1.Scrapy框架简介
1.1 Scrapy框架介绍
写一个爬虫,需要做很多的事情。比如:发送网络请求、数据解析、数据存储、反反爬虫机制(更换ip代理、设置请求头等)、异步请求等。这些工作如果每次都要自己从零开始写的话,比较浪费时间。因此Scrapy把一些基础的东西封装好了,在他上面写爬虫可以变的更加的高效(爬取效率和开发效率)。因此真正在公司里,一些上了量的爬虫,都是使用Scrapy框架来解决。
1.2 Scrapy架构图
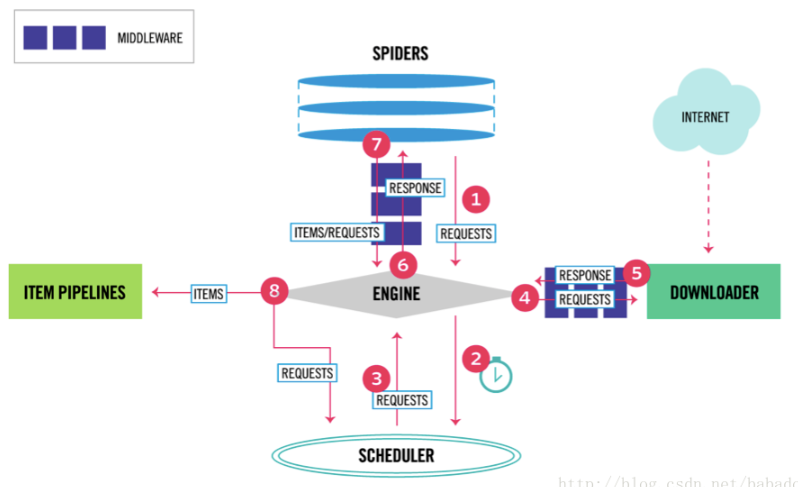
Scrapy框架模块功能:
Scrapy Engine(引擎):Scrapy框架的核心部分。负责在Spider和ItemPipeline、Downloader、Scheduler中间通信、传递数据等。Spider(爬虫):发送需要爬取的链接给引擎,最后引擎把其他模块请求回来的数据再发送给爬虫,爬虫就去解析想要的数据。这个部分是我们开发者自己写的,因为要爬取哪些链接,页面中的哪些数据是我们需要的,都是由程序员自己决定。Scheduler(调度器):负责接收引擎发送过来的请求,并按照一定的方式进行排列和整理,负责调度请求的顺序等。Downloader(下载器):负责接收引擎传过来的下载请求,然后去网络上下载对应的数据再交还给引擎。Item Pipeline(管道):负责将Spider(爬虫)传递过来的数据进行保存。具体保存在哪里,应该看开发者自己的需求。Downloader Middlewares(下载中间件):可以扩展下载器和引擎之间通信功能的中间件。你可用该中间件做以下几件事- )process a request just before it is sent to the Downloader (i.e. right before Scrapy sends the request to the website);
- )change received response before passing it to a spider;
- )send a new Request instead of passing received response to a spider;
- ) pass response to a spider without fetching a web page;
Spider Middlewares(Spider中间件):可以扩展引擎和爬虫之间通信功能的中间件。
在Scrapy的数据流是由执行引擎控制,具体流程如下:
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
- (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
2. Scrapy框架快速入门
2.1 scrapy安装与文档
- 安装:通过
pip install scrapy即可安装。 - Scrapy官方文档:http://doc.scrapy.org/en/latest
- Scrapy中文文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
#Windows平台 1、pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs 3、pip3 install lxml 4、pip3 install pyopenssl 5、下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/pywin32/ 6、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 7、执行pip3 install 下载目录Twisted-17.9.0-cp36-cp36m-win_amd64.whl 8、pip3 install scrapy #Linux平台 1、pip3 install scrapy 注意:
如果windows环境下直接通过pip install scrapy命令行安装,报以下错误时: 在windows系统下,提示错误ModuleNotFoundError: No module named 'win32api',那么使用以下命令可以解决:pip install pypiwin32。 在windows系统下,提示错误:error: Microsoft Visual C++ 14.0 is required.那么可以在网址https://www.lfd.uci.edu/~gohlke/pythonlibs/下载Twisted模块,安装该模块后,再重新使用命令行安装pip install scrapy安装scrapy模块
2.2 创建项目和爬虫
2.2.1 创建项目
要使用Scrapy框架创建项目,需要通过命令来创建。首先进入到你想把这个项目存放的目录。然后使用以下命令创建:
scrapy startproject [项目名称]
2.2.2 创建爬虫
创建爬虫:进入到项目所在的路径,执行命令“scrapy genspider [爬虫名] [爬虫域名]”
注意:爬虫名不能和创建的项目名一致
创建完项目和爬虫后,目录结构如下图:
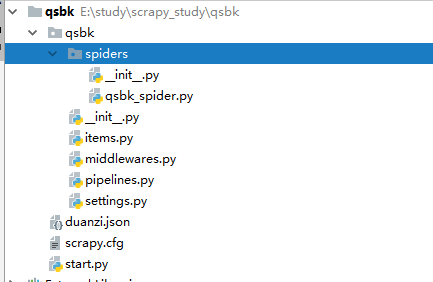
项目中主要文件的作用:
- items.py:用来存放爬虫爬取下来数据的模型。
- middlewares.py:用来存放各种中间件的文件。
- pipelines.py:用来将
items的模型存储到本地磁盘中。 - settings.py:本爬虫的一些配置信息(比如请求头、多久发送一次请求、ip代理池等)。
- scrapy.cfg:项目的配置文件。
- spiders包:以后所有的爬虫,都是存放到这个里面。
2.3 Scrapy命令行工具
