一、集体智慧导言
1、什么是集体智慧?
集体智慧(Collective Intelligence):为了创造新的想法,而将一群人的行为、偏好或思想组合在一起。
2、什么是机器学习?
机器学习是人工智能(AI,artificial intelligence)领域中与算法相关的一个子域,它允许计算机不断地进行学习。大多数情况下,这相当于将一组数据传递给算法,并由算法推断出与这些数据的属性相关的信息————借助这些信息,算法就能准确预测出未来有可能会出现的其他数据。为了实现归纳,机器学习会利用它所认定的出现于数据中的重要特征对数据进行“训练”,并借此得到一个模型。
二、提供推荐
根据群体偏好来为人们提供推荐。有许多针对于此的应用,如在线购物中的商品推荐、热门网站的推荐,以及帮助人们寻找音乐和影片的应用。
1、收集数据
我们可以先构造一个简单的数据集:
#一个涉及影评者及其对几部影片评分情况的字典
critics={'Lisa Rose': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.5,
'Just My Luck': 3.0, 'Superman Returns': 3.5, 'You, Me and Dupree': 2.5,
'The Night Listener': 3.0},
'Gene Seymour': {'Lady in the Water': 3.0, 'Snakes on a Plane': 3.5,
'Just My Luck': 1.5, 'Superman Returns': 5.0, 'The Night Listener': 3.0,
'You, Me and Dupree': 3.5},
'Michael Phillips': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.0,
'Superman Returns': 3.5, 'The Night Listener': 4.0},
'Claudia Puig': {'Snakes on a Plane': 3.5, 'Just My Luck': 3.0,
'The Night Listener': 4.5, 'Superman Returns': 4.0,
'You, Me and Dupree': 2.5},
'Mick LaSalle': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0,
'Just My Luck': 2.0, 'Superman Returns': 3.0, 'The Night Listener': 3.0,
'You, Me and Dupree': 2.0},
'Jack Matthews': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0,
'The Night Listener': 3.0, 'Superman Returns': 5.0, 'You, Me and Dupree': 3.5},
'Toby': {'Snakes on a Plane':4.5,'You, Me and Dupree':1.0,'Superman Returns':4.0},
'xiaoYu': {'Lady in the Water': 2.0, 'Snakes on a Plane': 3.0,
'Just My Luck': 2.5, 'Superman Returns': 3.0, 'You, Me and Dupree': 2.0,
'The Night Listener': 2.5}}
当然,我们也可以去网上下载数据量更大的数据集供我们学习,如GroupLens项目组开发的涉及电影评价的真实数据集,或者通过获取RSS订阅源数据来构建数据集。
2、相似度评价值
| 评价值 | 特点 |
|---|---|
| 欧几里德距离 | 多维空间中两点之间的距离,用来衡量二者的相似度。距离越小,相似度越高。 |
| 皮尔逊相关度评价 | 判断两组数据与某一直线拟合程度的一种度量。在数据不是很规范的时候(如影评者对影片的评价总是相对于平均水平偏离很大时),会给出更好的结果。相关系数越大,相似度越高。 |
3、提供推荐
①为评论者打分:
#为评论者打分
#从反映偏好的字典中返回最为匹配者
#返回结果的个数和相似度函数均为可选参数
def topMatches(prefs,person,n=5,similarity=sim_pearson):
scores=[(similarity(prefs,person,other),other) for other in prefs if other!=person]
#对列表进行排序,评价值最高者排在最前面
scores.sort()
scores.reverse()
return scores[0:n]
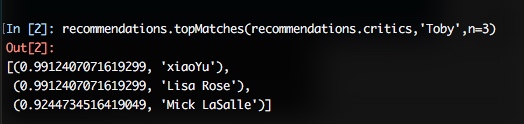
②推荐物品:通过一个经过加权的评价值来为影片打分,并推荐给对应的影评者
#推荐物品
#利用所有他人评价值的加权平均,为某人提供建议
def getRecommendations(prefs,person,similarity=sim_pearson):
totals={}
simSums={}
for other in prefs:
#不要和自己做比较
if other==person: continue
sim=similarity(prefs,person,other)
#忽略评价值为零或小于零的情况
if sim<=0: continue
for item in prefs[other]:
#只对自己还未曾看过的影片进行评价
if item not in prefs[person] or prefs[person][item] == 0:
#相似度*评价值
totals.setdefault(item,0)
totals[item]+=prefs[other][item]*sim
#相似度之和
simSums.setdefault(item,0)
simSums[item]+=sim
#建立一个归一化的列表
rankings=[(total/simSums[item],item) for item,total in totals.items()]
#返回经过排序的列表
rankings.sort()
rankings.reverse()
return rankings
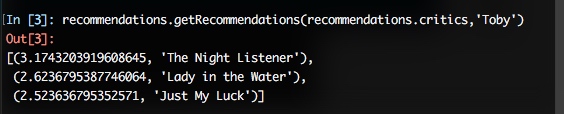
③匹配商品:通过将数据集中的人员和物品对换,构建新的数据集即可。
#匹配商品
#商品与人员对换
def transformPrefs(prefs):
result={}
for person in prefs:
for item in prefs[person]:
result.setdefault(item,{})
#将物品和人员对调
result[item][person]=prefs[person][item];
return result
4、基于用户进行过滤还是基于物品进行过滤?
