我们在爬虫的过程中,有一些动态渲染的页面,我们是请求不到数据的。因此,我们可以直接通过使用模拟浏览器运行的方式实现,那么就可以实现原本浏览器中可以看到的,抓取的数据就是什么样,即所见即所"得"(爬);此时我们不用再去关心网页中JS使用了什么算法或者结构实现了页面渲染。
Python提供了许多模拟浏览器运行的库,如 Selenium、 Splash、 PyV8, Ghost等
Selenium 的使用
Selenium是一个 自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作, 同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。
1、基本使用
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait browser = webdriver.Chrome() try: browser.get('https://www.baidu.com') # 找到输入框,根据id获取 input = browser.find_element_by_id('kw') #输入搜索关键字“python” input.send_keys('Python') #点击搜索 input.send_keys(Keys.ENTER) #等待十秒 wait = WebDriverWait(browser, 10) # presence_of_element_located判断某个元素是否被加到了 dom 树里,并不代表该元素一定可见。 # 里面要是一个元祖 wait.until(EC.presence_of_element_located((By.ID, 'content_left'))) #输出当前url print('输出当前url: ',browser.current_url) #输出页面cookie print('输出页面cookie: ',browser.get_cookies()) #输出页面内容 #print(browser.page_source) except: print('Fail') finally: #关闭浏览器 browser.close()
输出结果:
输出当前url: https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=Python&fenlei=256&rsv_pq=cb2816e900015d95&rsv_t=b787r%2BVzA0qjW4QKdzHIo7fcG4iLmC6iSRyKMpiaMrmd7hA5tADIT4yrLIw&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=6&rsv_sug2=0&rsv_btype=i&inputT=213&rsv_sug4=213 输出页面cookie: [{'domain': 'www.baidu.com', 'httpOnly': False, 'name': 'BDSVRTM', 'path': '/', 'secure': False, 'value': '174'}, {'domain': '.baidu.com', 'httpOnly': False, 'name': 'H_PS_PSSID', 'path': '/', 'secure': False, 'value': '32292_1441_32355_31253_32348_32045_32116_31321_32297_26350_22158'}, {'domain': '.baidu.com', 'httpOnly': False, 'name': 'PSINO', 'path': '/', 'secure': False, 'value': '2'}, {'domain': 'www.baidu.com', 'httpOnly': False, 'name': 'BD_CK_SAM', 'path': '/', 'secure': False, 'value': '1'}, {'domain': '.baidu.com', 'expiry': 1627052281, 'httpOnly': False, 'name': 'BAIDUID', 'path': '/', 'secure': False, 'value': '6C9B8822C3C4362FD97A588E493398C8:FG=1'}, {'domain': '.baidu.com', 'httpOnly': False, 'name': 'delPer', 'path': '/', 'secure': False, 'value': '0'}, {'domain': '.baidu.com', 'expiry': 3742999928, 'httpOnly': False, 'name': 'BIDUPSID', 'path': '/', 'secure': False, 'value': '6C9B8822C3C4362F3E16CA0A76797398'}, {'domain': '.baidu.com', 'expiry': 3742999928, 'httpOnly': False, 'name': 'PSTM', 'path': '/', 'secure': False, 'value': '1595516283'}, {'domain': 'www.baidu.com', 'expiry': 1595518875, 'httpOnly': False, 'name': 'H_PS_645EC', 'path': '/', 'secure': False, 'value': 'a511pVLQtJh0hvfLuFVtXamctKD8jDLY2Z%2F0BAk49CMoxm8HDM01bvGqCLk'}, {'domain': 'www.baidu.com', 'expiry': 1596380281, 'httpOnly': False, 'name': 'BD_UPN', 'path': '/', 'secure': False, 'value': '12314753'}, {'domain': 'www.baidu.com', 'httpOnly': False, 'name': 'BD_HOME', 'path': '/', 'secure': False, 'value': '1'}]
2、 声明浏览器对象
from selenium import webdriver browser = webdriver.Chrome() # google browser = webdriver.Firefox() # 火狐 browser = webdriver.Edge() #edge browser = webdriver.PhantomJS() # 无界面 browser = webdriver.Safari() # mac自带浏览器
3、访问页面
from selenium import webdriver browser = webdriver.Chrome() # 通过get(url) browser.get('https://www.taobao.com') #打印淘宝首页页面内容 print(browser.page_source) #关闭谷歌浏览器 browser.close()
结果:
………………(省略一万字) <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"> <meta name="renderer" content="webkit"> <title>淘宝网 - 淘!我喜欢</title> ………………(省略一万字)
4、 查找节点
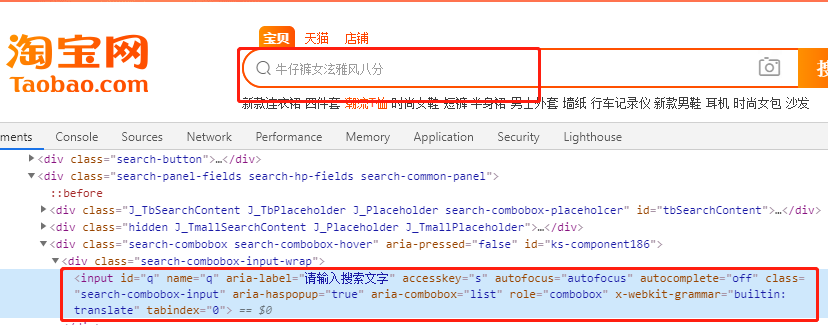
目的:找到输入框
单个节点的情况
以淘宝为例:
代码:
from selenium import webdriver browser = webdriver.Chrome() browser.get('https://www.taobao.com') #找搜索框--id方式 input_first = browser.find_element_by_id('q') #找搜索框--css方式 input_second = browser.find_element_by_css_selector('#q') #找搜索框--xpath方式 input_third = browser.find_element_by_xpath('//*[@id="q"]') print(input_first) print(input_second) print(input_third) browser.close()
结果:
<selenium.webdriver.remote.webelement.WebElement (session="21a8b4b733264fbcbd8b058a2b05bf9f", element="3de372cc-d9f3-49c7-b423-e586f6a225d1")> <selenium.webdriver.remote.webelement.WebElement (session="21a8b4b733264fbcbd8b058a2b05bf9f", element="3de372cc-d9f3-49c7-b423-e586f6a225d1")> <selenium.webdriver.remote.webelement.WebElement (session="21a8b4b733264fbcbd8b058a2b05bf9f", element="3de372cc-d9f3-49c7-b423-e586f6a225d1")>
多个节点的情况
find_element() 只能查找目标网页中的一个,要查找多个要用find_elements()
代码
from selenium import webdriver browser = webdriver.Chrome() browser.get('https://www.taobao.com') lis = browser.find_elements_by_css_selector('.service-bd li') print(lis) browser.close()
结果:
[<selenium.webdriver.remote.webelement.WebElement (session="bdc3c2c445ccff47c45a623f6de58563", element="68843b38-2f7a-4d6f-b600-a41709370931")>, <selenium.webdriver.remote.webelement.WebElement (session="bdc3c2c445ccff47c45a623f6de58563", element="ba76c6b5-8e5e-49e2-930c-31dd008746e4")>, <selenium.webdriver.remote.webelement.WebElement (session="bdc3c2c445ccff47c45a623f6de58563", element="39a9722b-d954-428a-b457-6f3b2e2ebc03")>, <selenium.webdriver.remote.webelement.WebElement (session="bdc3c2c445ccff47c45a623f6de58563", element="5ebb0c1e-a0e4-4b44-8d53-fc6fffddb54c")>, <selenium.webdriver.remote.webelement.WebElement (session="bdc3c2c445ccff47c45a623f6de58563", element="13abdd53-44ae-4664-a5ea-eab06fde3d8e")>, <selenium.webdriver.remote.webelement.WebElement (session="bdc3c2c445ccff47c45a623f6de58563", element="071103dd-db53-4c32-81ae-14fe2f260842")>, <selenium.webdriver.remote.webelement.WebElement (session="bdc3c2c445ccff47c45a623f6de58563", element="d2b29103-f42b-4417-bce2-23fac105f117")>, <selenium.webdriver.remote.webelement.WebElement (session="bdc3c2c445ccff47c45a623f6de58563", element="d43cb5a5-2543-4da0-8e5b-5044f17b53f4")>, <selenium.webdriver.remote.webelement.WebElement (session="bdc3c2c445ccff47c45a623f6de58563", element="577b5b36-e836-4d8d-94cd-e84f9ea06d96")>, <selenium.webdriver.remote.webelement.WebElement (session="bdc3c2c445ccff47c45a623f6de58563", element="10850d3c-f7dd-4a7f-9691-362464092fa9")>, <selenium.webdriver.remote.webelement.WebElement (session="bdc3c2c445ccff47c45a623f6de58563", element="358a0778-591b-427d-aa61-c2b910ba35d1")>, <selenium.webdriver.remote.webelement.WebElement (session="bdc3c2c445ccff47c45a623f6de58563", element="7db19a0b-f4dd-476e-9d93-54a1ffb44468")>, <selenium.webdriver.remote.webelement.WebElement (session="bdc3c2c445ccff47c45a623f6de58563", element="ce274c07-94f1-4b4e-8f9c-0fd4d993a7c3")>, <selenium.webdriver.remote.webelement.WebElement (session="bdc3c2c445ccff47c45a623f6de58563", element="358aad1b-8fa4-48f7-8424-3720e48925eb")>, <selenium.webdriver.remote.webelement.WebElement (session="bdc3c2c445ccff47c45a623f6de58563", element="b5d4a744-9b88-493e-8343-b57b74ca1030")>, <selenium.webdriver.remote.webelement.WebElement (session="bdc3c2c445ccff47c45a623f6de58563", element="d709c785-03b3-4cf2-9c98-af3eff5381a1")>]
