知识内容:
1.数据库的关系规范化理论
2.数据库设计概述
3.数据库的需求分析
4.数据库的概念设计
5.数据库的逻辑结构设计
一、数据库的关系规范化理论
1.什么是关系规范化理论
关系规范化理论是数据库设计的指导理论,将关系划分为不同的规范层级,每一层级规定相应的判别标准,衡量这些层级的概念叫范式(NF:Normal Form)
范式详细情况见下面的解释
2.函数依赖
什么是函数依赖:简单点说就是:某个属性集决定另一个属性集时,称另一属性集依赖于该属性集
函数依赖分类:
- 完全函数依赖 :若X→Y,而X的任意真子集不决定Y,则Y完全函数依赖于X
- 部分函数依赖 :若X→Y,而存在X的真子集也决定Y,则Y部分函数依赖于X
- 传递函数依赖 :若X→Y(并且Y不决定X), Y→Z(Z不是Y的子集),则Z传递函数依赖于X
3.范式
范式: 关系模式满足的确定约束条件即是范式
数据库的设计范式是数据库设计所需要满足的规范,满足这些规范的数据库是简洁的、结构明晰的,同时不会发生插入、删除和更新操作异常
数据库的范式有1NF2NF3NFBCNF4NF5NF,一般的应用做到前3个范式的规范化要求即可
- 第一范式:关系的属性不可分
- 第二范式:关系中不存在非主属性对主属性的部分函数依赖
- 第三范式:关系中不存在非主属性对主属性的部分函数依赖和传递函数依赖
- BC范式:如果复合关键字,则复合关键字之间也不能存在传递函数依赖关系。(即把第三范式中的非关键字段升级为关键字及其分关键字段)
总结:
- 第一范式消除部分函数依赖 -> 第二范式
- 第二范式消除传递函数依赖 -> 第三范式

4.关系模式的分解
(1)保持函数依赖分解
类似以下的分解就是保持函数依赖的分解
R(A, B, C): A->B、B->C 分解为 R1(A,B)、R2(B,C)
注:冗余的依赖不需要保持下来!
实例:
1 例如2NF关系模式SL(Sno,Sdept,Sloc)中有下列函数依赖:
2 Sno→Sdept
3 Sdept→Sloc
4 Sno→Sloc
5
6 由于关系模式SL存在传递函数依赖,会出现插入异常、数据冗余、删除异常等问题
7
8 关系模式SL出现上述问题的原因是Sloc传递函数依赖于Sno。为了消除该传递函数依赖,我们可以采用投影分解法(保持函数依赖分解),把SL分解为两个关系模式:
9 SL(Sno,Sdept,Sloc)
10 SD(Sno,Sdept) SD的码为Sno
11 DL(Sdept,Sloc) DL的码为Sdept
(2)无损分解(可以还原)
无损分解:指将一个关系模式分解成若干个关系模式后,通过自然连接和投影等运算仍能还原到原来的关系模式
实例:
1 学生(学号, 姓名, 性别, 专业号, 专业名)
2 这个关系模式明显存在问题,主键为学号和专业号,但是存在部分函数依赖
3
4 解决这些问题的方法就是采取无损分解将以上的关系模式分解为两个关系模式:
5 学生(学号,姓名,性别,专业号)
6 专业(专业号,专业名)
二、数据库设计概述
1.什么是数据库设计
数据库设计是根据用户需求设计数据库结构的过程。具体一点讲,数据库设计是对于给定的应用环境,在关系数据库理论的指导下,构造最优的数据库模式,在数据库管理系统上建立数据库及其应用系统,使之能有效地存储数据,满足用户的各种需求的过程。
数据库设计过程如下:

2.数据库设计中的一些基础概念
(1)关系模式
数据库模式(Schema)是数据库中全体数据的逻辑结构和特征的描述,关系型数据库的模式又叫关系模式,关系模式就是数据库中表结构的定义以及多张表之间的逻辑联系
关系模式的设计就是根据一个具体的应用,把现实世界中的关系用表的形式来表示的逻辑设计过程,不规范的关系模式设计会带来以下的问题:
- 数据冗余
- 更新异常
- 插入异常
- 删除异常
下表中描述了老师信息(一个老师一个地址,可以教多门课,一门课只有一名老师):
