Group by、rollup、cube、grouping sets区别
oracle除了group by基本用法之外,还有ROLLUP,CUBE,GROUPING SETS 等扩展方法,这些可以理解为Group By 分组函数封装后的精简用法,相当于多个union all 的组合显示效果,但是要比 多个 union all 的效率要高。
1.测试数据
CREATE TABLE emp ( ID NUMBER PRIMARY KEY, NAME NVARCHAR2(30), sex VARCHAR2(10), birthday DATE, work_location VARCHAR2(30), sal NUMBER(10) ); COMMENT ON TABLE emp IS '员工信息表'; COMMENT ON COLUMN emp.id IS '员工id'; COMMENT ON COLUMN emp.name IS '员工姓名'; COMMENT ON COLUMN emp.sex IS '性别'; COMMENT ON COLUMN emp.birthday IS '出生日期'; COMMENT ON COLUMN emp.work_location IS '工作地点'; COMMENT ON COLUMN emp.sal IS '工资'; INSERT INTO emp(ID, NAME, sex, birthday, work_location, sal) VALUES(1, '小王','男', to_date('1994-12-08','yyyy-mm-dd'), '杭州', 4500); INSERT INTO emp(ID, NAME, sex, birthday, work_location, sal) VALUES(2, '小瑞','男', to_date('1995-02-01','yyyy-mm-dd'), '杭州', 8000); INSERT INTO emp(ID, NAME, sex, birthday, work_location, sal) VALUES(3, '小倩子','女', to_date('1994-07-08','yyyy-mm-dd'), '上海', 6000); INSERT INTO emp(ID, NAME, sex, birthday, work_location, sal) VALUES(4, '小权','男', to_date('1993-01-01','yyyy-mm-dd'), '北京', 8000); INSERT INTO emp(ID, NAME, sex, birthday, work_location, sal) VALUES(5, '小优子','男', to_date('1994-12-08','yyyy-mm-dd'), '深圳', 9000); INSERT INTO emp(ID, NAME, sex, birthday, work_location, sal) VALUES(6, '小游子','女', to_date('1994-07-08','yyyy-mm-dd'), '深圳', 7500);
2.group by
- GROUP BY语法可以根据给定数据列的每个成员对查询结果进行分组统计,最终得到一个分组汇总表。
- select子句中的列名必须为分组列或聚合函数,聚合函数对于group by子句定义的每个组返回一个结果。
- 只能 select 聚合函数(如:sum() 、max()、min()、avg()、count())
- 对组筛选只能 having,不能是 where(where执行在分组之前,所以where中不能出现聚合函数)
- 不能对 clob 类型项目进行 group by