#1 查看帮助 scrapy -h scrapy <command> -h #2 有两种命令:其中Project-only必须切到项目文件夹下才能执行,而Global的命令则不需要 Global commands: startproject #创建项目 genspider #创建爬虫程序 settings #如果是在项目目录下,则得到的是该项目的配置 runspider #运行一个独立的python文件,不必创建项目 shell #scrapy shell url地址 在交互式调试,如选择器规则正确与否 fetch #独立于程单纯地爬取一个页面,可以拿到请求头 view #下载完毕后直接弹出浏览器,以此可以分辨出哪些数据是ajax请求 version #scrapy version 查看scrapy的版本,scrapy version -v查看scrapy依赖库的版本 Project-only commands: crawl #运行爬虫,必须创建项目才行,确保配置文件中ROBOTSTXT_OBEY = False check #检测项目中有无语法错误 list #列出项目中所包含的爬虫名 edit #编辑器,一般不用 parse #scrapy parse url地址 --callback 回调函数 #以此可以验证我们的回调函数是否正确 bench #scrapy bentch压力测试 #3 官网链接 https://docs.scrapy.org/en/latest/topics/commands.html
2.4 使用Scrapy框架爬取糗事百科段子
2.4.1 使用命令创建一个爬虫
scrapy gensipder qsbk_spider "qiushibaike.com"
创建了一个名字叫做qsbk_spider的爬虫,并且能爬取的网页只会限制在qiushibaike.com这个域名下。
2.4.2 爬虫代码解析


# -*- coding: utf-8 -*- import scrapy class QsbkSpiderSpider(scrapy.Spider): name = 'qsbk_spider' allowed_domains = ['qiushibaike.com'] start_urls = ['http://qiushibaike.com/'] def parse(self, response): pass
其实这些代码我们完全可以自己手动去写,而不用命令。只不过是不用命令,自己写这些代码比较麻烦。
要创建一个Spider,那么必须自定义一个类,继承自scrapy.Spider,然后在这个类中定义三个属性和一个方法。
- name:这个爬虫的名字,名字必须是唯一的。
- allow_domains:允许的域名。爬虫只会爬取这个域名下的网页,其他不是这个域名下的网页会被自动忽略。
- start_urls:爬虫从这个变量中的url开始。
- parse:引擎会把下载器下载回来的数据扔给爬虫解析,爬虫再把数据传给这个
parse方法。这个是个固定的写法。这个方法的作用有两个,第一个是提取想要的数据。第二个是生成下一个请求的url。
2.4.3 修改settings.py代码
在做一个爬虫之前,一定要记得修改setttings.py中的设置。两个地方是强烈建议设置的。
ROBOTSTXT_OBEY设置为False。默认是True。即遵守机器协议,那么在爬虫的时候,scrapy首先去找robots.txt文件,如果没有找到。则直接停止爬取。DEFAULT_REQUEST_HEADERS添加User-Agent。这个也是告诉服务器,我这个请求是一个正常的请求,不是一个爬虫。
2.4.4 完成的爬虫代码
-
爬虫部分代码:
qsbk_spider.py# -*- coding: utf-8 -*- import scrapy from qsbk.items import QsbkItem class QsbkSpiderSpider(scrapy.Spider): name = 'qsbk_spider' allowed_domains = ['qiushibaike.com'] start_urls = ['https://www.qiushibaike.com/text/page/1/'] base_domain = "https://www.qiushibaike.com" def parse(self, response): duanzidivs = response.xpath('//div[@id="content-left"]/div') for duanzidiv in duanzidivs: author = duanzidiv.xpath('.//h2/text()').get().strip() content = duanzidiv.xpath('.//div[@class="content"]//text()').getall() content = ''.join(content).strip() item = QsbkItem(author=author,content=content) yield item next_url = response.xpath('//ul[@class="pagination"]/li[last()]/a/@href').get() if not next_url: return else: yield scrapy.Request(self.base_domain+next_url,callback= self.parse)
-
items.py部分代码:
import scrapy class QsbkItem(scrapy.Item): author = scrapy.Field() content = scrapy.Field()
-
pipeline部分代码:
pipelines.py-*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import json class QsbkPipeline(object): def __init__(self): self.fp = open('duanzi.json','w',encoding='utf-8') def open_spider(self,spider): pass def process_item(self, item, spider): item_json = json.dumps(dict(item),ensure_ascii=False) self.fp.write(item_json+' ') return item def close_spider(self,spider): self.fp.close()
2.4.5 运行scrapy项目
运行scrapy项目。需要在终端,进入项目所在的路径,然后scrapy crawl [爬虫名字]即可运行指定的爬虫。如果不想每次都在命令行中运行,那么可以把这个命令写在一个文件中。以后就在pycharm中执行运行这个文件就可以了。比如现在新创建一个文件叫做start.py,然后在这个文件中填入以下代码:
from scrapy import cmdline cmdline.execute(["scrapy","crawl","qsbk_spider"])
#cmdline.execute("scrapy crawl qsbk_spider".split())
2.4.6 糗事百科scrapy爬虫笔记
1.parse(self, response)中的response是一个'scrapy.http.response.html.HtmlResponse'对象。可以执行'xpath'和'css'语法来提取数据。
2.提出出来的数据是一个'Selector'或者'Selectorlist'对象,如果想要获取其中的字符串,可以通过getall()或者get()方法。
3.getall()方法获取‘Selector’中的所有文本,返回的是一个列表。get()方法获取的是‘Selector’中的第一个文本,返回的是一个str类型。
4.如果数据解析完成后,要传给pipline处理,可以使用'yield'来返回,或者是收取所有的item,组合成一个列表,最后统一使用return返回。
5.item:建议在'items.py'中定义好要传递的数据。
6.pipeline:这个是专门用来保存数据的,其中有三个方法经常会用到。
* "open_spider(self,spider)":当爬虫被打开时执行。
* "process_item(self,item,spider)":当爬虫有item传过来时被调用。
* "close_spider(self,spider)":当爬虫关闭的时候被调用。
要激活pipeline,需要在'settings.py中设置"ITEM_PIPELINES"。示例如下:
ITEM_PIPELINES = {
'qsbk.pipelines.QsbkPipeline': 300,
}
7.保存json数据的时候,可以使用JsonItemExporter和JsonLinesItemExporter类,优化数据存储方式
* JsonItemExporter:每次把数据添加到内存中,最后统一写入到磁盘。优点:存储的数据是一个满足json规则的数据。缺点:当数据量很大的时候比较耗内存。示例代码如下:
from scrapy.exporters import JsonItemExporter class QsbkPipeline(object): def __init__(self): self.fp = open('duanzi.json','wb') self.exporter = JsonItemExporter(self.fp,ensure_ascii = False,encoding = 'utf-8') self.exporter.start_exporting() def open_spider(self,spider): print('爬虫开始了...') def process_item(self, item, spider): self.exporter.export_item(item) return item def close_spider(self,spider): self.exporter.finish_exporting() self.fp.close() print('爬虫结束')
* JsonLinesItemExporter:这个是每次调用export_item的时候就把这个item存储到硬盘中,缺点:每个字典是一行,整个文件不是一个满足json格式的文件。优点:每次处理数据的时候就直接存储到硬盘中,这样不会耗内存,数据也比较安全。示例代码如下:
from scrapy.exporters import JsonLinesItemExporter class QsbkPipeline(object): def __init__(self): self.fp = open('duanzi.json','wb') self.exporter = JsonLinesItemExporter(self.fp,ensure_ascii = False,encoding = 'utf-8') def open_spider(self,spider): print('爬虫开始了...') def process_item(self, item, spider): self.exporter.export_item(item) return item def close_spider(self,spider): self.fp.close() print('爬虫结束')
3. CrawlSpider
在上一个糗事百科的爬虫案例中。我们是自己在解析完整个页面后获取下一页的url,然后重新发送一个请求。有时候我们想要这样做,只要满足某个条件的url,都给我进行爬取。那么这时候我们就可以通过CrawlSpider来帮我们完成了。CrawlSpider继承自Spider,只不过是在之前的基础之上增加了新的功能,可以定义爬取的url的规则,以后scrapy碰到满足条件的url都进行爬取,而不用手动的yield Request。
