1.字典操作:
定义:
{key1:value1,key2:value2},key-value结构,key必须可hash
特性:
1.可存放多个值
2.可修改指定key对应的值,可变
3.无序
1.1、增删改查
id_db = {
123 : {
'name':'freddy',
'age':'18',
'addr':'TangShan'
},
789 : {
'name':'freddie',
'age':'18',
'addr':'TangShan'
},
456 : {
'name':'tang',
'age':'18',
'addr':'TangShan'
},
}
【取字典id_db中,key为123的值:】
print(id_db[123])
【给字典中key为123,name值改成‘WeiGe’:】
id_db[123]['name']='WeiGe'
print(id_db[123])
【给字典id_db中,key为123中,增加一对值:】
id_db[123]['QQ']=88888888
print(id_db[123])
【pop,删除字典id_db中,key为123中,addr的值:】
id_db[123].pop('addr')
print(id_db[123])
【删除字典中id_db中key为456的key:】
del id_db[456]
print(id_db)
【get,取字典id_db中,key为1234的key,使用get取值,娶不到不会报错:】
v = id_db.get(1234)
print(v)
结果:
None
【清空字典】
dic={'k1':'v1','k2':'v2'}
dic.clear()
print(dic)
【浅copy字典】
food = {'1':'apple','2':'banana'}
newfood = food.copy()
print(newfood)
2.2、字典合并
dic_1 = {
'130282':{
'name':'freddy',
'age':23,
'addr':'TangShan',
}
}
dic_2 = {
'name':'WeiGe',
'130':{
'name':'freddie',
'age':888,
'addr':'BeiJing'
},
}
print(dic_1)
print(dic_2)
dic_1.update(dic_2)
print(dic_1)
2.3、取值
【items,把字典转换成列表,数据多的时候千万别这么干:】
dic_1 = {
130282 :{
'name':'freddy',
'age':23,
'addr':'TangShan',
}
}
print(dic_1)
print(dic_1.items())
print(type(dic_1.items()))
结果:
{130282: {'age': 23, 'name': 'freddy', 'addr': 'TangShan'}}
dict_items([(130282, {'age': 23, 'name': 'freddy', 'addr': 'TangShan'})])
<class 'dict_items'>
【keys,取dic_1中的key:】
print(dic_1.keys())
结果:
dict_keys([130282])
【values,取字典中所有的value:】
print(dic_1.values())
结果:
{'name': 'freddy', 'age': 23, 'addr': 'TangShan'}
【setdefault,取130282123这个key,要是没有130282123Key,则把130282123设置为字典的Key,value为None:】
print(dic_1.setdefault(130282123))
【setdefault,取130282123这个key,要是没有130282123Key,则把130282123设置为字典的Key,value为Tangshengwei:】
dic_1.setdefault(130282123,"Tangshengwei")
print(dic_1)
【fromkeys,给dic_1字典重新做赋值操作:】
print(dic_1.fromkeys([1,2,3,4,5],'aaa'))
结果:
{1: 'aaa', 2: 'aaa', 3: 'aaa', 4: 'aaa', 5: 'aaa'}
字典:
dic_1 = {
130282 :{
'name':'freddy',
'age':23,
'addr':'TangShan',
},
12345 :{
'name':'fr333eddy',
'age':33,
'addr':'3333',
}
}
【popitem,字典popitem()方法作用是:随机返回并删除字典中的一对键和值(项)。为什么是随机删除呢?因为字典是无序的,没有所谓的“最后一项”或是其它顺序。在工作时如果遇到需要逐一删除项的工作,用popitem()方法效率很高:】
dic_1.popitem()
print(dic_1)
【取字典的key,value:】
(方法一:效)
for k,v in dic_1.items():
print(k,v)
(方法二,效率高:)
for key in dic_1:
print(key,dic_1[key])
2、集合操作
定义:
由不同元素组成的集合,集合中是一组无序排列的可hash值,可以作为字典的key
特性:
集合的目的是将不同的值存放到一起,不同的集合间用来做关系运算,无需纠结于集合中单个值
【add,给set集合添加一个元素】 s = set() s.add('freddy') print(s) 【difference,打印出S1中有,S2中没有的元素】 s1 = {11,22,33} s2 = {22,33,44} s3=s1.difference(s2) print(s3) 【symmetric_difference,对称差集, 把S1中存在,S2中不存在的元素取出来, 并且把S2中存在,S1中不存在的元素取出来】 s1 = {11,22,33} s2 = {22,33,44} s3 = s1.symmetric_difference(s2) print(s3) ==update类型方法,主要应用在其他元素不会再使用的情况下,节省内存空间== 【difference_update,把S1中存在,S2中不存在的元素取出来,并重新赋值给S1】 s1 = {11,22,33} s2 = {22,33,44} s1.difference_update(s2) print(s1) 【symmetric_difference_update,把S1中存在,S2中不存在;S2中存在,S1中不存在的值取出来,重新赋值给S1】 s1 = {11,22,33} s2 = {22,33,44} s1.symmetric_difference_update(s2) print(s1) 【discard,移除指定元素,如果指定的移除元素不存在,不会报错】 s1 = {11,22,33} s2 = {22,33,44} s1.discard(22) print(s1) 【remove,移除指定元素,如果指定的移除元素不存在,会报错】 s1 = {11,22,33} s2 = {22,33,44} s1.remove(22) print(s1) 【pop,随机删除S1列表中的一个元素,不能指定移除的元素】 s1 = {11,22,33} res = s1.pop() print(res) 【intersection,取交集,把S1和S2相同的值取出来】 s1 = {11,22,33} s2 = {22,33,44} s3 = s1.intersection(s2) print(s3) 【intersection_update,取交集,把S1和S2相同的值取出来,并重新赋值给S1】 s1 = {11,22,33} s2 = {22,33,44} s1.intersection_update(s2) print(s1) 【isdisjoint,判断S1和S2有没有交集,没有交集为True,有交集为False】 s1 = {11,22,33} s2 = {44} res = s1.isdisjoint(s2) print(res) 【issubset,判断S1是否为S2的父序列,是为True,不是为False】 s1 = {11,22,33} s2 = {22,33} res = s2.issubset(s1) print(res) 【union,取并集,把S1和S2合并,并且把一样的元素去重】 s1 = {11,22,33} s2 = {22,33,44} res = s1.union(s2) print(res) 【update,给set集合增加元素,被增加的值可以为,列表,元组,字符串;update内部实现就是add】 s1 = {11,22,33} s2 = {11,22,33} s3 = {11,22,33} #列表 li=[1,2,3,4,5] #元组 tu=(1,2,3,4,5) #字符串 name='freddyfreddy' s1.update(li) s2.update(tu) s3.update(name) print(s1) print(s2) print(s3) 【set小练习,例子:服务器增加,减少内存】 old_dict = { "#1":8, "#2":4, "#4":2, } new_dict = { "#1":4, "#2":4, "#3":2, } new_set = set(old_dict.keys()) old_set = set(new_dict.keys()) print(new_set) print(old_set) remove_set = old_set.difference(new_set) print(remove_set) add_set = new_set.difference(old_set) print(add_set) update_set = old_set.intersection(new_set) print(update_set)
同样也可以使用下面的符号进行操作集合:
|,|=:合集
&.&=:交集
-,-=:差集
^,^=:对称差分
3、字符编码
字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题。
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
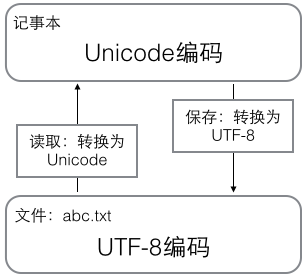
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
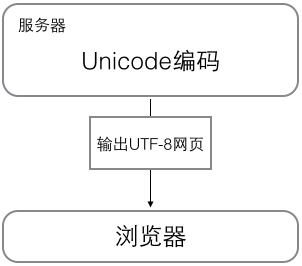
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
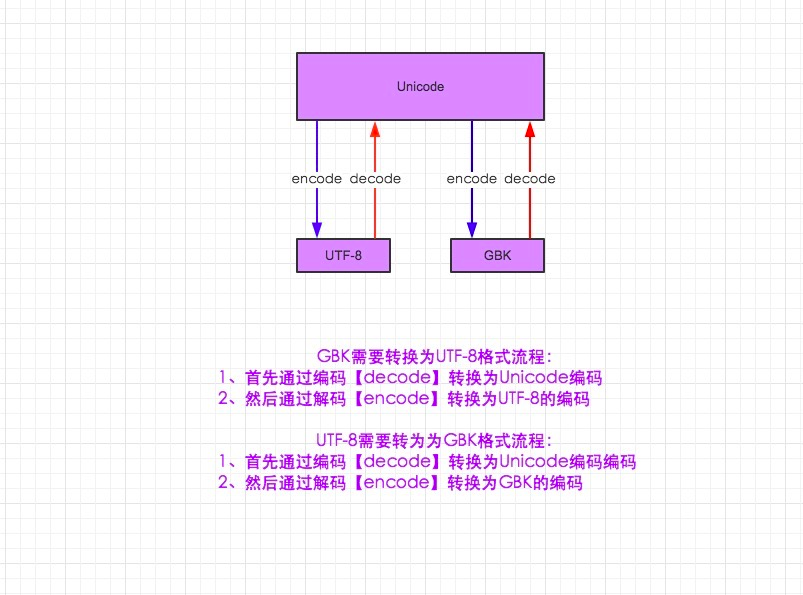
编码的转换流程:
4、文件处理
文件打开方式: python中打开文件有两种方式,即:open(...) 文件打开模式: r 【只读方式(默认)】 w 【打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件】 a 【打开一个文件用于追加写入。新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入】 w+ 【写读:打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件(没人用)】 “+” 【表示可以同时读写某个文件】 r+ 【可读;可写;可追加】 a+ 【等同于a】 “U”表示在读取时,可以将\r \n \r \n 自动换成\n【与 r 或 r+ 模式同使用】 rU r+U “b”表示处理二进制文件【如:FTP发送上传ISO镜像文件,linux可以忽略,windows处理二进制文件时需要标注】 rb wb ab
4.1、read()、readline()、readlines()
read():
读取指定数目个字节到字符串中,负数将读取至文件末尾,默认是-1
>>> file_obj = open('test.txt','r') >>> file_obj.read() 'dfdff\n' >>> file_obj.seek(0) >>> file_obj.read(0) '' >>> file_obj.read(1) 'd' >>> file_obj.read(2) 'fd' >>> file_obj.read(-1) 'ff\n' >>> file_obj.seek(0) >>> file_obj.read(1000) 'dfdff\n' >>> file_obj.seek(0) >>> file_obj.read(-5) 'dfdff\n'
readline():
读取文件的一行,包括行结束符,可以制定size参数的值,默认是-1
>>> file_obj = open('test.txt','r') >>> file_obj.readline() 'dfdff\n' >>> file_obj.readline(2) 'al' >>> file_obj.readline(-1) 'exzhou\n'
readlines():
读取所有剩余的行,然后作为一个字符串列表返回
>>> file_obj.seek(0) >>> file_obj.readlines() ['dfdff\n', 'alexzhou\n', 'zhoujianghai\n']
4.2、 write()、writelines()
ps:这两个方法都不会自动加上行结束符,需在写入数据前自己加上
>>> file_obj = open('test.txt','w+')
>>> file_obj.write('alexzhou')
>>> file_obj.write(' python')
>>> file_obj.seek(0)
>>> file_obj.readline()
'alexzhou python'
>>> l = ['my','name','is','zhoujianghai']
>>> l = ' '.join(l)
>>> file_obj.writelines(l)
>>> file_obj.seek(0)
>>> file_obj.readline()
'alexzhou pythonmy name is zhoujianghai'
>>> file_obj.write('hello \n')
>>> file_obj.write('world \n')
>>> file_obj.seek(0)
>>> file_obj.readline()
'alexzhou pythonmy name is zhoujianghaihello \n'
>>> file_obj.readline()
'world \n'
4.3、seek()、tell()
seek():移动文件指针到不同的位置,可以指定偏移量和起始位置。起始位置0表示从文件头开始,1表示从当前位置开始,2表示从文件尾开始,默认是0.
tell():表示当前文件指针在文件中的位置,从文件头算起。
>>> file_obj.seek(0) >>> file_obj.tell() 0 >>> file_obj.seek(5) >>> file_obj.tell() 5 >>> file_obj.seek(5,1) >>> file_obj.tell() 10 >>> file_obj.seek(5,2) >>> file_obj.tell() 57 >>> file_obj.seek(5,0) >>> file_obj.tell() 5