内容:
1.解析器 源代码
2.异常模块源代码
3.响应模块
4.序列化组件
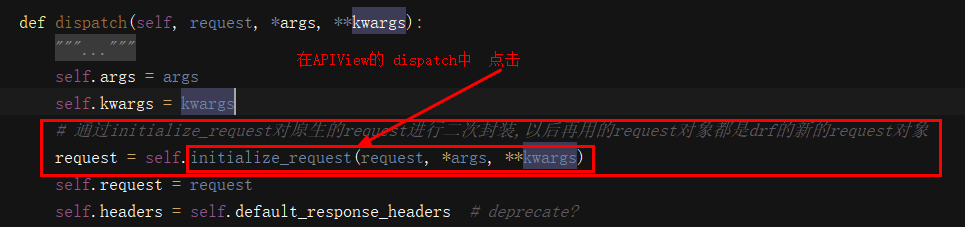
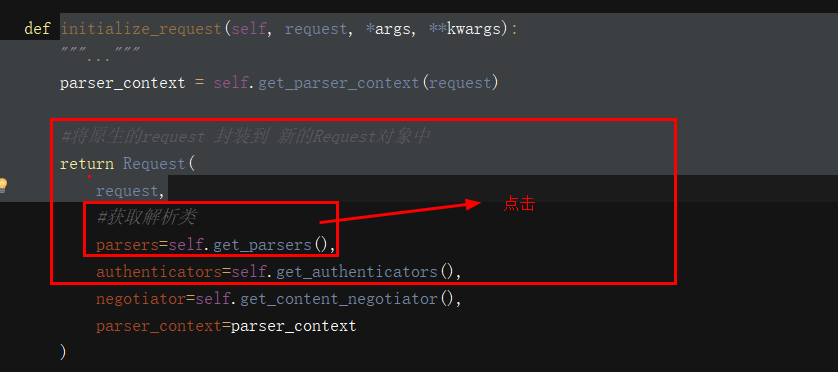
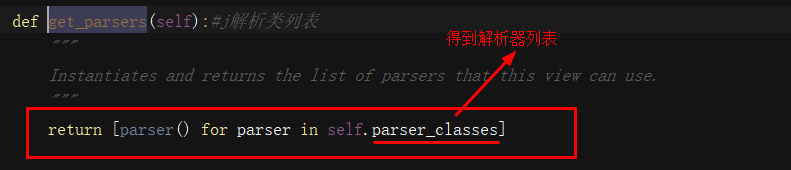
解析器:
解析模块
why配置解析模块:
1:drf给我们通过了多种解析数据包方式的 解析类
2.通过配置来控制前台提交的那些格式的数据后台在解析,那些数据不解析
3.根据配置规则选择性解析数据
全局配置就是针对每一个视图类;局部配置就是针对指定的视图类;
使用:
1.全局配置:项目settings.py文件
REST_FRAMEWORK = {
# 全局解析类配置
'DEFAULT_PARSER_CLASSES': [
'rest_framework.parsers.JSONParser', # json数据包
'rest_framework.parsers.FormParser', # urlencoding数据包
'rest_framework.parsers.MultiPartParser' # form-date数据包
],
}
2.局部配置:应用views.py的具体视图类
from rest_framework.parsers import JSONParser
class Book(APIView):
# 局部解析类配置,只要json类型的数据包才能被解析
parser_classes = [JSONParser]
pass
异常模块
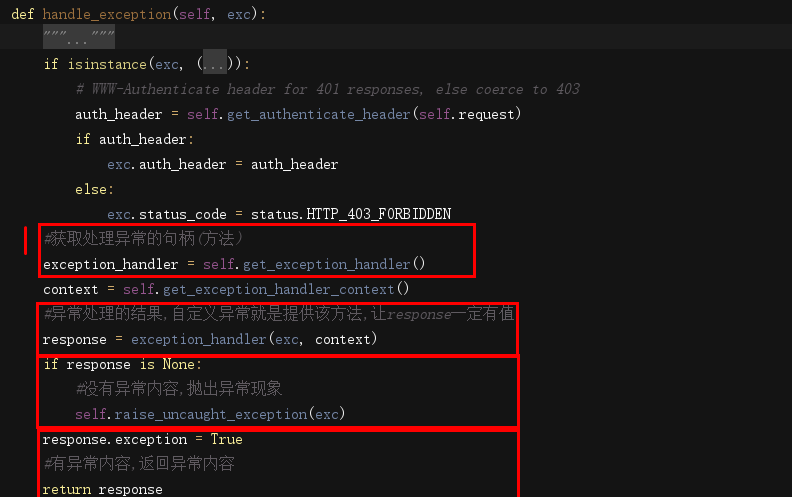
异常模块
why:
1.所有进过drf的 APIView视图类产生的异常,都可以提供异常处理方案
2.drf默认提供处理方案(rest_framework.views.exception_handler)但处理范围有效
3.drf提供的处理方案两种,处理了返回异常现象,没处理返回none(后续就是服务器抛异常给前台)
4.自定义异常的目的就是解决drf没有处里的异常,让前台得到合理的异常信息,后台记录异常具体信息
使用:自定义exception_handler函数如何书写实现体
1.修改自己配置的文件setting.py
REST_FRAMEWORK = {
# 全局配置异常模块
'EXCEPTION_HANDLER': 'api.exception.exception_handler',
}
eg:
1)先将异常处理交给rest_framework.views的exception_handler去处理
2)判断处理的结果(返回值)response,有值代表drf已经处理了,None代表需要自己处理
#自定义异常处理文件exception,在文件中书写exception_handler函数
from rest_framework.views import exception_handler as drf_exception_handler
from rest_framework.views import Response
from rest_framework import status
def exception_handler(exc, context):
# drf的exception_handler做基础处理
response = drf_exception_handler(exc, context)
# 为空,自定义二次处理
if response is None:
# print(exc)
# print(context)
print('%s - %s - %s' % (context['view'], context['request'].method, exc))
return Response({
'detail': '服务器错误'
}, status=status.HTTP_500_INTERNAL_SERVER_ERROR, exception=True)
return response

序列化组件:

序列化使用相关: 1.设置需要返回给前台的那些与model类有对应的字段,不返回的就不用设置了 2.设置方法字段,字段名随意,字段值有 get_字段名 提供,来完成一些需要处理再返回的数据 序列化组件: 为每一个model类通过一套序列化工具类,其工作方式与django的 froms组件非常类似 from rest_framework import serializers, exceptions from django.conf import settings from . import models class UserSerializer(serializers.Serializer): name = serializers.CharField() phone = serializers.CharField() # 序列化提供给前台的字段个数由后台决定,可以少提供, # 但是提供的数据库对应的字段,名字一定要与数据库字段相同 # sex = serializers.IntegerField() # icon = serializers.ImageField() # 自定义序列化属性 # 属性名随意,值由固定的命名规范方法提供: # get_属性名(self, 参与序列化的model对象) # 返回值就是自定义序列化属性的值 gender = serializers.SerializerMethodField() def get_gender(self, obj): # choice类型的解释型值 get_字段_display() 来访问 return obj.get_sex_display() icon = serializers.SerializerMethodField() def get_icon(self, obj): # settings.MEDIA_URL: 自己配置的 /media/,给后面高级序列化与视图类准备的 # obj.icon不能直接作为数据返回,因为内容虽然是字符串,但是类型是ImageFieldFile类型 return '%s%s%s' % (r'http://127.0.0.1:8000', settings.MEDIA_URL, str(obj.icon)) 视图层: 1)从数据库中将要序列化给前台的model对象,或是对个model对象查询出来 user_obj = models.User.objects.get(pk=pk) 或者 user_obj_list = models.User.objects.all() 2)将对象交给序列化处理,产生序列化对象,如果序列化的是多个数据,要设置many=True user_ser = serializers.UserSerializer(user_obj) 或者 user_ser = serializers.UserSerializer(user_obj_list, many=True) 3)序列化 对象.data 就是可以返回给前台的序列化数据 return Response({ 'status': 0, 'msg': 0, 'results': user_ser.data }) view: class User(APIView): def get(self, request, *args, **kwargs): pk = kwargs.get('pk') if pk: try: # 用户对象不能直接作为数据返回给前台 user_obj = models.User.objects.get(pk=pk) # 序列化一下用户对象 user_ser = serializers.UserSerializer(user_obj) # print(user_ser, type(user_ser)) return Response({ 'status': 0, 'msg': 0, 'results': user_ser.data }) except: return Response({ 'status': 2, 'msg': '用户不存在', }) else: # 用户对象列表(queryset)不能直接作为数据返回给前台 user_obj_list = models.User.objects.all() # 序列化一下用户对象 user_ser_data = serializers.UserSerializer(user_obj_list, many=True).data return Response({ 'status': 0, 'msg': 0, 'results': user_ser_data })

1)设置必填与选填序列化字段,设置校验规则 2)为需要额外校验的字段提供局部钩子函数,如果该字段不入库,且不参与全局钩子校验,可以将值取出校验 3)为有联合关系的字段们提供全局钩子函数,如果某些字段不入库,可以将值取出校验 4)重写create方法,完成校验通过的数据入库工作,得到新增的对象 class UserDeserializer(serializers.Serializer): # 1) 哪些自动必须反序列化 # 2) 字段都有哪些安全校验 # 3) 哪些字段需要额外提供校验 # 4) 哪些字段间存在联合校验 # 注:反序列化字段都是用来入库的,不会出现自定义方法属性,会出现可以设置校验规则的自定义属性(re_pwd) name = serializers.CharField( max_length=64, min_length=3, error_messages={ 'max_length': '太长', 'min_length': '太短' } ) pwd = serializers.CharField() phone = serializers.CharField(required=False) sex = serializers.IntegerField(required=False) # 自定义有校验规则的反序列化字段 re_pwd = serializers.CharField(required=True) 小结: name,pwd,re_pwd为必填字段 phone,sex为选填字段 五个字段都必须提供完成的校验规则 # 局部钩子:validate_要校验的字段名(self, 当前要校验字段的值) # 校验规则:校验通过返回原值,校验失败,抛出异常 def validate_name(self, value): if 'g' in value.lower(): # 名字中不能出现g raise exceptions.ValidationError('名字非法,是个鸡贼!') return value # 全局钩子:validate(self, 系统与局部钩子校验通过的所有数据) # 校验规则:校验通过返回原值,校验失败,抛出异常 def validate(self, attrs): pwd = attrs.get('pwd') re_pwd = attrs.pop('re_pwd') if pwd != re_pwd: raise exceptions.ValidationError({'pwd&re_pwd': '两次密码不一致'}) return attrs # 要完成新增,需要自己重写 create 方法 def create(self, validated_data): # 尽量在所有校验规则完毕之后,数据可以直接入库 return models.User.objects.create(**validated_data) """ 1)book_ser = serializers.UserDeserializer(data=request_data) # 数据必须赋值data 2)book_ser.is_valid() # 结果为 通过 | 不通过 3)不通过返回 book_ser.errors 给前台,通过 book_ser.save() 得到新增的对象,再正常返回 """ class User(APIView): # 只考虑单增 def post(self, request, *args, **kwargs): # 请求数据 request_data = request.data # 数据是否合法(增加对象需要一个字典数据) if not isinstance(request_data, dict) or request_data == {}: return Response({ 'status': 1, 'msg': '数据有误', }) # 数据类型合法,但数据内容不一定合法,需要校验数据,校验(参与反序列化)的数据需要赋值给data book_ser = serializers.UserDeserializer(data=request_data) # 序列化对象调用is_valid()完成校验,校验失败的失败信息都会被存储在 序列化对象.errors if book_ser.is_valid(): # 校验通过,完成新增 book_obj = book_ser.save() return Response({ 'status': 0, 'msg': 'ok', 'results': serializers.UserSerializer(book_obj).data }) else: # 校验失败 return Response({ 'status': 1, 'msg': book_ser.errors, })
响应器
响应模块 响应类构造器:rest_framework.response.Response def __init__(self, data=None, status=None, template_name=None, headers=None, exception=False, content_type=None): """ :param data: 响应数据 :param status: http响应状态码 :param template_name: drf也可以渲染页面,渲染的页面模板地址(不用了解) :param headers: 响应头 :param exception: 是否异常了 :param content_type: 响应的数据格式(一般不用处理,响应头中带了,且默认是json) """ pass 使用; status:就是解释一堆 数字 网络状态码的模块 form rest_framework import status #一般情况下只需要返回数据,status和headers都有默认值 如下: return Response(data={数据}, status=status.HTTP_200_OK, headers={设置的响应头})