3.1 CrawlSpider爬虫
3.1.1创建CrawlSpider爬虫
之前创建爬虫的方式是通过scrapy genspider [爬虫名字] [域名]的方式创建的。如果想要创建CrawlSpider爬虫,那么应该通过以下命令创建:
scrapy genspider -t crawl [爬虫名字] [域名]
3.1.2 LinkExtractors链接提取器
使用LinkExtractors可以不用程序员自己提取想要的url,然后发送请求。这些工作都可以交给LinkExtractors,他会在所有爬的页面中找到满足规则的url,实现自动的爬取。以下对LinkExtractors类做一个简单的介绍:
class scrapy.linkextractors.LinkExtractor( allow = (), deny = (), allow_domains = (), deny_domains = (), deny_extensions = None, restrict_xpaths = (), tags = ('a','area'), attrs = ('href'), canonicalize = True, unique = True, process_value = None )
主要参数讲解:
- allow:允许的url。所有满足这个正则表达式的url都会被提取。
- deny:禁止的url。所有满足这个正则表达式的url都不会被提取。
- allow_domains:允许的域名。只有在这个里面指定的域名的url才会被提取。
- deny_domains:禁止的域名。所有在这个里面指定的域名的url都不会被提取。
- restrict_xpaths:严格的xpath。和allow共同过滤链接。
3.1.3 Rule规则类
定义爬虫的规则类。以下对这个类做一个简单的介绍:
class scrapy.spiders.Rule( link_extractor, callback = None, cb_kwargs = None, follow = None, process_links = None, process_request = None )
主要参数讲解:
- link_extractor:一个
LinkExtractor对象,用于定义爬取规则。 - callback:满足这个规则的url,应该要执行哪个回调函数。因为
CrawlSpider使用了parse作为回调函数,因此不要覆盖parse作为回调自己的回调函数。 - follow:指定根据该规则从response中提取的链接是否需要跟进。
- process_links:从link_extractor中获取到链接后会传递给这个函数,用来过滤不需要爬取的链接。
3.2 CrawlSpider 爬取微信小程序社区内容
爬虫部分代码:
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from wxapp.items import WxappItem class WxAppSpider(CrawlSpider): name = 'wx_app' allowed_domains = ['wxapp-union.com'] start_urls = ['http://www.wxapp-union.com/portal.php?mod=list&catid=2&page=1'] rules = ( Rule(LinkExtractor(allow=r'.+mod=list&catid=2&page=d'), follow=True), Rule(LinkExtractor(allow=r'.+article-.+.html'),callback="parse_detail",follow=False), ) def parse_detail(self, response): title = response.xpath('//h1[@class="ph"]/text()').get() author_p = response.xpath('//p[@class="authors"]') author = author_p.xpath('.//a/text()').get() pub_time = author_p.xpath('.//span/text()').get() content = response.xpath('//td[@id="article_content"]//text()').getall() content = ''.join(content).strip() item = WxappItem(title=title,author=author,pub_time=pub_time,content=content) #item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get() #item['name'] = response.xpath('//div[@id="name"]').get() #item['description'] = response.xpath('//div[@id="description"]').get() yield item
items.py部分代码:
import scrapy class WxappItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() author = scrapy.Field() pub_time = scrapy.Field() content = scrapy.Field()
pipeline部分代码:
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html from scrapy.exporters import JsonLinesItemExporter class WxappPipeline(object): def __init__(self): self.fp = open('wxjc.json','wb') self.exporter = JsonLinesItemExporter(self.fp,ensure_ascii = False,encoding = 'utf-8') def process_item(self, item, spider): self.exporter.export_item(item) return item def close_spider(self,spider): self.fp.close()
总结:
1. CrawlSpider使用"LinkExtractor"和Rule决定爬虫的具体走向。
2. LinkExtractor参数 allow设置规则:设置的url正则表达式要能够限制在我们想要的url上
3. Rule参数follow的设置:如果在爬取页面的时候,需要将满足当前条件的url再进行跟进,那么设置为Ture,否则设置为False。
4.什么时候指定callback:如果这个url对应的页面,只是为了获取更多的url,并不需要里面的数据,那么可以不指定callback,如果想要获取url对应页面中的数据,那么就需要指定一个callback。
4. Scrapy 之Request对象和Response对象
4.1 Request对象
class Request(object_ref): def __init__(self, url, callback=None, method='GET', headers=None, body=None, cookies=None, meta=None, encoding='utf-8', priority=0, dont_filter=False, errback=None, flags=None): self._encoding = encoding # this one has to be set first self.method = str(method).upper() self._set_url(url) self._set_body(body) assert isinstance(priority, int), "Request priority not an integer: %r" % priority self.priority = priority if callback is not None and not callable(callback): raise TypeError('callback must be a callable, got %s' % type(callback).__name__) if errback is not None and not callable(errback): raise TypeError('errback must be a callable, got %s' % type(errback).__name__) assert callback or not errback, "Cannot use errback without a callback" self.callback = callback self.errback = errback self.cookies = cookies or {} self.headers = Headers(headers or {}, encoding=encoding) self.dont_filter = dont_filter self._meta = dict(meta) if meta else None self.flags = [] if flags is None else list(flags)
Request对象在我们写爬虫爬取一页数据后需要重新发送一个请求的时候调用,这个类需要传递一些参数,其中比较常用的参数有:
1. url:这个是request对象发送请求的url
2. callback:在下载器下载完成相应的数据后执行回调函数
3. method:请求的方法,默认为GET方法,可以设置为其他方法
4. headers:请求头,对于一些固定的设置,放在settings.py中指定就可以,对于非固定的请求头,可以在发送请求的时候指定。
5. cookies (dict or list) :请求的cookies。可以被设置成如下两种形式。
- )Using a dict:
request_with_cookies = Request(url="http://www.example.com", cookies={'currency': 'USD', 'country': 'UY'}) - )Using a list of dicts:
request_with_cookies = Request(url="http://www.example.com", cookies=[{'name': 'currency', 'value': 'USD', 'domain': 'example.com', 'path': '/currency'}])
- )Using a dict:
6. meta:比较常用,用于在不同的请求之间传递数据
7. encoding:编码,默认为utf-8
8. dot_filter:表示不由调度器过滤,在执行多次重复的请求的时候用的较多,设置为True,可避免重复发送相同的请求
9. errback:在发送错误的时候执行的函数
发送Post请求:
有时候我们想要在请求数据的时候发送post请求,那么这时候需要使用Request的子类FormRequest来实现。如果想要在爬虫一开始的时候就发送Post请求,那么需要在爬虫类中重写start_requests(self)方法,并且不再调用start_urls里的url.
