CNN的一个问题是他不具备空间不变性。所谓空间不变性就是对input进行shift变换,得到的结果也是经过了相同shift变换的。某个可以识别出某个特征的filter,如果input放大实际上这个filter是无法识别出这个特征的。CNN网络可以识别出放大后的某个类别仅仅是因为训练集数据中包含了放大后的数据。虽然在CNN中引入了pooling层,但pooling只能带来局部的空间不变性。而且这是基于深层的pooling和conv,CNN中只有有限并且预定义的pooling机制用于处理数据中的空间变换。
因此本文的作者就提出一个设计好的专门用于进行空间变换的模块,Spatial Transformer。他可以针对输入产生相应的transformation,动态地进行变换。这使得使用ST模块的网络不仅可以选出图像中最相关的区域(Attention),还可以将这些区域变换成规范的、expected pose以简化后续层的recognition。ST模块只依赖于数据本身,不需要额外增加监督或改变优化过程。

平移旋转放大剪切的操作本质上可以看作是坐标变换的问题,可以表示为矩阵运算:
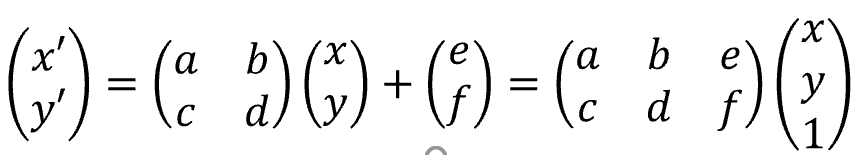
Spatial Transformer其实就是由三个部分实现这样一个变换。
Localisation net的输入是特征图U,输出是变换的参数。根据实际需要的变换形式的不同,可以输出不同size的参数。用一个神经网络学习这些参数,初始化为恒等变换,可以是任何形式的神经网络,但网络的最后层都要是一个regression。 根据这些参数grid generator中得到一组需要被sample的特征图中的点。这一部分的主要目的就是为了得到输出图中每个坐标对应到输入的位置,进而得到对应的像素值。计算对应到输入的坐标时可能会产生小数结果,sampler主要处理这个问题。对于可能会出现小数问题,如果只是简单的采用四舍五入的方法,会导致无法进行gradient descent。原因是如果参数改变,计算得到的值虽然也会改变,但有可能由于四舍五入,输出的结果并没有改变,这使得参数无法backprop更新。因此在这里作者采用了interpolation的方式。
Spatial Transformer模块可以加入到CNN网络的任意位置,也可以加入多个,他的计算速度很快,也不会影响训练速度。