协作型过滤:对一大群人进行搜索并给出与我们相近的人的排名列表。
最显著的区别:物品间的比较不会像用户间的比较那么频繁变化。
在拥有大量数据集的情况下,基于物品的协作型过滤能够得出更好的结论,而且它允许我们将大量计算任务预先执行,从而使需要给予推荐的用户能够快速地得到他们所要的结果。
对于稀疏数据集,基于物品的过滤方法通常要优于基于用户的过滤方法,而对于密集数据集而言,两者的效果则几乎是一样的。
三、发现群组
聚类是把相似的对象通过静态分类的方法分成不同的组别或者更多的子集(subset),这样让在同一个子集中的成员对象都有相似的一些属性,常见的包括在坐标系中更加短的空间距离等。一般把数据聚类归纳为一种非监督式学习。
1、监督学习和无监督学习
| 学习方式 | 种类 | 方式 |
|---|---|---|
| 监督学习 | 神经网络、决策树、贝叶斯过滤等 | 通过检查一组输入和期望的输出来进行“学习”。 |
| 无监督学习 | 聚类算法 | 在一组数据中找寻某种结构,采集数据,然后找出不同的群组。 |
2、分级聚类
分级聚类通过不断地将最为相似的群组两两合并,来构造出一个群组的层级结构。其中的每个群组都是从单一元素开始的(如本章中的博客数据集中,博客就是单一元素)。在每次迭代的过程中,分级聚类孙发会计算每两个群组间的距离,并将距离最近的两个群组合并成一个新的群组,直到只剩下一个群组为止。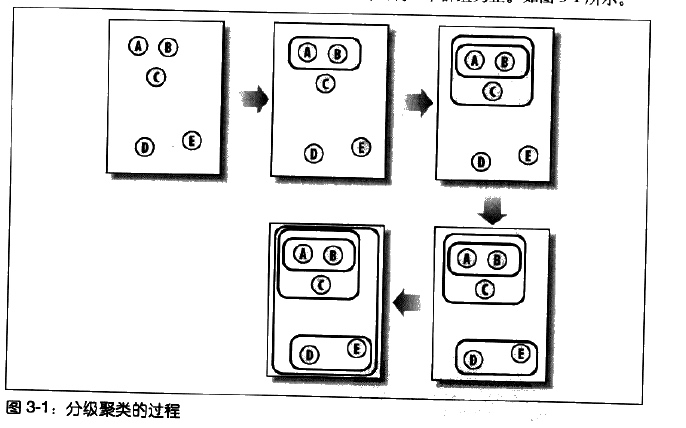
分级聚类算法:
def hcluster(rows,distance=pearson):
distances={}
currentclustid=-1
# 最开始的聚类就是数据集中的行
clust=[bicluster(rows[i],id=i) for i in range(len(rows))]
while len(clust)>1:
lowestpair=(0,1)
closest=distance(clust[0].vec,clust[1].vec)
# 遍历每一个配对,寻找最小距离
for i in range(len(clust)):
for j in range(i+1,len(clust)):
#用distance来缓存距离的计算值
if (clust[i].id,clust[j].id) not in distances:
distances[(clust[i].id,clust[j].id)]=distance(clust[i].vec,clust[j].vec)
d=distances[(clust[i].id,clust[j].id)]
if d<closest:
closest=d
lowestpair=(i,j)
# 计算两个聚类的平均值
mergevec=[
(clust[lowestpair[0]].vec[i]+clust[lowestpair[1]].vec[i])/2.0
for i in range(len(clust[0].vec))]
# 建立新的聚类
newcluster=bicluster(mergevec,left=clust[lowestpair[0]],
right=clust[lowestpair[1]],
distance=closest,id=currentclustid)
# 不在原始数据集合中的聚类,其id为负数
currentclustid-=1