4.2 Response对象
Response对象一般由Scrapy自动构建,因此开发者不需要关心如何创建Response对象。Response对象有很多属性,常用属性如下:
1. meta:从其他请求传过来的meta属性,可以用来保持多个请求之间的数据连接
2. encoding:返回当前字符串编码和解码格式
3. text:将返回的数据作为unicode字符串返回
4. body:将返回的数据作为bytes字符串返回
5. xpath:xpath选择器
6. css:css选择器
4.3 使用Request对象模式登录
4.3.1 模拟登录人人网
爬虫部分代码:
# -*- coding: utf-8 -*- import scrapy class RenrenSpider(scrapy.Spider): name = 'renren' allowed_domains = ['renren.com'] start_urls = ['http://www.renren.com/'] def start_requests(self): # 在爬虫一开始发送Post请求,需要重写start_requests(self)方法 #发送post请求,推荐使用scrapy.FormRequest方法,可以指定表单数据 url = 'http://www.renren.com/PLogin.do' data = {'email':'970138074@qq.com','password':'pythonspider'} request = scrapy.FormRequest(url,formdata=data,callback=self.parse_page) yield request def parse_page(self,response): request = scrapy.Request(url = 'http://www.renren.com/443362311/profile', callback=self.parse_profile) yield request def parse_profile(self,response): with open('dp.html','w',encoding='utf-8') as fp: fp.write(response.text)
5. 下载文件和图片
5.1 实战-汽车之家宝马5系图片下载爬虫
1) 通过自己写图片下载程序下载汽车之家宝马5系图片,示例如下:
爬虫部分代码:
# -*- coding: utf-8 -*- import scrapy from BM5X.items import Bm5XItem class Bm5xSpider(scrapy.Spider): name = 'bm5x' allowed_domains = ['https://car.autohome.com.cn/'] start_urls = ['https://car.autohome.com.cn/pic/series/65.html'] def parse(self, response): uniboxs = response.xpath("//div[@class='uibox']")[1:] for unibox in uniboxs: category = unibox.xpath(".//div[@class='uibox-title']/a/text()").get() urls = unibox.xpath(".//ul/li/a/img/@src").getall() urls = list(map(lambda url:response.urljoin(url),urls)) item = Bm5XItem(category=category,urls=urls) yield item
items.py部分代码:
import scrapy class Bm5XItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() category = scrapy.Field() urls = scrapy.Field()
pipeline部分代码:
import os from urllib import request class Bm5XPipeline(object): def __init__(self): BATH = os.path.dirname(os.path.dirname(__file__)) self.path = os.path.join(BATH,'images') if not os.path.exists(self.path): os.makedirs(self.path) def process_item(self, item, spider): category = item['category'] urls = item['urls'] category_path = os.path.join(self.path,category) if not os.path.exists(category_path): os.makedirs(category_path) for url in urls: image_name = url.split('_')[-1] request.urlretrieve(url,os.path.join(category_path,image_name)) return item
2) 使用scrapy 内置下载文件方法下载汽车之家宝马5系图片,示例如下:
Scrapy为下载item中包含的文件(比如在爬取到产品时,同时也想保存对应的图片)提供了一个可重用的item pipelines。这些pipelines有些共同的方法和结构(我们称之为media pipeline)。一般来说你会使用Files pipline 或者Images pipline。
为什么要选择使用scrapy内置的下载文件的方法:
1) 避免重新下载最近已经下载过的数据
2) 可以方便的指定文件存储的路径
3) 可以将下载的图片转换为通用的格式,比如png或jpg
4) 可以方便的生成缩略图
5) 可以方便的检测图片的宽和高,确保他们满足最小的限制
6) 异步下载,效率非常高
下载文件的Files Pipeline:
当使用Files Pipline 下载文件的时候,按照以下步骤来完成:
1) 定义好一个Item,然后在这个item中定义两个属性,分别为file_urls以及files。file_urls是用来存储需要下载的文件的url链接,需要给一个列表。
2) 当文件下载完成后,会把文件下载的相关信息存储到item的files属性中,比如下载路径和文件校验码等。
3) 在配置文件setting.py中配置FILES_STORE,这个配置是用来设置文件下载下来的路径。
4) 启动pipline,在ITEM_PIPELINES中设置
ITEM_PIPELINES = {
# 'BM5X.pipelines.Bm5XPipeline': 300,
'scrapy.pipelines.files.FilesPipeline':1
}
下载图片的Images Pipeline:
当使用Images Pipline下载文件的时候,按照以下步骤来完成:
1) 定义好一个Item,然后在这个item中定义两个属性,分别为image_urls以及images。image_urls是用来存储需要下载的图片的url链接,需要给一个列表。
2) 当文件下载完成后,会把文件下载的相关信息存储到item的images属性中,如下下载路径,下载的url和图片的校验码等。
3) 在配置文件settings.py中配置IMAGES_STORE,这个配置是用来设置图片下载下来的路径。
4) 启动pipline ,在ITEM_PIPELINES中设置
ITEM_PIPELINES = {
