一.模块导入
1.import 2.为模块起别名:import ....as....
为已经导入的模块起别名的方式对编写可扩展的代码很有用,假设有两个模块xmlreader.py和csvreader.py,
它们都定义了函数read_data(filename):用来从文件中读取一些数据,但采用不同的输入格式。可以编写代码来选择性地挑选读取模块,
例如;
if file_format == 'xml':
import xmlreader as reader
elif file_format == 'csv':
import csvreader as reader
data=reader.read_date(filename)
--------------------------------------------
3.在一行导入多个模块:import sys,os,re
--------------------------------------
4.from …… import * # 所有的不是以下划线(_)开头的名字都导入到当前位置,很有可能会覆盖掉你之前已经定义的名字。而且可读性极其的差,在交互式环境中导入时没有问题。
from ... import....同样使用别名于多个模块
模块导入顺序:
# 内置模块
# 扩展的 django
# 自定义的
把模块当作脚本去执行(用于编译调试模块)
我们可以通过模块的全局变量__name__来查看模块名:
当做脚本运行:
__name__ 等于'__main__'
当做模块导入:
__name__= 模块名
作用:用来控制.py文件在不同的应用场景下执行不同的逻辑
if __name__ == '__main__':
def fib(n): a, b = 0, 1 while b < n: print(b, end=' ') a, b = b, a+b print() if __name__ == "__main__": print(__name__) #在模块本身文件中__name__输出__main__;在调用段则会输入模块文件名称,一次增加判断,有利于调试
num = input('num :') fib(int(num))
二.collections模块
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
因为tuple是不可变集合,则可以使用类似二维坐标样式访问
from collections import namedtuple point = namedtuple("point",["x","y"]) p = point(1,2) print(p.x)--------1 print(p.y)--------2 ---------------------------------------------- # 坐标与半径表示一个圆 Circle = namedtuple('Circle', ['x', 'y', 'r'])
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
queue---队列(先进先出)
#相对应传入一个,传出一个
import queue q = queue.Queue() q.put([1,2,3]) #传入数值 q.put(4) q.put(5) print(q.get())----------[1,2,3] #输出数值 print(q.get())-----------4 print(q.get())-----------5 print(q.qsize())---------0
deque双向列表,实现插入和删除操作的双向列表(deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),
这样就可以非常高效地往头部添加或删除元素。)
from collections import deque dq = deque([1,2]) dq.append('a') # 从后面放数据 [1,2,'a'] dq.appendleft('b') # 从前面放数据 ['b',1,2,'a'] dq.insert(2,3) #['b',1,3,2,'a']-----在索引前插入值 # print(dq.pop()) # 从后面取数据a # print(dq.pop()) # 从后面取数据2 # print(dq.popleft()) # 从前面取数据b print(dq)
3.Counter: 计数器,主要用来计数
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value
from collections import Counter c = Counter('abcdeabcdabcaba') print(c) -------------------------------------- Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
4.OrderedDict: 有序字典
因为字典dict的key是无序的,所以进行迭代时无法确定key值顺序,可以使用ordereDict:
from collections import OrderedDict od = OrderedDict([('a', 1), ('b', 2), ('c', 3)]) print(od) # OrderedDict的Key是有序的 print(od['a']) for k in od: print(k)
5.defaultdict: 带有默认值的字典
defaultdict的作用是在于,当字典里的key不存在但被查找时,返回的不是keyError而是一个默认值
#将所有大于66的值保存至字典的第一个key中,将小于66的值保存至第二个key的值中。
from collections import defaultdict
values = [11, 22, 33,44,55,66,77,88,99,90]
my_dict = defaultdict(list)
for value in values:
if value>66:
my_dict['k1'].append(value) #输入默认key值k1
else:
my_dict['k2'].append(value)
二.time模块
1.时间戳
import time print(type(time.time()))-----------float类型 print(time.time())--------------时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量
2.时间格式化
import time print(type(time.time())) print(time.strftime("%Y-%m-%d %H-%M-%S"))
----------------------------------------------------
%y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身
3.元组(struct_time) :struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
import time print(time.localtime())#localtime将一个时间戳转换为当前时区的struct_time ------------------------------------------ time.struct_time(tm_year=2019, tm_mon=6, tm_mday=28, tm_hour=8, tm_min=14, tm_sec=17, tm_wday=4, tm_yday=179, tm_isdst=0) ------------------------------------------------------------------
print(time.locatime().tm_year)---------2019
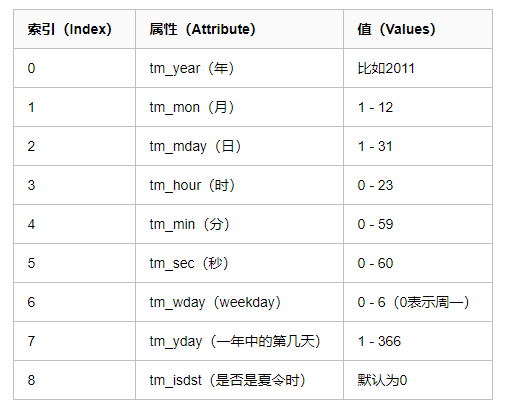
小结:时间戳是计算机能够识别的时间;时间字符串是人能够看懂的时间;元组则是用来操作时间的

#时间戳-->结构化时间(time.time()----struct_time) #time.gmtime(时间戳) #UTC时间,与英国伦敦当地时间一致 #time.localtime(时间戳) #当地时间。例如我们现在在北京执行这个方法:与UTC时间相差8小时,UTC时间+8小时 = 北京时间 >>>time.gmtime(1500000000) time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=2, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) >>>time.localtime(1500000000) time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) #结构化时间-->时间戳 #time.mktime(结构化时间) >>>time_tuple = time.localtime(1500000000) >>>time.mktime(time_tuple) 1500000000.0
#结构化时间-->字符串时间
#time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则显示当前时间
>>>time.strftime("%Y-%m-%d %X")
'2017-07-24 14:55:36'
>>>time.strftime("%Y-%m-%d",time.localtime(1500000000))
'2017-07-14'
#字符串时间-->结构化时间
#time.strptime(时间字符串,字符串对应格式)
>>>time.strptime("2017-03-16","%Y-%m-%d")
time.struct_time(tm_year=2017, tm_mon=3, tm_mday=16, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=75, tm_isdst=-1)
>>>time.strptime("07/24/2017","%m/%d/%Y")
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=205, tm_isdst=-1)
三.random 模块
>>> import random #随机小数 >>> random.random() # 大于0且小于1之间的小数 0.7664338663654585 >>> random.uniform(1,3) #大于1小于3的小数 1.6270147180533838 #恒富:发红包 #随机整数 >>> random.randint(1,5) # 大于等于1且小于等于5之间的整数 >>> random.randrange(1,10,2) # 大于等于1且小于10之间的奇数 #随机选择一个返回 >>> random.choice([1,'23',[4,5]]) # #1或者23或者[4,5] #随机选择多个返回,返回的个数为函数的第二个参数 >>> random.sample([1,'23',[4,5]],2) # #列表元素任意2个组合 [[4, 5], '23'] #打乱列表顺序 >>> item=[1,3,5,7,9] >>> random.shuffle(item) # 打乱次序 >>> item [5, 1, 3, 7, 9] >>> random.shuffle(item) >>> item [5, 9, 7, 1, 3]
1 )、random() 返回0<=n<1之间的随机实数n;
2 )、choice(seq) 从序列seq中返回随机的元素;
3 )、getrandbits(n) 以长整型形式返回n个随机位;
4 )、shuffle(seq[, random]) 原地指定seq序列;
5 )、sample(seq, n) 从序列seq中选择n个随机且独立的元素;
详细介绍:
random.random()函数是这个模块中最常用的方法了,它会生成一个随机的浮点数,范围是在0.0~1.0之间。
random.uniform()正好弥补了上面函数的不足,它可以设定浮点数的范围,一个是上限,一个是下限。
random.randint()随机生一个整数int类型,可以指定这个整数的范围,同样有上限和下限值,python random.randint。
random.choice()可以从任何序列,比如list列表中,选取一个随机的元素返回,可以用于字符串、列表、元组等。
random.shuffle()如果你想将一个序列中的元素,随机打乱的话可以用这个函数方法。
random.sample()可以从指定的序列中,随机的截取指定长度的片断,不作原地修改。
随机产生验证码
import random def v_code(): code = '' for i in range(5): num=random.randint(0,9) alf=chr(random.randint(65,90)) #通过ascill随机生成字母 add=random.choice([num,alf]) #随机选择字母/数值 code="".join([code,str(add)]) return code print(v_code())