del clust[lowestpair[1]]
del clust[lowestpair[0]]
clust.append(newcluster)
return clust[0]
我们可以通过Python提供的PIL库来绘制出分级聚类对应的树状图,使结果更加直观。
def getheight(clust):
# 这是一个叶节点吗?若是,则高度为1
if clust.left==None and clust.right==None: return 1
#否则,高度为每个分支的高度之和
return getheight(clust.left)+getheight(clust.right)
def getdepth(clust):
#一个叶节点的距离是0.0
if clust.left==None and clust.right==None: return 0
# 一个枝节点的距离等于左右两侧分支中距离较大者
# 加上该枝节点自身的距离
return max(getdepth(clust.left),getdepth(clust.right))+clust.distance
def drawdendrogram(clust,labels,jpeg='clusters.jpg'):
# 高度和宽度
h=getheight(clust)*20
w=1200
depth=getdepth(clust)
#由于宽度是固定的,因此我们需要对距离值进行相应的调整
scaling=float(w-150)/depth
# 新建一个白色背景的图片
img=Image.new('RGB',(w,h),(255,255,255))
draw=ImageDraw.Draw(img)
draw.line((0,h/2,10,h/2),fill=(255,0,0))
# 画第一个节点
drawnode(draw,clust,10,(h/2),scaling,labels)
img.save(jpeg,'JPEG')
def drawnode(draw,clust,x,y,scaling,labels):
if clust.id<0:
h1=getheight(clust.left)*20
h2=getheight(clust.right)*20
top=y-(h1+h2)/2
bottom=y+(h1+h2)/2
# 线的长度
ll=clust.distance*scaling
#聚类到其子节点的垂直线
draw.line((x,top+h1/2,x,bottom-h2/2),fill=(255,0,0))
# 连接左侧节点的水平线
draw.line((x,top+h1/2,x+ll,top+h1/2),fill=(255,0,0))
# 连接右侧节点的水平线
draw.line((x,bottom-h2/2,x+ll,bottom-h2/2),fill=(255,0,0))
#调用函数绘制左右节点
drawnode(draw,clust.left,x+ll,top+h1/2,scaling,labels)
drawnode(draw,clust.right,x+ll,bottom-h2/2,scaling,labels)
else:
#如果这是一个叶节点,则绘制节点的标签
draw.text((x+5,y-7),labels[clust.id],(0,0,0))
生成如下的树状图:
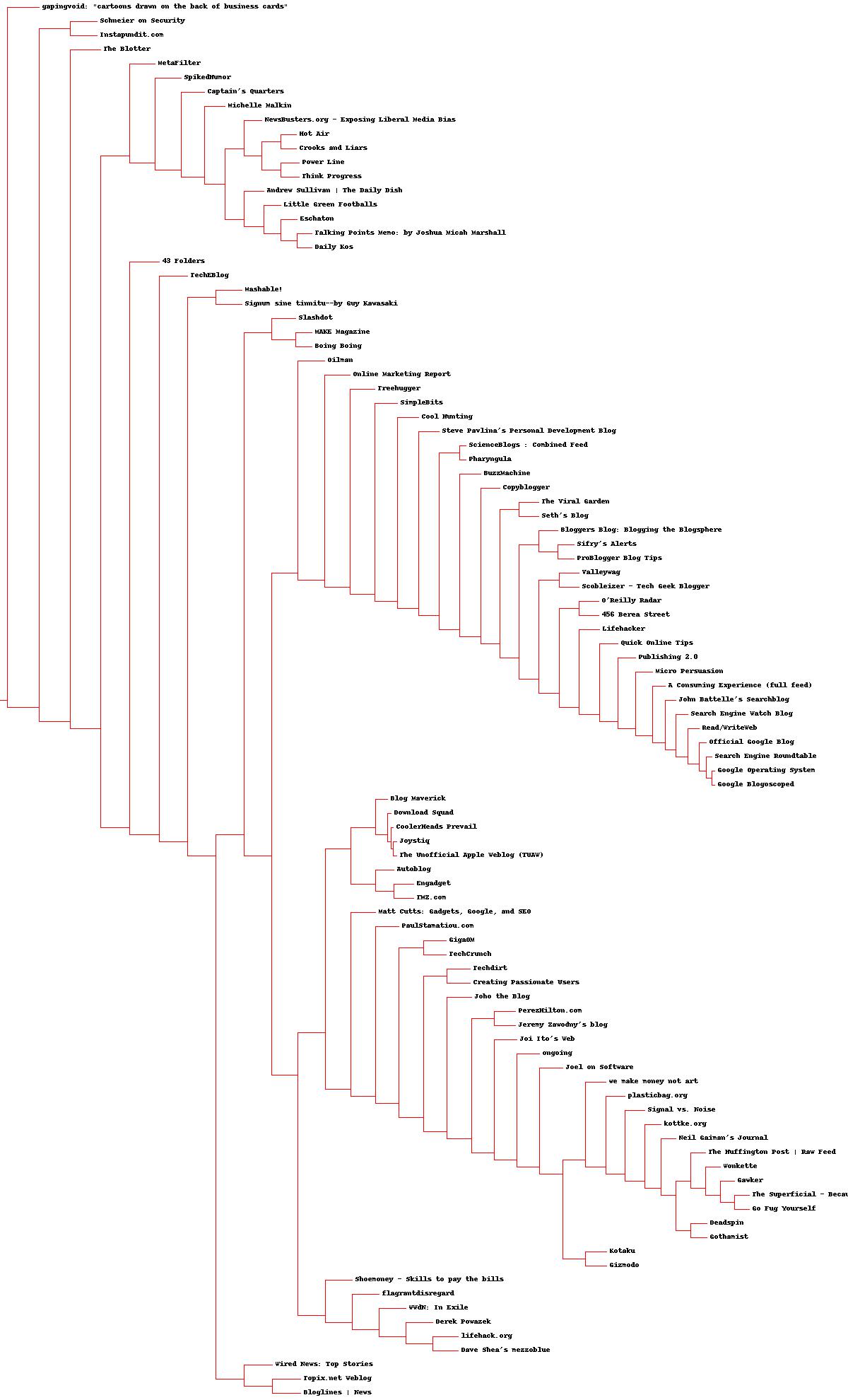
3、列聚类
同时在行和列上对数据进行聚类常常是很有必要的。
以上的例子中标签是博客,将数据集矩阵进行转置(行变列,列变行),使其标签变为单词,来进行聚类。
4、K-均值聚类
分级聚类的缺点:不易操作,合并项之后关系还得在计算,计算量非常大。
K-均值聚类算法首先会随机确定k个中心位置(位于空间中代表聚类中心的点),然后将各个数据项分配给最临近的中心点。待分配完成后,聚类中心就会移到分配给该聚类的所有节点的平均位置处,然后整个分配过程重新开始。这一过程会一直重复下去,直到分配过程不再产生变化为止。
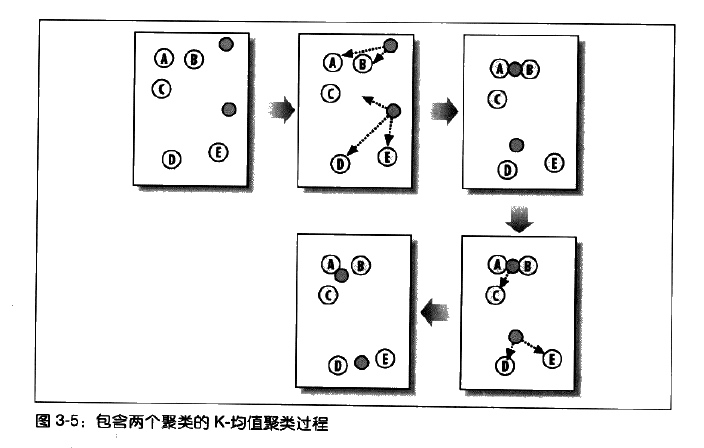
K-均值聚类算法:
def kcluster(rows,distance=pearson,k=4):
# 确定每个点的最小值和最大值
ranges=[(min([row[i] for row in rows]),max([row[i] for row in rows]))
for i in range(len(rows[0]))]
# 随机创建k个中心点
clusters=[[random.random()*(ranges[i][1]-ranges[i][0])+ranges[i][0]
for i in range(len(rows[0]))] for j in range(k)]
lastmatches=None
for t in range(100):
print 'Iteration %d' % t
bestmatches=[[] for i in range(k)]
# 在每一行中寻找距离最近的中心点
for j in range(len(rows)):
row=rows[j]
bestmatch=0
for i in range(k):
d=distance(clusters[i],row)
if d<distance(clusters[bestmatch],row): bestmatch=i
bestmatches[bestmatch].append(j)
# 如果结果与上一次相同,则整个过程结束
if bestmatches==lastmatches: break
lastmatches=bestmatches
# 把中心点移到其所有成员的平均位置处
for i in range(k):
avgs=[0.0]*len(rows[0])
if len(bestmatches[i])>0:
for rowid in bestmatches[i]:
for m in range(len(rows[rowid])):
avgs[m]+=rows[rowid][m]
for j in range(len(avgs)):
avgs[j]/=len(bestmatches[i])
clusters[i]=avgs
return bestmatches
5、多维缩放
前面我们已经用数据可视化方式来表示聚类,然而在大多数情况下,我们所要的聚类的内容都不只包含两个数据,所以我们不可能按照之前的方法来采集数据并以二维形式表现出来。
通过多维缩放为数据集找到一种二维表达形式。算法根据每对数据项之间的差距情况,尝试绘制出一幅图来,图中各数据项之间的距离远近,对应于它们彼此间的差异程度。(欧几里德距离算法)
多维缩放效果图:
