什么是多表关联查询 ?
有时候查询的数据需要从2个表或者更多的表中提取,这个时候就需要使用多表关联查询多表查询分
主要讲:1.内连接 2.左连接 3.右连接 4、全外连接
先建表:
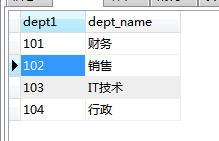
dept表
emp表:
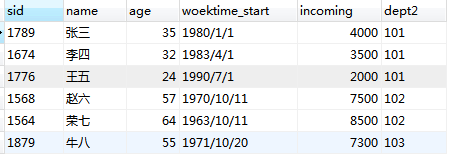
关联字段是dept1和dept2
1、笛卡尔积查询
两张表相乘得到的结果:比如,左边有m条记录,右边有n条记录,查询出来的结果就是m*n,这种查询包含大量的错误结果,通常不会使用这种查询
select * from 表1,表2 ;
格式:select * from dept,emp ;
2、内连接 (普通内连接,隐藏内连接)
查询两个表共有的关联的数据
普通内连接:
select * from dept inner join emp on dept.dept1=emp.dept2;
隐藏内连接:
select * FROM dept,emp where dept.dept1=emp.dept2 ;
左连接:
select * from dept left join emp on dept.dept1=emp.dept2 ;
右连接:
select * from dept right join emp on dept.dept1=emp.dept2 ;
左表独有的数据:
select * from dept left join emp on dept.dept1=emp.dept2 where name is null;
右表独有的数据:
select * from dept right join emp on dept.dept1=emp.dept2 where dept_name is null;
左表和右表独有的数据:union
select * from dept left join emp on dept.dept1=emp.dept2 where name is null
union
select * from dept right join emp on dept.dept1=emp.dept2 where dept_name is null;
全外连接:
方法一:内连接+左右独有
select * FROM dept,emp where dept.dept1=emp.dept2
UNION
select * from dept left join emp on dept.dept1=emp.dept2 where name is null
union
select * from dept right join emp on dept.dept1=emp.dept2 where name is null;
方法二:左连接+右独有数据
select * from dept left join emp on dept.dept1=emp.dept2
union
select * from dept right join emp on dept.dept1=emp.dept2 where name is nul
方法三:右连接+左独有的数据
select * from dept RIGHT JOIN emp on
dept.dept1=emp.dept2
UNION
select * from dept LEFT JOIN emp on dept1=dept2 where emp.name is null;
举例:
1.列出每个部门的平均收入及部门名称;
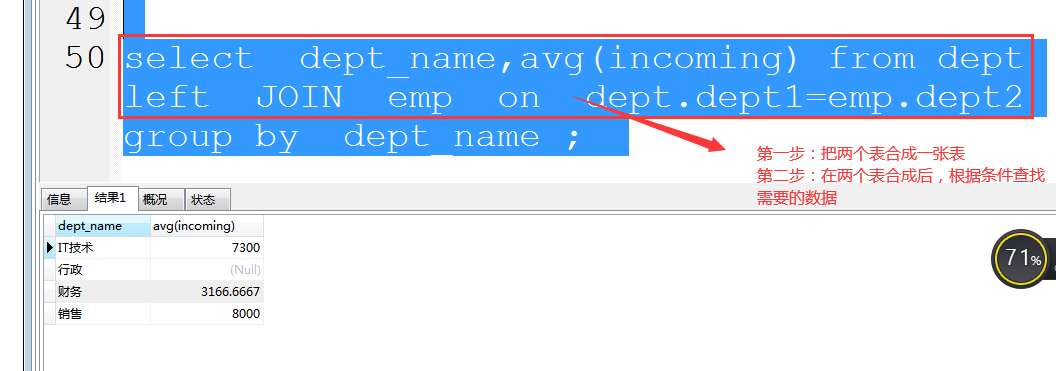
-----------------------------------------------------------------------------------------------------------------------
什么是子查询?一个查询嵌套另一个查询
子查询分
1. 标量子查询 (返回一个值)
标量子查询
把一个sql执行返回的一个值,作为另一个sql的一个条件
得到的结果是一行一列,一般出现在where之后
注意点:标量子查询允许使用的符号
=,!=,> ,>=,=<,<
select * from emp where dept2=(
select dept1 from dept where dept_name="财务" ) ;
2. 列子查询 (返回一个列)
定义:返回的是一列值
注意点:通常在where 条件的后使用,使用的是in 或not in ,不允许使用=,>,<
例题:
求出工资>2000部门
select DISTINCT(dept2) from emp where incoming >5000 ;
select dept_name from dept where dept1 in (select DISTINCT(dept2) from emp where incoming >5000 )
select dept_name from dept where dept1 in (select DISTINCT(dept2) from emp where incoming >5000 )
3. 行子查询 (返回一行多列)
指子查询返回的结果集是一行多列
一般出现在where后
select age ,dept2,incoming from emp1 where name="牛十
select * from emp1 where (age,dept2) =any (select age ,dept2 from emp1 where name="牛十");
4. 表子查询 (返回一个表) from的后面指子查询返回的结果是一个表(多行多列)select dept2,max(incoming) from emp group by dept2
select dept_name ,s.c from dept ,( select dept2,max(incoming) c from emp group by dept2) s where dept.dept1=s.dept2 ;
select DISTINCT(dept_name) from dept inner join (select dept2,age from emp where dept2=101 )as s on dept.dept1=s.dept2 ;
注意:临时表 取别名 ,聚合函数取别名 ,
1、带in关键字的子查询
一个查询预计的条件可能落在另一select语句的查询结果中
2、比较运算符的子查询
= ,> ,>,>= ,=<
3、带any关键字的子查询
=any 与 in 等效
与比较运算符联合使用,表示子查询返回的任何值比较为真,则返回真
4、some
5、带all的关键字的字查询
!=all 或者 <>all 与 not in 等效
表示满足所有的条件
6、带exists 关键字的子查询
理解为:将主查询的数据,放到子查询中做条件验证,根据验证结果,来决定主查询的是数据结构
在子查询到记录,则进行外层查询,否则,不执行外层查询
7、合并查询 union 去除重复的记录
union all 不会去除重复的记录
注意:
1、子查询必须放在一对小括号内;
2、“=”是比较运算符,还可以与其他比较运算符一起使用,要求子查询的列只有一个一行一列
3、子查询通常作为where的条件,表子查询一般在from的后面
4、子查询不能包含order by的语句
select a.dept1 from (select * from dept where dept_name="财务" or dept_name="销售")a where dept1>101;
select DISTINCT(dept_name) from dept inner join (select dept2,age from emp where dept2=101 )as s on dept.dept1=s.dept2 ;