一 pod的自动伸缩容的应用背景
在面对负载并发过高的时候,我们或许希望能够提高RS,RC以及Deployment等的replicas的参数来增加pod的cpu,mem等,或者是通过提高每个容器的requests的值,进而来提升系统的负载能力,但是我们可以通过手动的方式去调节RS,RC以及deployment的replicas的值,但是在面对突如其来的高负载进入,又或者是在夜深人静的夜晚突然到来的流量,通过手动的方式去扩容这些pod的方法,在某种意义上面而言,显得过于劳民伤财,并且也不一定及时。
二 pod的横向自动伸缩
2.1 横向pod的自动伸缩是指由控制器管理的pod副本数量的自动伸缩功能,它由Horizontal控制器执行,我们需要通过创建一个HorizontalpodAutoSccler(HPA)资源来启用和配置Horizontal的控制器,该控制器周期性检查pod度量,计算满足HPA资源目标值所需的副本数量,进而调整目标资源的replcas的数量来实现自动化伸缩。
- 获取被伸缩的pod资源对象所管理pod的度量
- 计算使目标资源度量数值接近或者达到目标数值所需的pod数量
- 更新被伸缩资源的replicas字段
2.2 获取pod的度量
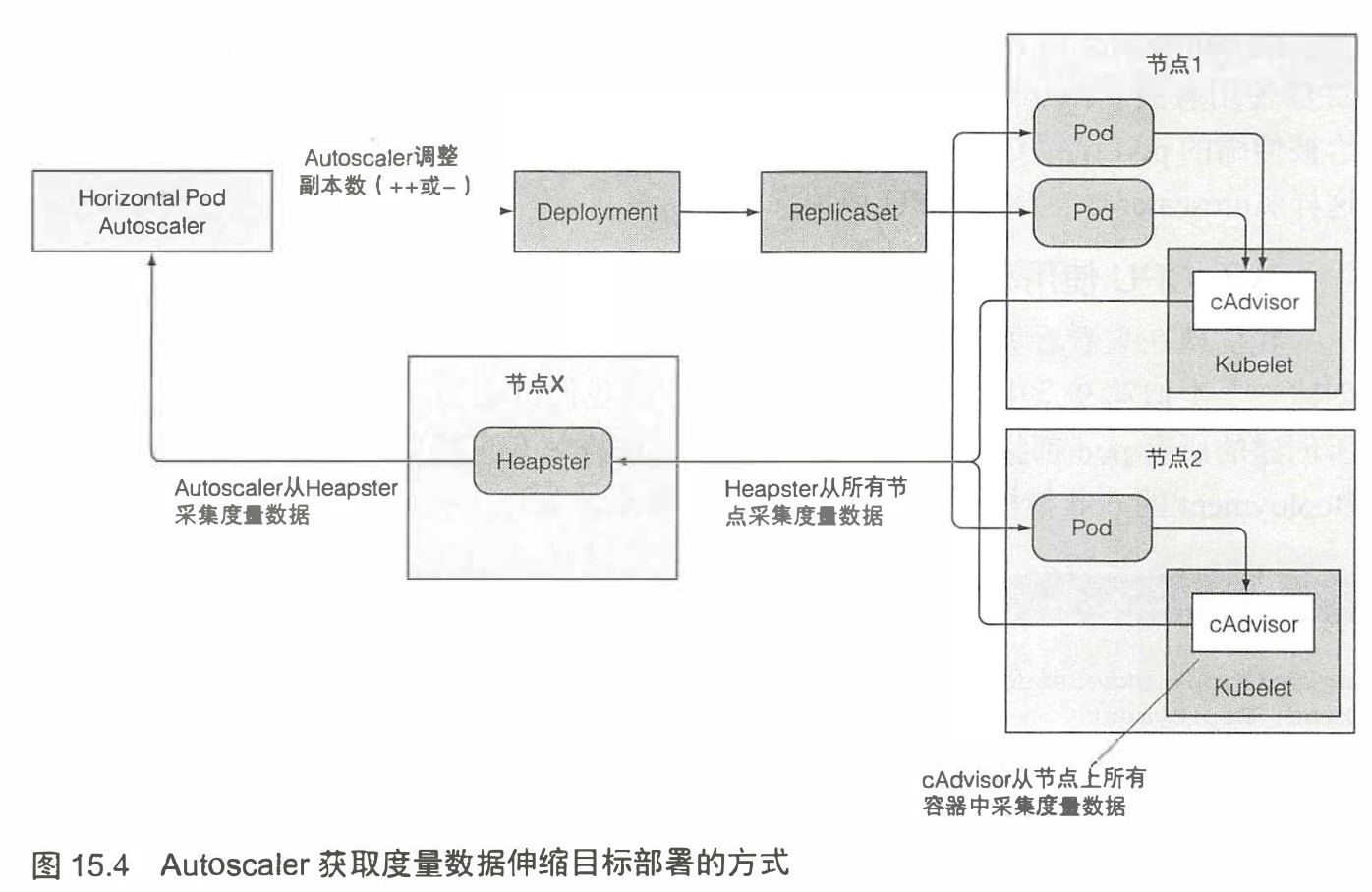
大概流程是每个节点上面的kubelet上面的cAdvsor的agent会去采集该节点上面的所有pod的资源使用量,之后这些数据将由集群级别的组件Heapster聚会,HPA控制器向Heapster发起post
请求调用所有pod的数量度量,整个数据的 采集调用链如图所示:

2.3 计算所需的pod数量
对于只一个指标例如cpu的度量,只需要采集节点上面的cpu消耗之和,之后除以标准的值就是那个时刻该pod的最佳量,当然遇到分数或者小数的时候进行取整,也就是需要调整到的量
但是对于多个需要的度量,例如cpu以及QPS 有2个度量的时候,其每个度量都可以单独的按照度量标准计算,之后对于每个度量取得的最佳pod数量取最大值,这个文字描述可能不算准确,可以通过下面的一幅图来直观的描述上面的内容
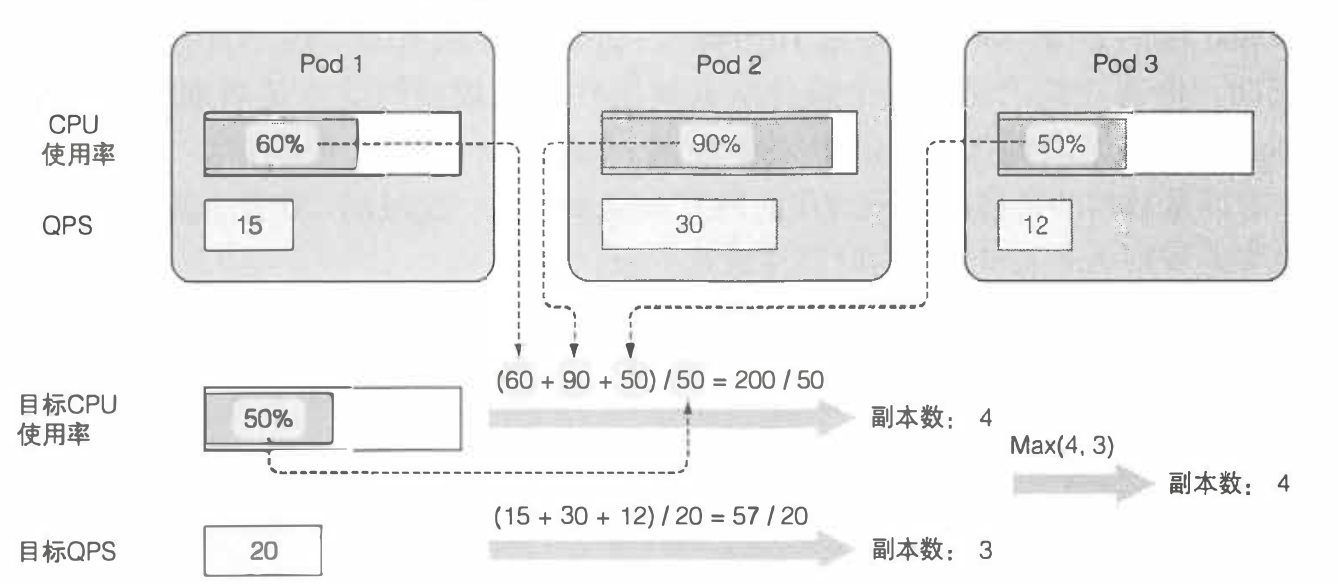
