1. 启动集群
2. 创建input路径(有关hadoop 的命令用 "hadoop fs"),input路径并不能在系统中查找到,可以使用 “hadoop fs -ls /”
hadoop fs -mkdir /input
3. 创建测试文件(test1.txt,test2.txt)
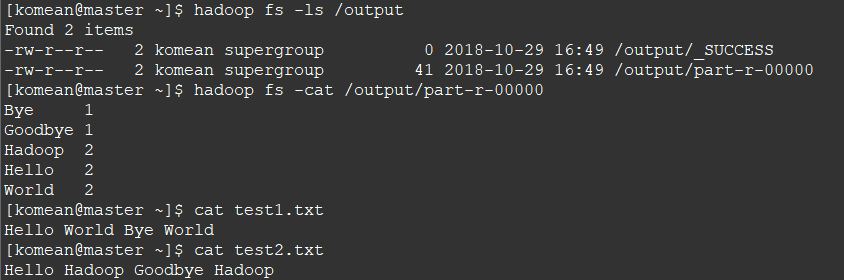
test1.txt
Hello World Bye World
test2.txt
Hello Hadoop Goodbye Hadoop
4. 将测试文件放入/input 中
hadoop fs -put test* /input
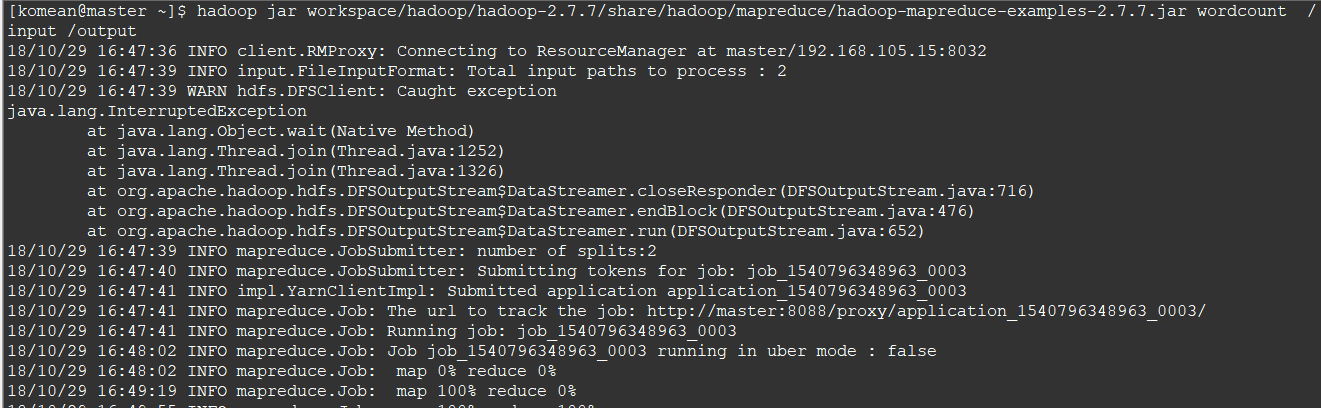
5. 测试(hadoop-mapreduce-examples-2.7.7.jar 是hadoop中的文件,根据自己的路径编写)
hadoop jar /home/komean/workspace/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /input /output
6. 查看结果
hadoop fs -cat /output/part-r-00000