| Tname | Addr | C#(PK) | Cname |
|---|---|---|---|
| T1 | A1 | C1 | N1 |
| T1 | A1 | C2 | N2 |
| T1 | A1 | C3 | N3 |
| T2 | A2 | C4 | N4 |
| T2 | A2 | C5 | N5 |
| T3 | A3 | C6 | N6 |
- 数据冗余:T1老师的地址A1记录了三次,冗余
- 更新异常:更新了某个元组中T1老师的地址A1,其余两个没有更新,DBMS不会检测到不一致,这是逻辑上的不一致而非数据库不一致
- 插入异常:无法插入一个还未带课的新老师,因为无C#违反主键约束
- 删除异常:T3老师不带C6这门课了,删除元组时却把T3老师的个人信息如地址等删去
解决上述问题最简单的方法是模式分解,将教师信息和课程信息独立出来
(2)键(码)
- 主属性:表示在候选键中的属性
- 超键:是指能够唯一标识一个元组的属性集
- 候选键:能够唯一标识一个元组,且不含多属性
- 主键:用户选作元组标识的候选键
- 外键:本联系中不作为主键,单在其他关系中作为主键的属性或属性组
3、数据库设计流程
(1)数据库设计流程: 需求分析、概念结构设计、逻辑结构设计和物理结构设计
- 需求分析: 数据是什么,有哪些属性,数据和属性的特点(存储特点),数据的生命周期
- 概念结构设计: 产生ER模型
- 逻辑结构设计: 使用ER图对数据库进行逻辑设计(将E-R图转化成关系模式)
- 物理结构设计: 存储形式和路径
(2)优良的数据库设计:
- 减少数据冗余
- 避免数据维护异常
- 节约存储空间
- 高效的访问
三、数据库的需求分析
1.需求分析概述
数据需求分析是从对数据进行组织与存储的角度,从用户视图出发,分析与辨别应用领域所管理的各类数据项和数据结构,形成数据字典的主要内容
2.需求分析的任务
- 确认需求,明确设计目标
- 分析收集来的数据:SA方法(数据流图、数据字典)
- 整理文档,写需求说明书
四、数据库的概念设计
1.概念设计
概念设计的任务是在需求分析阶段产生的需求说明书的基础上,按照特定的方法抽象为一个不依赖于任何具体机器的数据模型,即概念模型
将需求分析得到的用户需求抽象为信息结构即概念模型的过程就是概念设计,概念设计是整个数据库设计的关键
概念设计的特点
- 能真实、充分地反映现实世界
- 易于理解
- 易于更改
- 易于向关系、网状、层次等各种数据模型转换
描述概念模型的工具 -> E-R模型
注:概念模型独立于具体的DBMS
2.局部视图设计
(1)确定局部视图的范围
局部视图确定的基本原则:
- 各个局部视图支持的功能域之间的联系应最少
- 实体的个数应适当(5-9个)
局部视图的确定过程:
- 首先明确局部应用的范围。
- 选择实体,确定实体的属性及标识实体的关键字
- 确定实体之间的联系,产生局部模型
(2)识别实体及其标识
实体: 客观存在并可以区分的事物。实体可以是具体的人或物,如学生、桌子
标识: 也就是属性,属性是实体所具有的特性,比如学生的学号、性别、年龄等属性特征
(3)确定实体间的联系
实体间的联系:
- 一对一联系(1:1)
- 一对多联系(1:m)
- 多对多联系(m:n)
(4)分配实体及联系的属性
- 非空值原则: 一个属性在分配给实体或联系时应尽量避免使属性值出现空值的分配方案
- 增加一个新的实体或联系: 有时候分配属性时,会出现找不到合适的实体的联系,这时候就要选择是否增加一个新的实体或联系
3.局部E-R模型的集成
(1)集成的方法
- 多个E-R图一次性集成
- 逐步集成,用累加的方式一次集中两个局部E-R图
(2)冲突的分类
- 属性冲突: 属性域或属性取值冲突
- 命名冲突: 同名异义冲突、异名同义冲突
