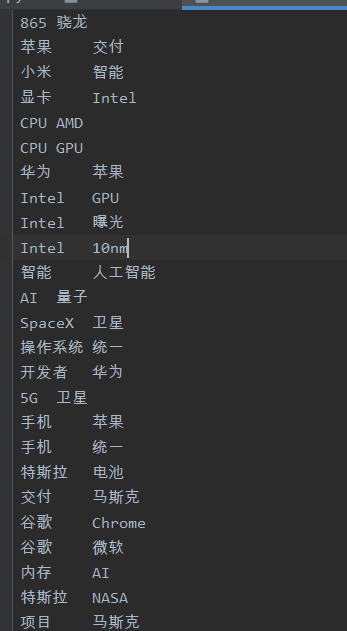
我根据爬取的链接和热词,进行分析,如果两个词或多个词的文章链接相同,且热词名字不同,那么就爬取对应文章的
内容,根据内容进行分词,得到两个词或多个词的词频,若是差别不大,即可认定两词之间的紧密程度高,同时出现的概率大。
最后就输出到相关文件中,每行为相关的热词。
代码如下


def dbwords_guanxi(): wordsname = dbgetWordsName() set_list = list(set(wordsname)) # 去重 set_list.sort(key=wordsname.index) #恢复顺序 yuanzu = dbgetHrefAndWordname() print(len(yuanzu)) #去重后的元组 yuanzu1 = tuple(set(yuanzu)) print(len(yuanzu1)) print(yuanzu1) #如果链接相同,热词不同,就得到链接。 hrefs = [] hotwords = [] for row in yuanzu1: hrefs.append(row[0]) hotwords.append(row[1]) print(hrefs) print(hotwords) hrefs2 = hrefs f = open("ConnectWord.txt", "a+",encoding='utf-8') for i in range(0,len(hrefs)): for j in range(0,len(hrefs2)): #链接相同且热词不同的情况,即为我们所需的第一步条件,两热词初步相关。 if hrefs[i] == hrefs2[j] and i != j: # print(i,j) # print(hotwords[i],hotwords[j]) #得到链接,根据链接爬取文章 #hrefs[i] getContentByHref(hrefs[i],hotwords[i],hotwords[j],f) def getContentByHref(href,hotword1,hotword2,f): print(href,hotword1,hotword2) head = { 'cookie': '_ga=GA1.2.617656226.1563849568; __gads=ID=c19014f666d039b5:T=1563849576:S=ALNI_MZBAhutXhG60zo7dVhXyhwkfl_XzQ; UM_distinctid=16cacb45b0c180-0745b471080efa-7373e61-144000-16cacb45b0d6de; __utmz=226521935.1571044157.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utma=226521935.617656226.1563849568.1571044157.1571044156.1; SyntaxHighlighter=python; .Cnblogs.AspNetCore.Cookies=CfDJ8Nf-Z6tqUPlNrwu2nvfTJEgfH-Wr7LrYHIrX6zFY2UqlCesxMAsEz9JpAIbaPlpJgugnPrXvs5KuTOPnzbk1pa_VZIVlfx1x5ufN55Z8sb63ACHlNKd4JMqI93TE2ONBD5KSWd-ryP2Tq1WfI9e_uTiJIIO9vlm54pfLY0fIReGGtqJkQ5E90ahfHtJeDTgM1RHXRieqriLUIXRciu-3QYwk8x5vLZfJIEUMO5g_seeG6G6FW2kbd6Uw3BfRkkIi-g2O_LSlBqj0DdbJFlNmd-TnPmckz5AENnX9f3SPVVhfmg7zINi4G2SSUcYWSvtVqdUtQ8o9vbBKosXoFOTUNH17VXX_IX8V0ODbs8qQfCkPFaDjS8RWSRkW9KDPOmXyqrtHvRXgGRydee52XJ1N8V-Mu0atT0zMwqzblDj2PDahV1R0Y7nBvzIy8uit15vGtR_r0gRFmFSt3ftTkk63zZixWgK7uZ5BsCMZJdhqpMSgLkDETjau0Qe1vqtLvDGOuBZBkznlzmTa-oZ7D6LrDhHJubRpCICUGRb5SB6WcbaxwOqE1um40OSyila-PgwySA; .CNBlogsCookie=9F86E25644BC936FAE04158D0531CF8F01D604657A302F62BA92F3EB0D7BE317FDE7525EFE154787036095256D48863066CB19BB91ADDA7932BCC3A2B13F6F098FC62FDA781E0FBDC55280B73670A89AE57E1CA5E1269FC05B8FFA0DD6048B0363AF0F08; _gid=GA1.2.1435993629.1581088378; __utmc=66375729; __utmz=66375729.1581151594.2.2.utmcsr=cnblogs.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utma=66375729.617656226.1563849568.1581151593.1581161200.3; __utmb=66375729.6.10.1581161200' } r2 = requests.get(href, headers=head) html = r2.content.decode("utf-8") html1 = etree.HTML(html) content1 = html1.xpath('//div[@id="news_body"]') #print(content1) if len(content1) == 0: print("异常") else: content2 = content1[0].xpath('string(.)') # print(content2) content = content2.replace(' ', '').replace(' ', '').replace(' ', '').replace(' ', '') # print(content) fenci(content,hotword1,hotword2,f) # f = open("news.txt", "a+", encoding='utf-8') # f.write(title + ' ' + content + ' ') # &emsp def fenci(content,hotword1,hotword2,f): # mystr = filehandle.read() seg_list = jieba.cut(content) # 默认是精确模式 #print(seg_list) # all_words = cut_words.split() # print(all_words) stopwords = {}.fromkeys([line.rstrip() for line in open(r'stopwords.txt')]) c = Counter() for x in seg_list: if x not in stopwords: if len(x) > 1 and x != ' ': c[x] += 1 print(' 词频统计结果:') # 创建热词文件 f = open("ConnectWord.txt", "a+", encoding='utf-8') number1 = 0 number2 = 0 word1='' word2='' for (k, v) in c.most_common(100): # 输出词频最高的前两个词 if k == hotword1 : number1 = v word1 = k #print(number1 ,word1) if k == hotword2: number2 = v word2 = k #print(number2, word2) #print("%s:%d" % (k, v)) numbercha = number2 -number1 if numbercha < 0: numbercha = -numbercha #print("差值:"+str(numbercha)) if numbercha <=5 and len(word1)!= 0 and len(word2)!= 0 and number1>3 and number2>3: print("有关联") # if len(word1) == 0: # word1 = print(word1,word2) f.write(word1+" "+word2+" ") #f.write(k + ' ') # print(mystr) #filehandle.close(); if __name__=='__main__': #热词关系图 dbwords_guanxi()
得到的相关联的热词如下: