建议61:使用更为安全的property
property是用来实现属性可管理性的built-in数据类型。它实际上是一种实现了__get__(), __set__()方法的类,用户也可以根据自己的需要定义个性化的property,其实质是一种特殊的数据描述符(数据描述符:如果一个对象同时定义了__get__()和__set__()方法,则称为数据描述符,如果仅定义了__get__()方法,则称为非数据描述符)。它和普通描述符的区别在于:普通描述符提供的是一种较为低级的控制属性访问的机制,而property是它的高级应用,它以标注库的形式提供描述符的实现,其签名形式为:
property(fget=None, fset=None, fdel=None, doc=None) -> property attribute
Property常见的使用形式有以下几种
1)
class Some_Class(object): def __init__(self): self._somevalue = 0 def get_value(self): print("calling get method to get value") return self._somevalue def set_value(self, value): print("calling set method to set value") self._somevalue = value def del_attr(self): print("calling delete method to delete value") del self._somevalue x = property(get_value, set_value, del_attr, "I'm the 'x' property.") obj = Some_Class() obj.x = 10 print(obj.x) print(obj.x + 2) del obj.x print(obj.x)
2)
class Some_class(object): _x = None def __init__(self): self._x = None @property def x(self): print("calling get method to return value") return self._x @x.setter def x(self, value): print("calling set method to set value") self._x = value @x.deleter def x(self): print("calling delete method to delete value") del self._x obj = Some_class() obj.x = 10 print(obj.x) del obj.x print(obj.x)
property的优势可言简单概括为以下几点:
1)代码简洁,可读性更强。这条优势是显而易见的,显然obj.x += 1比 obj.set_value(ojb.get_value()+1)要更简洁易读,而且对于编程人员来说还少敲了几次键盘。
2)更好的管理属性的访问。property将对属性的访问直接转换为对对应的get / set等相关函数的调用,属性能够更好的被控制和管理。
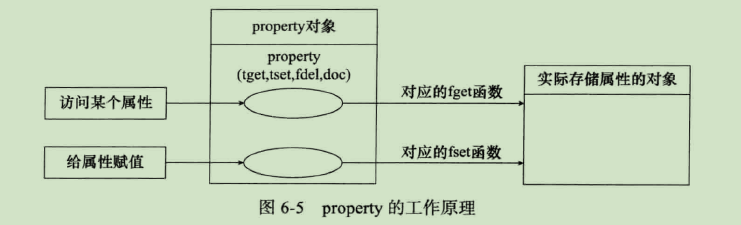
创建一个property实际上就是将其属性的访问与特定的函数关联起来,相对于标准属性的访问,其工作原理如图。property的作用相当于一个分发器,对某个属性的访问并不直接操作具体对象,而对标准属性的访问没有中间这一层,直接访问存储属性的对象。
3)代码可维护性更好;
4)控制属性访问权限;提高数据安全性,如果用户想设置某个属性为只读:
class PropertyTest(object): def __init__(self): self.__varl = 20 @property def x(self): return self.__varl pt = PropertyTest() print(pt.x) pt.x = 12
其实:使用property并不能真正完全达到属性只读的目的,正如以双下划线命令的变量并不是真正的私有变量一样,这些方法只是在直接修改属性这条道路上增加了一些障碍。如果用户想访问私有属性,同样能够实现,使用 pt._PropertyTest__varl = 30 来修改属性。
property本质并不是函数,而是特殊类,既然是类的话,那么就可以被继承,因此用户便可以根据自己的需要定义property:
def update_meta(self, other): self.__name__ = other.__name__ self.__doc__ = other.__doc__ self.__dict__.update(other.__dict__) return self class UserProperty(property): def __new__(cls, fget=None, fset=None, fdel=None, doc=None): if fget is not None: def __get__(obj, objtype=None, name=fget.__name__): fget = getattr(obj, name) print("fget name:" + fget.__name__) return fget() fget = update_meta(__get__, fget) if fset is not None: def __set__(obj, value, name=fset.__name__): fset = getattr(obj, name) print("fset name:" + fset.__name__) print("setting value:" + str(value)) return fset(value) fset = update_meta(__set__, fset) if fdel is not None: def __delete__(obj, name=fdel.__name__): fdel = getattr(obj, name) print("warning: you are deleting attribute using fdel.__name__") return fdel() fdel = update_meta(__delete__, fdel) return property(fget, fset, fdel, doc) class C(object): def get(self): print("calling C.getx to get value") return self._x def set(self, x): print("calling C.setx to set value") self._x = x def delete(self): print("calling C.delx to delete value") del self._x x = UserProperty(get, set, delete) c = C() c.x = 1 print(c.x)
回到前面的问题:使用property并不能真正完全达到属性只读的目的,用户仍然可以绕过阻碍来修改变量,那么要真正实现只读属性怎么做呢:
def ro_property(obj, name, value): setattr(obj.__class__, name, property(lambda obj: obj.__dict__["__" + name])) setattr(obj, "__" + name, value) class ROClass(object): def __init__(self, name, available): ro_property(self, "name", name) self.available = available a = ROClass("read only", True) print(a.name) a._ROClass__name = "modify" print(a.__dict__) print(ROClass.__dict__) print(a.name)
a._ROClass__name = "modify" 创建了新的属性,这样就能很好的保护可读属性不被修改。
建议62:掌握metaclass
什么是元类(metaclass)?
1)元类是关于类的类,是类的模板。
2)元类是用来控制如何创建类的,正如类是创建对象的模板一样。
3)元类的实例为类,正如类的实例为对象。
type可以这样使用:
type(类名, 父类的元组(针对继承的情况,可以为空), 包含属性的字典(名称和值))
当类中设置了__metaclass__属性的时候,所有继承自该类的子类都将使用所设置的元类来指导类的生成。
关于元类需要注意的几点:
1)区别类方法与元方法(定义在元类中的方法)。元方法可以从元类或者类中调用,而不能从类的实例中调用;但是类方法可以从类中调用,也可以从类的实例中调用。
2)多继承需要严格限制,否则会产生冲突
建议63:熟悉python对象协议
建议64:利用操作符重载实现中缀语法
建议73:理解单元测试概念
单元测试用来验证程序单元的正确性,一般由开发人员完成,是测试过程的第一个环节,以确保所写的代码符合软件需求和遵循开发目标。好的单元测试可以带来以下好处:
1)减少了潜在bug,提高了代码质量;
2)大大缩减软件修复的成本;
3)为集成测试提供基本保障。
有效的单元测试应该从以下几个方面考虑:
1)测试先行,遵循单元测试步骤。典型的单元测试步骤如下:
创建测试计划(Test Plan);
编写测试用例,准备测试数据;
编写测试脚本;
编写被测代码,在代码完成之后执行测试脚本;
修正代码缺陷,重新测试直到代码可以接受为止。
2)遵循单元测试基本原则。常见的原则如下:
一致性:意味着1000次执行和一次执行的结果应该是一样的,产生不确定执行结果的语句应该尽量避免;
原子性:意味着单元测试的执行结果返回只有两种:True和False,不存在部分成功、部分失败的例子。如果发生这样的情况,往往是测试设计的不够合理;
单一职责:测试应该基于情景和行为,而不是方法。如果一个方法对应着多种行为,应该有多个测试用例;而一个行为即使对应多个方法也只能有一个测试用例
隔离性:不能依赖于具体的环境设置,如数据库的访问、环境变量的设置、系统的时间等;也不能依赖于其他的测试用例以及测试执行的顺序,并且无条件逻辑依赖。单元测试所有的输入应该是确定的,方法的行为和结果应是可以预测的。
3)使用单元测试框架。python常见的测试框架有PyUnit
import unittest class MyCal(object): def add(self, a, b): return a + b def sub(self, a, b): return a - b class MyCalTest(unittest.TestCase): def setUp(self): print("running set up") self.mycal = MyCal() def tearDown(self): print("running teardown") self.mycal = None def testAdd(self): self.assertEqual(self.mycal.add(-1, 7), 6) def testSub(self): self.assertEqual(self.mycal.sub(10, 2), 8) suite = unittest.TestSuite() suite.addTest(MyCalTest("testAdd")) suite.addTest(MyCalTest("testSub")) runner = unittest.TextTestRunner() runner.run(suite)
运行命令:
python -m 包名 -v MyCalTest
建议74:为包编写单元测试
python自带的unittest模块,作为单元测试模块:
import unittest import test.demo1 as a class TestCase(unittest.TestCase): def test_add(self): self.assertEqual(a.add(1, 1),2) if __name__ == "__main__": unittest.main()
框架除了自动调用匹配以test开头的方法之外,unittest.TestCase还有模板方法setUp()和tearDown(),通过覆盖着两个方法,能够实现在测试之前执行一些准备工作,并在测试之后清理现场。
unittest测试发现功能(test discover)
python -m unittest discover
unittest将递归地查找当前目录下匹配test*.py模式的文件,并将其中unittest.TestCase的所有子类都实例化,然后调用相应的测试方法进行测试,这就一举解决了“通过一条命令运行全部测试用例”的问题。
建议75:利用测试驱动开发提高代码的可测性
测试驱动开发(TDD)是敏捷开发中一个非常重要的理念,它提倡在真正开始编码之前测试先行,先编写测试代码,再在其基础上通过基本迭代完成编码,并不断完善。其目的是编写可用的干净的代码。所谓可用就是能够通过测试满足基本功能需求,而干净则要求代码设计良好、可读性强、没有冗余。在软件开发过程中引入TDD能带一系列好处,如改进的设计、可测性的增强、更松的耦合度、更强的质量信心、更低的缺陷修复代价等。
测试驱动开发过程:
1)编写部分测试用例,并运行测试。
2)如果测试通过,则回到测试用例编写的步骤,继续添加新的测试用例。
3)如果测试失败,则修改代码直到通过测试。
4)当所有测试用例编写完成并通过测试之后,再来考虑对代码进行重构。
假设开发人员要编写一个求输入数列的平均数的例子:
1)完成基本的代码框架,便可以开始实施TDD的具体过程了:
def avg(x): pass
2)编写测试用例:
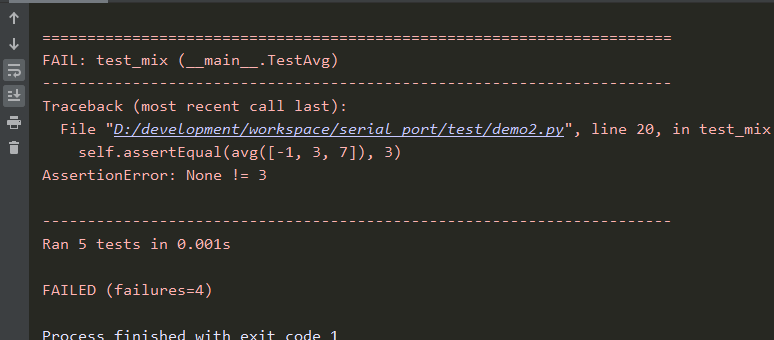
import unittest from test.demo1 import avg class TestAvg(unittest.TestCase): def test_int(self): print("test average of integers:") self.assertEqual(avg([0, 1, 2]), 1) def test_float(self): print("test average of float:") self.assertEqual(avg([1.2, 2.5, 0.8]), 1.5) def test_empty(self): print("test empty input:") self.assertFalse(avg([]), False) def test_mix(self): print("test with mix input:") self.assertEqual(avg([-1, 3, 7]), 3) def test_invalid(self): print("test with invalid input:") self.assertRaises(TypeError, avg, [-1, 3, [1, 2, 3]]) if __name__ == "__main__": unittest.main()
3)运行测试用例,测试结果显示失败
4)开始编码直到所有的测试用例通过,这是一个不停的重复迭代的过程,需要多次重复编码测试,直到上面的测试用例全部执行成功:
def avg(*x): if len(*x) <= 0: print("you need inpuit at least one number") return False try: return sum(*x) / len(*x) except TypeError: raise TypeError("your inpuit is not value with unsupported type")
5)重构,在测试用例通过之后,现在可以考虑一下重构的问题
关于测试驱动开发和提高代码可测性方面有以下几点需要说明:
(1)TDD只是手段而不是目的,因此在实践中尽量只验证正确的事情,并且每次仅仅验证一件事。当遇到问题时不要局限于TDD本身所涉及的一些概念,而应该回头想想采用TDD原本的出发点和目的是什么。
(2)测试驱动开发本身就是一门学问,不要指望通过一个简单的例子就掌握其精髓。如果需要更深入的了解,推荐阅读相关书籍的同时在实践中不断提高对其的领悟。
(3)代码的不可测性可以从以下几个方面考量:实践TDD困难;外部依赖太多;需要写很多模拟代码才能完成测试;职责太多导致功能模糊;内部状态过多且没有办法去操作和维护这些状态;函数没有明显返回或者参数过多;低内聚高耦合;等等。如果在测试过程中遇到这些问题,应该停下来想想有没有更好的设计。
建议81:利用cProfile定位性能瓶颈
profile是python的标准库。可以统计程序里每一个函数的运行时间,并且提供了多样化的报表,而cProfile则是他的C实现版本,剖析过程本身需要消耗的资源更少。所以在python3.0中,cProfile代替了profile,成为默认的性能剖析模块。使用cProfile来分析一个程序很简单:
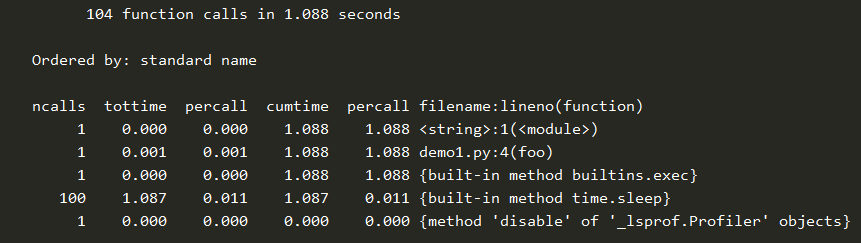
def foo(): sum = 0 for i in range(100): sum += i time.sleep(0.01) return sum if __name__ == "__main__": import cProfile cProfile.run("foo()")
cProfile还可以直接用python解释器调用cProfile模块来剖析python程序
python -m cProfile demo.py
执行结果
cProfile解决了我们对程序执行性能剖析的需求,但还有一个需求:以多种形式查看报表以便快速定位瓶颈。我们可以通过pstats模块的另一个类Stats来解决。Stas的构造函数接受一个参数——就是cProfile的输出文件名。Stats提供了对cProfile输出结果进行排序、输出控制等功能:
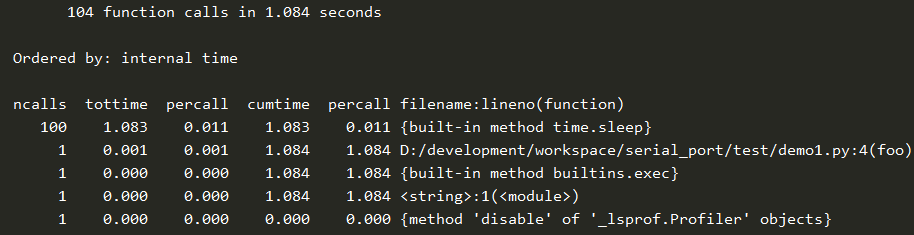
if __name__ == "__main__": import cProfile cProfile.run("foo()", "prof.txt") import pstats p = pstats.Stats("prof.txt") p.sort_stats("time").print_stats()
执行结果:
建议84:掌握循环优化的基本技巧
循环的优化应遵循的原则是尽量减少循环过程中的计算量,多重循环的情形下尽量将内层的计算提到上一层。
1)减少循环内部的计算。
2)将显示循环改为隐式循环。
sun = 0 for i in range(n+1): sum = sum + i
可以写成:n*(n+1)/2
3)在循环中尽量引用局部变量。
4)关注内层嵌套循环。在多层嵌套循环中,重点关注内层嵌套循环,尽量将内层循环的计算往上层移。