- 结构冲突: 同一对象在不同应用中具有不同的抽象(叫法不一样),同一实体在不同局部E-R图中的属性个数或属性排序不完全一样
(3)冲突的解决
开发人员和用户协商讨论解决,适当调整属性的次序,调整命名
五、数据库的逻辑结构设计
E-R图向关系模型的转换
E-R图向关系模型的转换要解决的问题是如何将实体型和实体间的联系转换为关系模式以及如何确定这些关系模式的属性和码
将E-R图转换为关系模型:将实体、实体的属性和实体之间的联系转换为关系模式。
实体型间的联系有以下不同情况 :
1 (1)一个1:1联系可以转换为一个独立的关系模式,也可以与任意一端对应的关系模式合并。 转换为一个独立的关系模式 与某一端实体对应的关系模式合并 2 3 (2)一个1:n联系可以转换为一个独立的关系模式,也可以与n端对应的关系模式合并。 转换为一个独立的关系模式 与n端对应的关系模式合并 4 5 (3) 一个m:n联系转换为一个关系模式。 例,“选修”联系是一个m:n联系,可以将它转换为如下关系模式,其中学号与课程号为关系的组合码: 6 选修(学号,课程号,成绩)
转换实例:

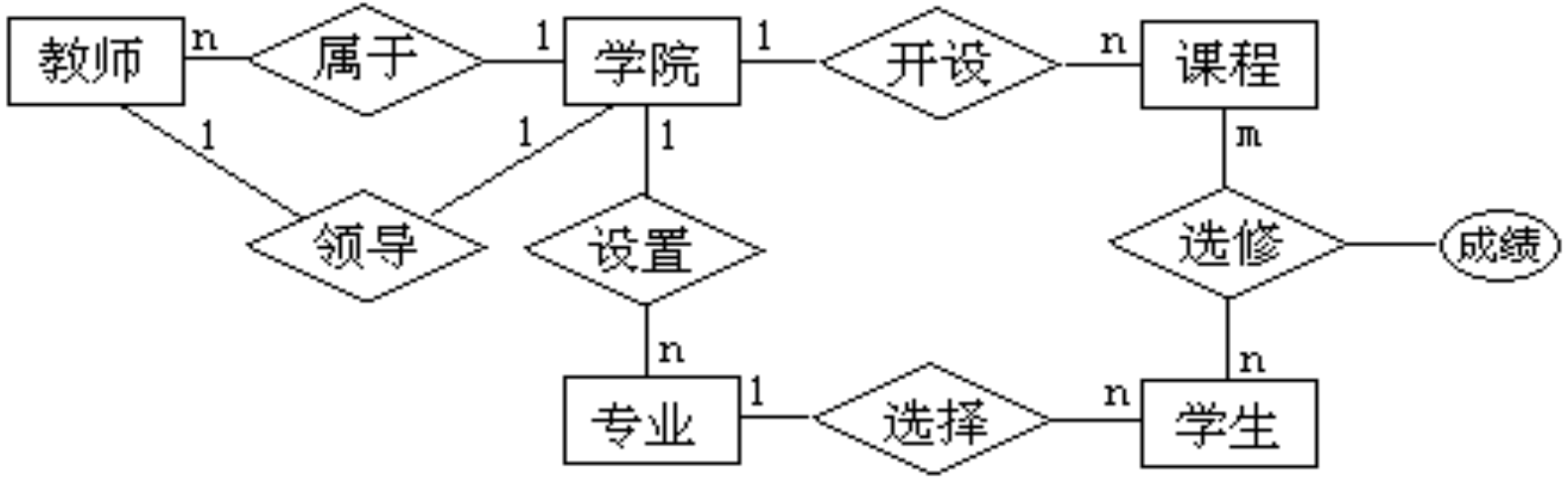
以上的联系和实体:
六个联系: 五个实体:
隶属(教师,学院) 教师(教师编号,姓名,性别,生日,民族,职称)
领导(学院,教师) 学生(学号,姓名,性别,生日,民族, 籍贯,简历,照片)
设置(专业,学院) 专业(专业编号,专业名称,专业类别)
开设(课程,学院) 课程(课程编号,课程名, 课程类别,学分)
选择(学生,专业) 学院(学院编号,学院名,院长)
选修(学生,课程)
将六个联系转换为关系模式:
(1)属于(教师,学院) n:1联系
- 教师(教师编号,姓名,性别,生日,民族,职称,基本工资)
- 学院(学院编号,学院名,院长)
合并后的关系模式: 教师(教师编号,姓名,性别,生日,职称,学院编号,基本工资)
(2)设置(专业,学院) n:1联系
- 专业(专业编号,专业名称,专业类别)
- 学院(学院编号,学院名,院长)
合并后的关系模式: 专业(专业编号,专业名称,专业类别,学院编号)
(3)领导(学院,教师) 1:1联系
- 学院(学院编号,学院名,院长)
- 教师(教师编号,姓名,性别,生日,民族,职称,基本工资)
合并后的关系模式: 学院(学院编号,学院名,院长) 或 学院(学院编号,学院名,院长,教师编号)
(4)选修(学生,课程) m:n联系
- 学生(学号,姓名,性别,生日,民族,籍贯,简历,照片)
- 课程(课程编号,课程名,课程类别,学分)
单独成立一个关系模式来表示: 成绩(学号,课程编号,成绩)
(5)开设(课程,学院) n:1联系
- 课程(课程编号,课程名,课程类别,学分)
- 学院(学院编号,学院名,院长)
合并后的关系模式: 课程(课程编号,课程名,课程类别,学分,学院编号)
(6)选择(学生,专业) n:1联系
- 学生(学号,姓名,性别,生日,民族,籍贯,简历,照片)
- 专业(专业编号,专业名称,专业类别)
合并后的关系模式: 学生(学号,姓名,性别,生日,民族,籍贯,专业编号,简历,照片)
最后转换完成的关系模式:
1 五个实体转化为关系模式: 2 学院(学院编号,学院名,院长) 3 教师(教师编号,姓名,性别,生日,民族,职称,基本工资) 4 学生(学号,姓名,性别,生日,民族,籍贯,简历,照片) 5 课程(课程编号,课程名,课程类别,学分) 6 专业(专业编号,专业名称,专业类别) 7 8 六个联系转化为关系模式: 9 学院(学院编号,学院名,院长) 10 专业(专业编号,专业名称,专业类别,学院编号) 11 课程(课程编号,课程名,课程类别,学分,学院 编号) 12 教师(教师编号,姓名,性别,生日,职称,学院编号,基本工资) 13 学生(学号,姓名,性别,生日,民族,籍贯,专业编号,简历,照片) 14 成绩(学号,课程编号,成绩)