简介
Spring并不直接管理事务,而是提供了多种事务管理器,他们将事务管理的职责委托给Hibernate或者JTA等持久化机制所提供的相关平台框架的事务来实现。
Spring事务管理器的接口是org.springframework.transaction.PlatformTransactionManager,通过这个接口,Spring为各个平台如JDBC、Hibernate等都提供了对应的事务管理器,但是具体的实现就是各个平台自己的事情了。
Spring事物管理涉及接口联系如下:
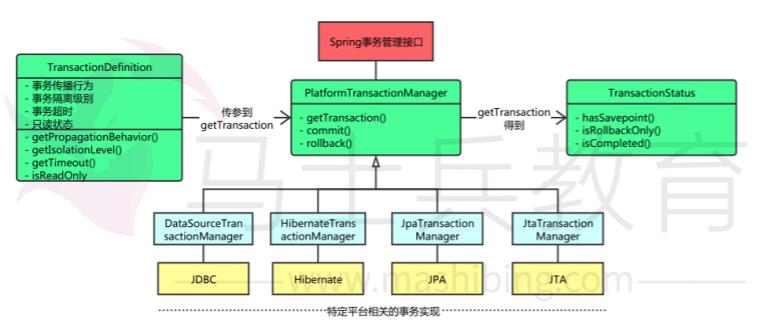
Spring事物接口详解
- TransactionDefinition
default int getPropagationBehavior(): 获取事物传播行为;
default int getIsolationLevel(): 获取事物隔离级别;
default int getTimeout(): 获取事物超时时间;
default boolean isReadOnly(): 获取事物是否只读;
default String getName(): 获取事物对象名字。
读写型事物: 增加、删除、修改开启事物
只读型事物: 执行查询时,也会开启事物
- PlatformTransactionManager
TransactionStatus getTransaction(@Nullable TransactionDefinition definition):获取事物状态行为;
void commit(TransactionStatus status) throws TransactionException: 提交事物;
void rollback(TransactionStatus status) throws TransactionException: 回滚事物。 - TransactionStatus
boolean hasSavepoint():获取是否存在存储点;
void flush():刷新事物;
boolean isNewTransaction():获取事物是否为新的事物;
void setRollbackOnly():获取事物是否回滚;
boolean isRollbackOnly():设置事物回滚;
boolean isCompleted():获取事物是否完成。
事物的传播行为
| 传播行为 | 含义 |
|---|---|
| PROPAGATION_REQUIRED | 表示当前方法必须运行在事务中。如果当前事务存在,方法将会在该事务中运行。否则,会启动一个新的事务 |
| PROPAGATION_SUPPORTS | 表示当前方法不需要事务上下文,但是如果存在当前事务的话,那么该方法会在这个事务中运行 |
| PROPAGATION_MANDATORY | 表示该方法必须在事务中运行,如果当前事务不存在,则会抛出一个异常 |
| PROPAGATION_REQUIRES_NEW | 表示当前方法必须运行在它自己的事务中。一个新的事务将被启动。如果存在当前事务,在该方法执行期间,当前事务会被挂起。如果使用JTATransactionManager的话,则需要访问TransactionManager |
| PROPAGATION_NOT_SUPPORTED | 表示该方法不应该运行在事务中。如果存在当前事务,在该方法运行期间,当前事务将被挂起。如果使用JTATransactionManager的话,则需要访问TransactionManager |
| PROPAGATION_NEVER | 表示当前方法不应该运行在事务上下文中。如果当前正有一个事务在运行,则会抛出异常 |
| PROPAGATION_NESTED | 表示如果当前已经存在一个事务,那么该方法将会在嵌套事务中运行。嵌套的事务可以独立于当前事务进行单独地提交或回滚。如果当前事务不存在,那么其行为与PROPAGATION_REQUIRED一样。注意各厂商对这种传播行为的支持是有所差异的。可以参考资源管理器的文档来确认它们是否支持嵌套事务 |
Spring事物实现两种方式
声明事事物
- 简介
Spring给了一个约定(AOP开发也给了我们一个约定),如果使用的是声明式事务,那么当你的业务方法不发生异常(或者发生异常,但该异常也被配置信息允许提交事务)时,Spring就会让事务管理器提交事务,而发生异常(并且该异常不被你的配置信息所允许提交事务)时,则让事务管理器回滚事务。
- 注解(Transactional)属性
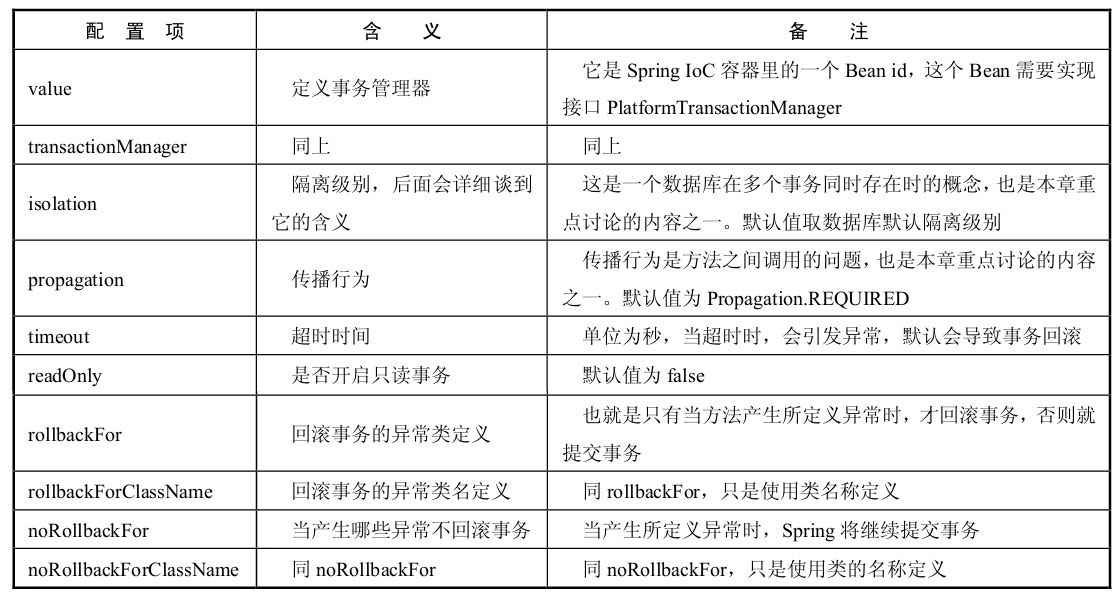
readOnly:
该属性在不同的数据库中代表含义不相同,在mysql中代表本事物中只能执行查询语句,同时进行一些特定的优化,如果执行更新,则报错,在Oracle和sqlserver中暗示这个事务并不包含更改数据的操作,那么JDBC驱动程序和数据库就有可能根据这种情况对该事务进行一些特定的优化,比方说不安排相应的数据库锁,以减轻事务对数据库的压力,毕竟事务也是要消耗数据库的资源的。但如果执行更新,不会报错。
rollbackFor:
By default, a transaction will be rolling back on {@link RuntimeException}
and {@link Error} but not on checked exceptions (business exceptions). See
{@link org.springframework.transaction.interceptor.DefaultTransactionAttribute#rollbackOn(Throwable)}
注释说明 默认遇到RuntimeException及其子类回滚,CheckedException则不被回滚,而IOException、SQLException等以及用户自定义的Exception异常都属于CheckedException,故一般写上rollbackFor=Exception.class,这样Exception以及其子类都将回滚。
propagation:
同一个类中方法互相调用会导致传播行为和事物失效问题参考:
https://www.cnblogs.com/xiaofengshan/p/15516714.html
NESTED和REQUIRED_NEW区别请参考:
https://www.cnblogs.com/xiaofengshan/p/15516720.html
分布式实现事物
本地消息表(MQ 异步确保)
这种实现方式的思路,其实是源于ebay,后来通过支付宝等公司的布道,在业内广泛使用。其基本的设计思想是将远程分布式事务拆分成一系列的本地事务。如果不考虑性能及设计优雅,借助关系型数据库中的表即可实现。
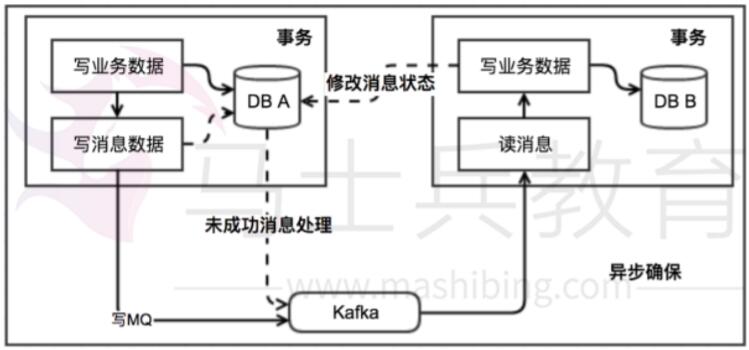
基本思路就是:
消息生产方,需要额外建一个消息表,并记录消息发送状态。消息表和业务数据要在一个事务里提交,也就是说他们要在一个数据库里面。然后消息会经过 MQ 发送到消息的消费方。如果消息发送失败,会进行重试发送。
消息消费方,需要处理这个消息,并完成自己的业务逻辑。此时如果本地事务处理成功,表明已经处理成功了,如果处理失败,那么就会重试执行。如果是业务上面的失败,可以给生产方发送一个业务补偿消息,通知生产方进行回滚等操作。
生产方和消费方定时扫描本地消息表,把还没处理完成的消息或者失败的消息再发送一遍。如果有靠谱的自动对账补账逻辑(防止消息会被重复投递,增加消息应用状态表(message_apply),通俗来说就是个账本,用于记录消息的消费情况,每次来一个消息, 在真正执行之前,先去消息应用状态表中查询一遍,如果找到说明是重复消息,丢弃即可,如果没找到才执行,同时插入到消息应用状态表(同一事务)),这种方案还是非常实用的。
