一、网页分析
打开Google浏览器,找的有道词典的翻译网页(http://fanyi.youdao.com/)
打开后摁F12打开开发者模式,找Network选项卡,点击Network选项卡,然后刷新一下网页
然后翻译一段文字,随便啥都行(我用的程序员的传统:hello world),然后点击翻译
在选项卡中找到以translate开头的post文件
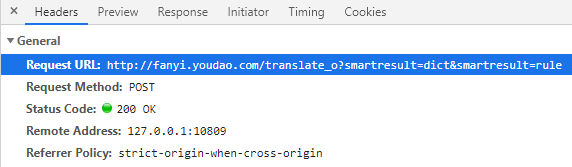
上面标注的,写代码时要用
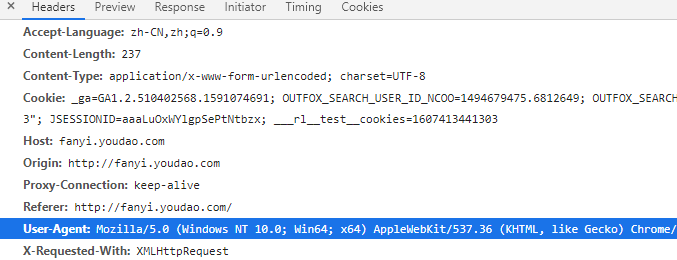
记住 User-Agent,用来伪装浏览器请求

这些是需要提交的参数。
好,准备工作做完了,接下来开始干正事了
二、代码演示


# !/usr/bin/python3 # -*- coding: utf-8 -*- import json import requests while True: #无限循环 content = input("请输入您要翻译的内容(输入 !!! 退出程序): ") #设置退出条件 if content == '!!!': break url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' #选择要爬取的网页,上面找过了 # 手动替换一下 header = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'} #伪装计算机提交翻译申请(下面的内容也在在上面有过,最好根据自己的进行修改) data = {} data['type'] = 'AUTO' data['i'] = content data['doctype'] = 'json' data['version'] = '2.1' data['keyfrom:'] = 'fanyi.web' data['ue'] = 'UTF-8' data['typoResult'] = 'true' # post请求 response = requests.post(url,headers=header,data=data) # 解码 html = response.content.decode('utf-8') # 转换为字典 paper = json.loads(html) #打印翻译结果 print("翻译结果: %s" % (paper['translateResult'][0][0]['tgt']))
执行代码,效果如下:

本文参考链接:
https://blog.csdn.net/Spiderman_Feng/article/details/110675766