5、节点交互
输入文字:send_keys()
清空文字:clear()
点击按钮:click()
from selenium import webdriver import time browser = webdriver.Chrome() browser.get('https://www.taobao.com') input = browser.find_element_by_id('q') #输入文字‘iPhone’ input.send_keys('iphone') #睡1秒 time.sleep(1) #清空 input.clear() #输入文字‘iPad’ input.send_keys('ipad') #找到class='btn-search'的按钮 button = browser.find_element_by_class_name('btn-search') #点击它 button.click()
结果:
淘宝要登录,这里无法返回结果
6、动作链
执行鼠标拖曳 、 键盘按键等动作
from selenium import webdriver from selenium.webdriver import ActionChains browser = webdriver.Chrome() url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable' browser.get(url) browser.switch_to.frame('iframeResult') source = browser.find_element_by_css_selector('#draggable') target = browser.find_element_by_css_selector('#droppable') actions = ActionChains(browser) actions.drag_and_drop(source, target) actions.perform()
结果
7、执行javascript
对于没有提供的操作,如下拉进度条,可以使用excute_script()方法实现。
from selenium import webdriver browser = webdriver.Chrome() browser.get('https://www.zhihu.com/explore') browser.execute_script('window.scrollTo(0,document.body.scrollHeight)') # 下拉到底部后,谈出alert提示框 browser.execute_script('alert("To Bottom")')
8、获取节点信息
page_source 属性可以获取网页的源代码,然后通过Beautiful soup pyquery进行信息提取
也可以使用selenium自带的获取属性、文本等
· 获取属性
get_attribute()方法来获取节点的属性
from selenium import webdriver from selenium.webdriver import ActionChains browser = webdriver.Chrome() url = 'https://www.zhihu.com/explore' browser.get(url) #输出搜索框内容 logo = browser.find_element_by_id('Popover1-toggle') print(logo) #输出class="Input"的值 print(logo.get_attribute('class'))
结果:
<selenium.webdriver.remote.webelement.WebElement (session="f6ae22acea8757f858eb2c7939c2ee8b", element="0060864e-d6ed-4690-a481-e093da6b0254")> Input
· 获取文本值
text()
·获取 id、位置、 标签名和大小
id 属性可以获取节点 id, location 属性可以获取该节点在页面中的相对位置, tag_name 属性可以获取标签名称, 就是宽高
9、延时等待
get()方法会在网页框架加载结束后结束执行,此时如果获取page_source,可能并不是浏览器完全加载完全的页面,如果有页面有额外的Ajax请求,在网页源代码中并不一定能成功获取,所以需要延时等待一下。
·隐式等待
from selenium import webdriver browser = webdriver.Chrome() # 隐式等待,默认等待0秒,找不到继续等一会在找,容易受到页面加载时间的影响 browser.implicitly_wait(10) browser.get('https://www.zhihu.com/explore') input = browser.find_element_by_class_name('Input') print(input)
结果:
<selenium.webdriver.remote.webelement.WebElement (session="318f4d1c97b1ecec3d8043cdf957e054", element="888440c5-9c7b-42d6-9be2-3bab91a59d98")>
·显式等待
指定一个最长等待时间
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC browser = webdriver.Chrome() browser.get('https://www.taobao.com/') wait = WebDriverWait(browser, 10) input = wait.until(EC.presence_of_element_located((By.ID, 'q'))) button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search'))) print(input, button)
结果:
<selenium.webdriver.remote.webelement.WebElement (session="ac8a2a732adbaf4571fbb92e17fe5889", element="9ef29720-d902-42b6-94d4-54868739ad94")> <selenium.webdriver.remote.webelement.WebElement (session="ac8a2a732adbaf4571fbb92e17fe5889", element="ea01d031-dc8e-4cb4-9703-fadb51ff33de")>

10、前进和后退
forword() 前进下一个页面,back() 返回前一个页面
11、Cookies
get_cookies() 方法获取所有的 Cookie
add_cookies() 方法添加cookies
delete_all_cookies()方法删除所有的 Cookies