# 'BM5X.pipelines.Bm5XPipeline': 300,
'scrapy.pipelines.images.ImagesPipeline':1
}
爬虫部分代码:
# -*- coding: utf-8 -*- import scrapy from BM5X.items import Bm5XItem class Bm5xSpider(scrapy.Spider): name = 'bm5x' allowed_domains = ['https://car.autohome.com.cn/'] start_urls = ['https://car.autohome.com.cn/pic/series/65.html'] def parse(self, response): uniboxs = response.xpath("//div[@class='uibox']")[1:] for unibox in uniboxs: category = unibox.xpath(".//div[@class='uibox-title']/a/text()").get() urls = unibox.xpath(".//ul/li/a/img/@src").getall() urls = list(map(lambda url:response.urljoin(url),urls)) item = Bm5XItem(category=category,image_urls=urls) yield item
items.py部分代码:
import scrapy class Bm5XItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() category = scrapy.Field() image_urls = scrapy.Field() images = scrapy.Field()
pipeline部分代码:
import os from scrapy.pipelines.images import ImagesPipeline from BM5X import settings class BM5XImagesPipeline(ImagesPipeline): def get_media_requests(self, item, info): #这个方法是在发送下载请求之前调用 #其实这个方法本身就是去发送下载请求的 request_objs = super(BM5XImagesPipeline,self).get_media_requests(item,info) for request_obj in request_objs: request_obj.item = item return request_objs def file_path(self, request, response=None, info=None): #这个方法是在图片将要被保存的时候调用,来获取这个图片存储的路径 path = super(BM5XImagesPipeline,self).file_path(request,response,info) category = request.item.get('category') images_store = settings.IMAGES_STORE category_path = os.path.join(images_store,category) if not os.path.exists(category_path): os.makedirs(category_path) image_name = path.replace('full/','') image_path = os.path.join(category_path,image_name) return image_path
setting部分代码:
# -*- coding: utf-8 -*- # Scrapy settings for BM5X project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html import os BOT_NAME = 'BM5X' SPIDER_MODULES = ['BM5X.spiders'] NEWSPIDER_MODULE = 'BM5X.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'BM5X (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36', } # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'BM5X.middlewares.Bm5XSpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # 'BM5X.middlewares.Bm5XDownloaderMiddleware': 543, #} # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { # 'BM5X.pipelines.Bm5XPipeline': 300, 'BM5X.pipelines.BM5XImagesPipeline':1 } # Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' #图片下载路径,供images pipline使用 IMAGES_STORE = os.path.join(os.path.dirname(os.path.dirname(__file__)),'images')
6. 下载器中间件(DownLoader Middlewares)
下载器中间件是引擎和下载器之间通信的中间件。在这个中间件中我们可以设置代理、更换请求头等来达到反反爬虫的目的。要写下载器中间件,可以在下载器中实现两个方法,一个是process_request(self,request,spider),这个方法是在请求发送之前执行,还有一个是process_response(self,request,response,spider),这个方法是数据下载到引擎之前执行。
process_request(self,request,spider):
这个方法是下载器在发送请求之前执行,一般可以在这个里面设置随机代理ip等。
1)参数:
request: 发送请求的request对象。
spider: 发送请求的spider对象。
2)返回值:
返回None:如果返回None,Scrapy将继续处理该request,执行其他中间件中的相应方法,直到合适的下载器处理函数被调用
返回Response对象:Scrapy 将不会调用任何其他的process_request方法,将直接返回这个response对象。已经激活的中间件process_response()方法则会在每个response返回时被调用
返回Request对象:不再使用之前的request对象去下载数据,而是根据现在返回的request对象返回数据。
如果这个方法中出现了异常,则会调用process_exception方法
process_response(self,request,response,spider):
这个是下载器下载数据到引擎过程中执行的方法
1)参数:
request:request 对象
response:被处理的response对象
spider:spider对象
2)返回值:
返回Response对象:会将这个新的response对象传给其他中间件,最终传给爬虫
返回Request对象:下载器链被切断,返回的request会重新被下载器调度下载
如果抛出一个异常,那么调用request的errback方法,如果没有指定这个方法,那么会抛出一个异常
>>>>>>待续