUC(under the curve),AUC的面积越大其实就说明了性能越好。
N折交叉验证法所获得的是一个粗粒度的评估数据,即正确概率;接着可以使用混淆矩阵来进行分类展示。分类矩阵是一个二维表格。横轴代表某类数据被识别的情况,纵轴代表被识别的某个分类的总数量,通过混淆矩阵可以比较清晰的看出来每个分类正确和错误的情况。而且还可以通过混淆矩阵,使用Kappa的算法来对模型进行验证。
但是要注意一点:无论是分类还是预测,所有的算法本质上都是依赖于损失函数,所有的算法都有属于自己的损失函数;尽管使用的方式不同,比如在线性回归过程中通过梯度下降来实现损失函数最小,在Adaboost里面通过损失函数来获取D矩阵,有D矩阵来优化下一迭代里面的权重。所以,理解一个算法,关键就是要理解损失函数。
那么怎么评估拟合呢?这里F值R平方值等手段。下面对于这些统计维度进行说明。
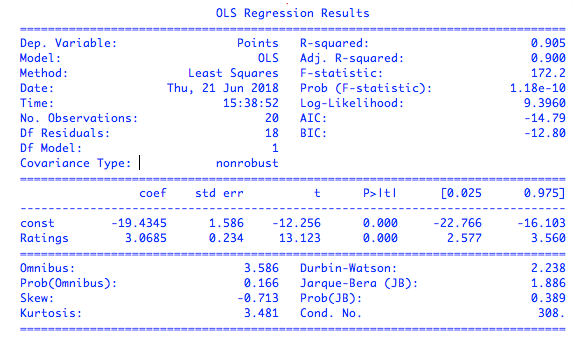
coef:参数的估计值;
std err:标准差,是指观测值和真实值的偏离程度;sqrt(((x1-x)^2 +(x2-x)^2 +......(xn-x)^2)/n);
[0.025 0.975]:代表系数95%的概率会在-22.8到-16.1区间范围内;
t:参数的估计值和原始假设值之间的偏离度,绝对值值越大则说明越可信(原始假设一般都是0);
P:代表数据与原始模型不匹配的程度,P绝对值越小(接近于0)说明和原始模型越不匹配,说明训练得到的模型准确度越高。在多元回归函数中,每个维度都有有自己的P值,那么P值越大的说明他的重要性也越小(因为P值小才说明拟合度高)
R-square(R2):代表x的变化可以被y解释的程度,我们可以理解为是“拟合度”,图中代表可以被解释数据达到了90.5%,其他9%左右可以认为是噪声;
F-statistic:F统计,当P和R之间发生冲突的时候,就需要看F值了,F统计主要用于多元回归上面,F统计值越大,说明拟合度越大,正常拟合度,至少应该过百(过千)。
聊完了分类,我们再来聊聊回归。
下面讲一下特征工程,这个也会统计学类最重要的内容:
参考:
损失函数
https://www.jianshu.com/p/477a8c1cb05d
特征工程