15年论文,百度实验室
We introduce DenseBox, a unifified end-to-end FCN framework that directly predicts bounding boxes and object class confiences through all locations and scales of an image
讲DenseBox,全卷积网络,可以直接预测目标框和类别置信度。通过某张图像的所有定位和尺度。
we focus on one question: To what extent can an one-stage FCN perform on object detection?
作者的出发点,全卷积网络的目标检测性能到底如何?
pipeline:

卷积,上采样,从特征图到目标框和置信度是如何操作的呢?

一张输入图像,对应5个输出通道,分别表示有目标的置信度和该点对应目标框四个点之间的距离。
网络结构:
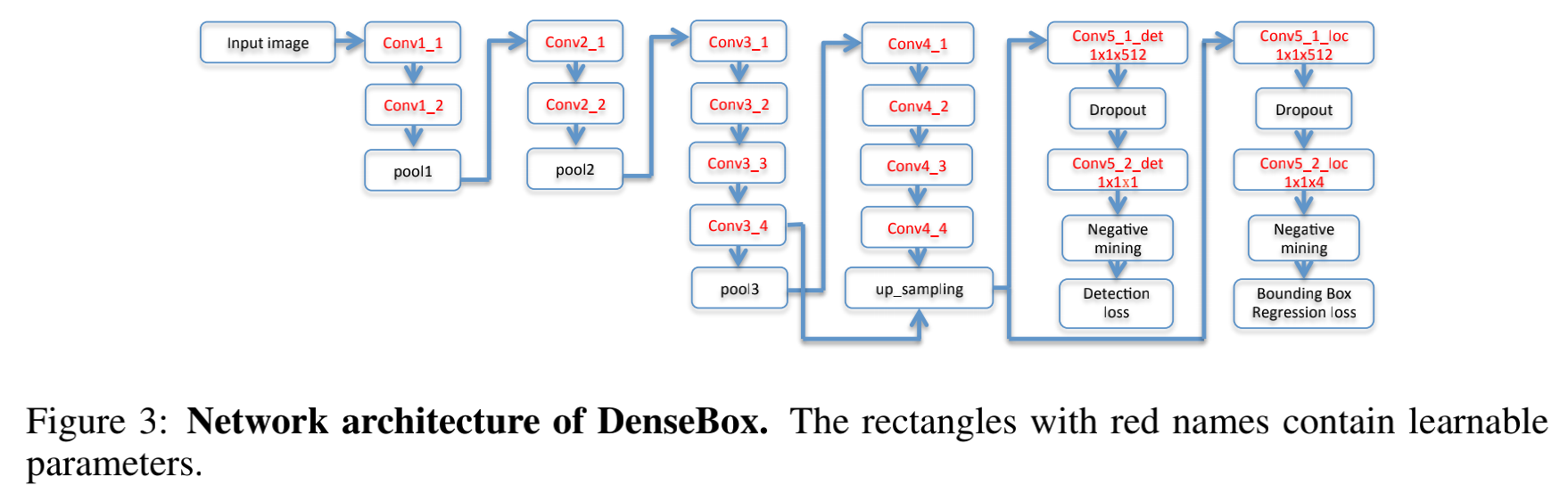
网络输出两个分支,第一个分支参数是1x1x1,输出置信度,第二个分支参数是1x1x4,是目标框4个脚的距离回归。

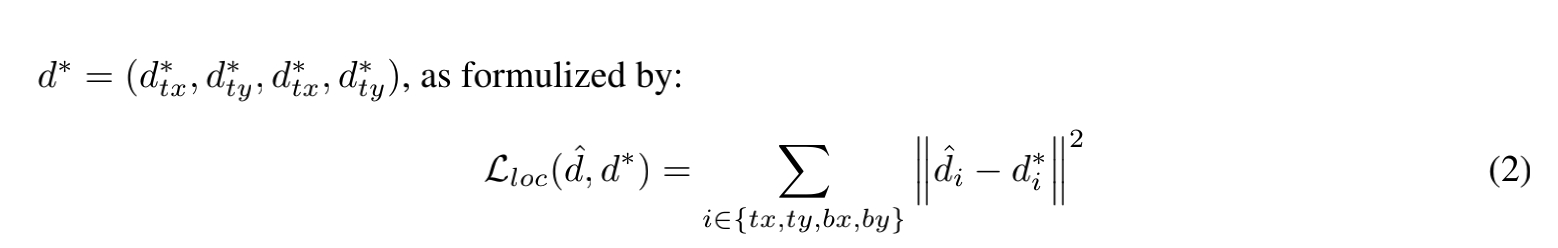
第一个分支求输出特征图上的每一点处是否有目标时,采用的时候L2损失函数,没有用交叉熵损失函数的是L2的表现就已经很好了,
二范数的定义忘了的,可以参考:https://www.zhihu.com/question/20473040,和MSE损失一样,都是计算距离。
第二个分支是是变量L2损失的和。
标签信息:
in the output coordinate space, its ignore flag fign is set to 1 only if there is any pixel with positive label within rnear = 2 pixel length.
and
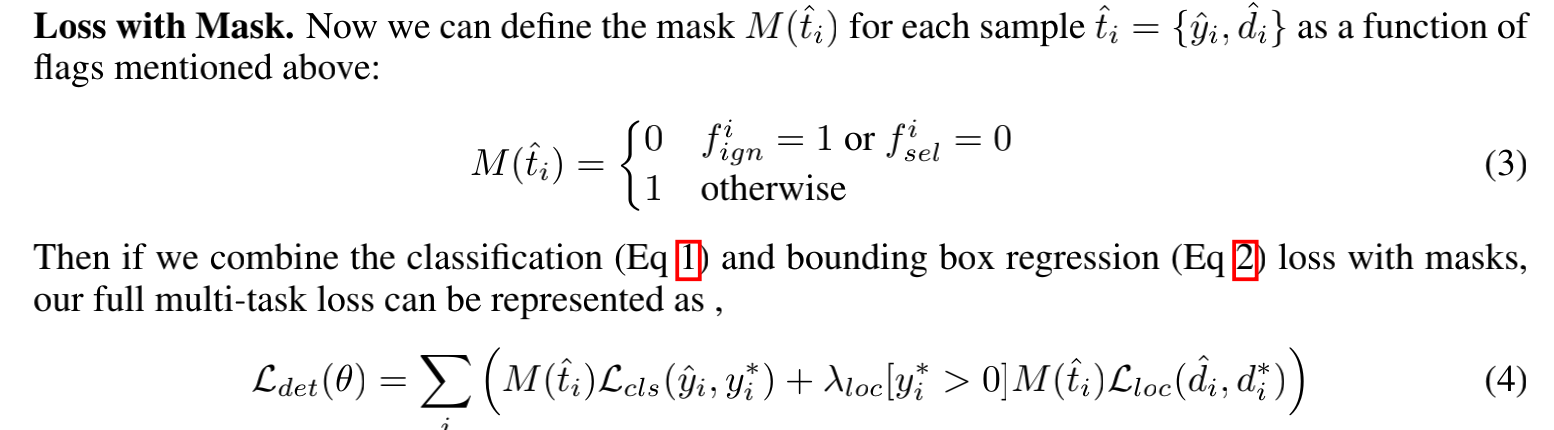
3.4 Refifine with Landmark Localization.
略。