WITH t_1 AS ( #with子查询 SELECT to_clob(t.name) a#to_clob函数,将普通字段转换为clob类型 FROM emp t ) #以下的SQL报错 SELECT COUNT(1) FROM t_1 GROUP BY a;#a为clob类型的字段,不能应用于group by进行分组
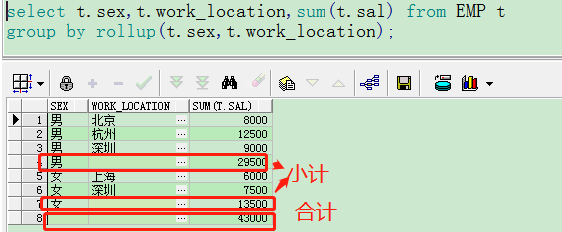
3.rollup
- 从右到左递减分组
- 先小计在合计
- 按照order by 1(,2,3,4...)排序
- 如果rollup参数为N各,则相当于N+1个group by 分组的union的结合
例如:group by rollup(A,B,C),则执行的结果为首先对A,B,C进行group by分组,之后A,B分组,之后A分组,最后对null,也就是整个表进行group by
SELECT A, B, C, SUM(D) FROM table_name GROUP BY ROLLUP(A, B, C); 等同于 SELECT * from ( SELECT A, B, C, SUM(D) FROM table_name GROUP BY(A, B, C) UNION ALL SELECT A, B, null, SUM(D) FROM table_name GROUP BY(A, B, null) UNION ALL SELECT A, null, null, SUM(D) FROM table_name GROUP BY (A, null, null) UNION ALL SELECT null, null, null, SUM(D) From table_name group by (null, null, null) ) order by 1, 2, 3

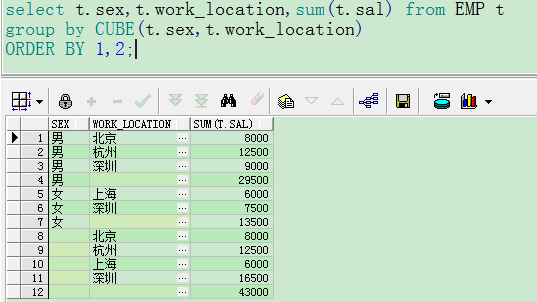
4.CUBE
- cube为立方体的意思,实现交叉组合,结果没有顺序(rollup是有顺序的)
- 如果cude参数为N个,会将group by执行2^N
- 当cube一个参数时等同于rollup
它比 rollup 扩展更加精细,组合类型更多,对于 cube 来说,列的名字只要一样,那么顺序无所谓,结果都是一样的,例如rollup(A,B,C)和rollup(B,C,A)结果是一样的。因为 cube 是各种可能情况的组合,只不过统计的结果顺序不同而已。但是对于 rollup 来说,列的顺序不同,执行顺序从右开始递减,则结果不同。
例如:group by cube(A,B,C) ORDER BY A,B,C之后,group by执行的顺序为:(A,B,C),(A,B),(A,C),(A),(B,C),(B),(C),(null全部)。就等同于这些个group by的组合的union all
如果不order by则先执行null全部,之后C,最后A,B,C组合
5.GROUPING SETS
- group by A,B是对A和B同时进行分组
- group by grouping set(A,B)是对A,B单独进行分组
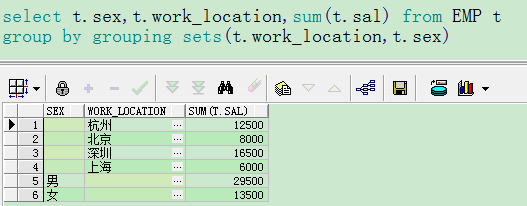
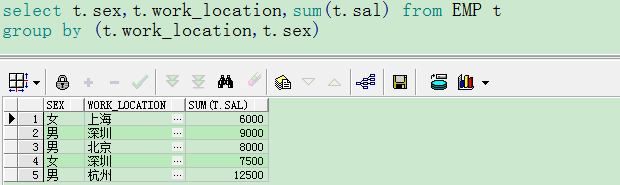
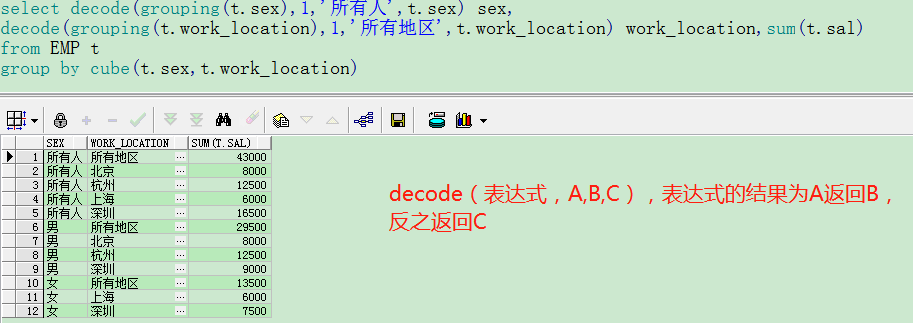
6.GROUPING
- 用于区分 原有值 和 统计项,与group by搭配使用
- 參数仅仅有一个,并且必须为group by中出现的某一列
- grouping(A) = 0 : 数据库中本来的值
- grouping (A)= 1 : 统计的结果