这种方案遵循 BASE 理论,采用的是最终一致性,比较适合实际业务场景的,即不会出现像 2PC 那样复杂的实现(当调用链很长的时候,2PC 的可用性是非常低的),也不会像 TCC 那样可能出现确认或者回滚不了的情况。
优点: 一种非常经典的实现,避免了分布式事务,实现了最终一致性。
缺点: 消息表会耦合到业务系统中,如果没有封装好的解决方案,会有很多杂活需要处理,而且,关系型数据库的吞吐量和性能方面存在瓶颈,频繁的读写消息会给数据库造成压力。
如果消费方处理失败。且生产方无法回滚,如支付宝支付,则采用邮件通知人工进行手工补偿或者调用生产方的补偿接口,如退费。
JTA分布式事务
这个没有用过,具体可以参考:
https://www.cnblogs.com/shamo89/p/7306428.html
分表自增ID解决方案
当我们对MySQL进行分表操作后,将不能依赖MySQL的自动增量来产生唯一ID了,因为数据已经分散到多个表中。
应尽量避免使用自增IP来做为主键,为数据库分表操作带来极大的不便。
1.通过MySQL表生成ID
在《关于MySQL分表操作的研究》提到了一种方法:对于插入也就是insert操作,首先就是获取唯一的id了,就需要一个表来专门创建id,插入一条记录,并获取最后插入的ID。代码如下:
CREATE TABLE `ttlsa_com`.`create_id` (
`id` BIGINT( 20 ) NOT NULL AUTO_INCREMENT PRIMARY KEY
) ENGINE = MYISAM
这种方法效果很好,但是在高并发情况下,MySQL的AUTO_INCREMENT将导致整个数据库慢。如果存在自增字段,MySQL会维护一个自增锁,innodb会在内存里保存一个计数器来记录auto_increment值,当插入一个新行数据时,就会用一个表锁来锁住这个计数器,直到插入结束。如果是一行一行的插入是没有问题的,但是在高并发情况下,那就悲催了,表锁会引起SQL阻塞,极大的影响性能,还可能会达到max_connections值。
2.队列方式
使用队列服务,如redis、memcacheq等等,将一定量的ID预分配在一个队列里,每次插入操作,先从队列中获取一个ID,若插入失败的话,将该ID再次添加到队列中,同时监控队列数量,当小于阀值时,自动向队列中添加元素。
这种方式可以有规划的对ID进行分配,还会带来经济效应,比如QQ号码,各种靓号,明码标价。如网站的userid, 允许uid登陆,推出各种靓号,明码标价,对于普通的ID打乱后再随机分配。
3.SnowFlake算法生成分布式id
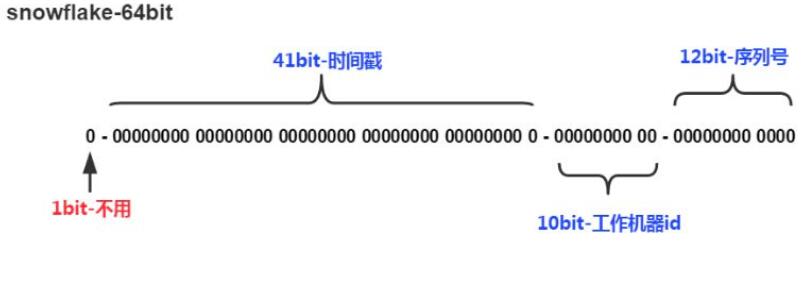
特点: ①递增 ,②保证69年不重复,③每一毫秒生产4096个序列号。
美团SnowFlake算法开源地址:https://github.com/MrSorrow/Leaf
Gitee地址
Spring事物:https://gitee.com/zhuayng/foundation-study/blob/develop/SpringBootDemo/src/test/java/com/yxkj/springbootdemo/SpringbootdemoApplicationTestPropagationBehavior.java
SnowFlake算法:https://gitee.com/zhuayng/foundation-study/blob/develop/JavaBasis/Tools/src/main/java/com/yxkj/javabasistools/tools/idtools/SnowFlake.java