- 这三个pod的QPS以及CPU使用率的标准值是50,以及20
- 通过计算总和除以均值分别得到pod的数量应为3,4,这里我们应当取最大值
2.4 更新被伸缩资源的副本数
Autoscale控制器通过子资源Scale子资源来修改replicas进入达到对replicas进行修改,进而实现对pod进行阔缩容

2.5 只要API服务器为某个可伸缩资源爆露了子Scale资源,AutoScale即可以操作该资源,目前暴露子资源的有
-
- Deployment
- ReplicaSet
- ReplicationController
- StatefulSet
2.6 下面用一幅图来描述整个伸缩的过程
值得一提的是,由于cAdvisor需要周期性的拉取节点上面pod的配置,同理Heapster以及HPA控制器都是如此,所以在探测到需要扩缩容到实际完成的话,需要相当的一段时间,具体如下图所示
三 通过一个实例来描述整个流程是什么样子的
3.1 创建一个用来伸缩的deployment
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: kubia spec: replicas: 3 template: metadata: name: kubia labels: app: kubia spec: containers: - image: luksa/kubia:v1 name: nodejs resources: requests: cpu: 100m memory: 100Mi
3.2 之后创建一个HPA用以对这个deployment进行伸缩管控
k autoscale deployment kubia --cpu-percent=30 --min=1 --max=5 [root@node01 Chapter15]# k get hpa -o yaml apiVersion: v1 items: - apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler ...... spec: maxReplicas: 5 minReplicas: 1 scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: kubia targetCPUUtilizationPercentage: 30 status: currentReplicas: 3 desiredReplicas: 0 kind: List metadata: resourceVersion: "" selfLink: ""
- 这里分别注明来最大的副本数量以及最小的副本数量
- scaleTargetRef里面加上来伸缩的对象
- 同样上面红色部分还显示了pod的标准值以及资源状态
3.3 第一状态,由于一开始创建之初,并没有任何的流量会进来,所以hpa会通过scale将pod的副本数量逐渐缩容到1,并且当使用k describe hpa的时候会显示整个事情发生的过程,
之后需要让其扩容,通过一个服务来暴露这个deployment,最简单的就是使用
k expose deployment kubia --port=80 --target-port=8080
3.4 了解伸缩操作的最大速率
在伸缩的时候一般是当前已经存在的一倍,不会超过最大以及最小值
3.5 集群的横向伸缩
当在部署一个pod的时候,如果集群中任意一个节点都无法容纳它,那么我们就说这个集群里面的节点需要扩容了,并且在集群长时间资源空闲的时候下线机器,以此来对kubernetes来提供最大的机器资源利用量,这个操作对象叫clusterAutoscale,当某个节点上面的所有pod的请求量的cpu以及内存的使用量都不超过请求量的50%,那么clusterAutoScale则将会其视为需要下线的节点之一,第二个条件就是会检查上面是否存在不能挪走的pod例如系统pod,换言之,即该机器上面的pod都可以重新的去调度到其他的节点上面就可以标记下线,被标记下线的节点会被标记为不可调度。
3.6 确保即使因为节点上面被下线了,也能保证pod能够足量运行的资源podDisruptionBudget
通过命令行的形式创建一个pdb形式如下
k create pdb kubia-pdb --selector=app=kubia --min-available=3