文章来源:http://blog.seclibs.com/数据结构之数组/
在说数组之前咱们先明确两个概念,什么是线性表,什么是非线性表
顾名思义,线性表就是把数据排成一条,每个数据只有前后两种情况,常见的线性表有数组、链表、队列、栈等
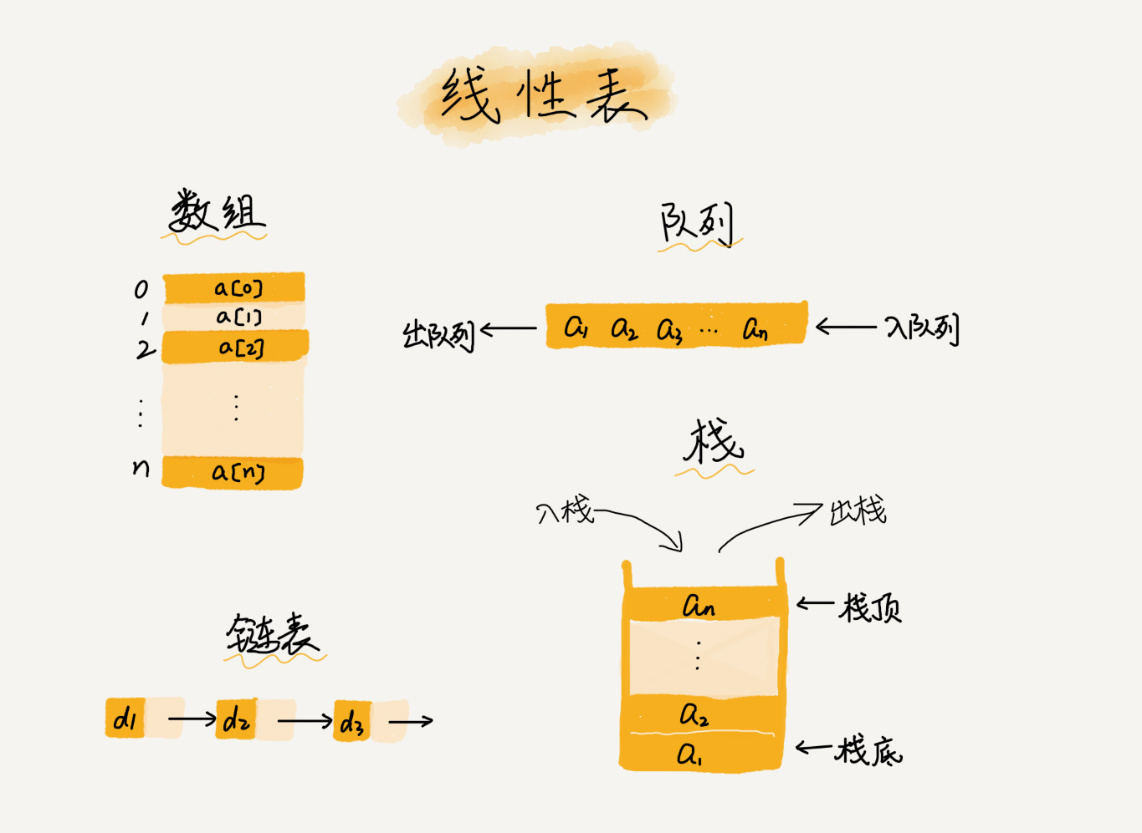
那非线性表就更好理解了,数据不是按照一条线来排列的,每个数据并不只有前后两个方向,常见的有二叉树、堆、图等

明白了这个概念之后,咱们再来说数组,什么是数组?
数组不仅是大多数编程语言中的一个数据类型,它更是一个最基础的数据结构。
数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
关于线性表前面已经说过了,接下来说具有连续的内存空间、存储相同类型的数据,也正是因为这一点才使数组有了随机访问的特性。
我们拿下面这个例子来进行说明,有一个长度为10的int类型的数组,我们给它分配一块连续内存空间 1000~1039,内存块的首地址为1000
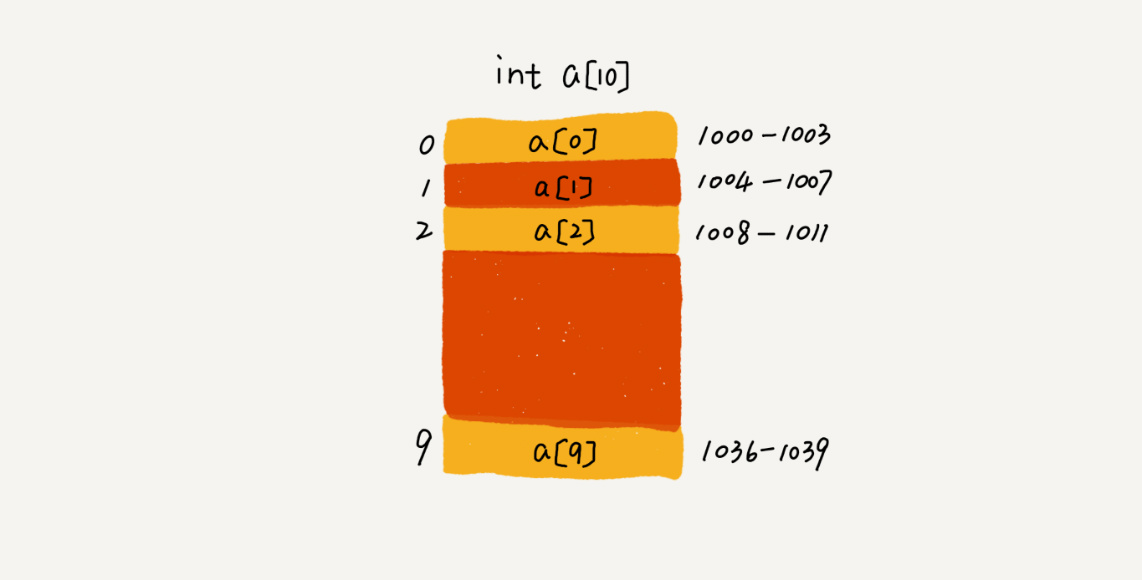
当我们需要访问其中的数据的时候,计算机会先通过一个寻址公式来找到内存地址,然后再读取其中的数据。
在数组中我们使用的寻址公式为
a[i]_address = base_address + i * data_type_size
base_address为内存块的首地址1000,data_type_size为数据类型的大小,这里我们使用的是int类型,所以data_type_size为4个字节,也正是这个原因,在很多语言中,都将数组的第一个下标定为0,因为在寻址的时候,可以直接得到内存地址,而不需要再将数值减一后再进行计算,虽然我们口算很简单,但是在CPU中,它所进行的运算还是相当多的。
当我们需要得到数组中第一个元素的内容时,便直接套公式1000+0*4=1000,便直接得到了内存地址。
所以数组适合查询,支持随机访问,在根据下标进行随机访问时时间复杂度为O(1),这里需要注意一下,说数组的时间复杂度的时候一定要说明在跟进下标进行随机访问的时候,因为如果使用二分查找的话,即便已经进行过排序的数组,时间复杂度也是O(logn)。
但是数组的随机访问的特性有利有弊,因为数组要保证空间是连续的,所以在增加和删除的时候,就需要进行大量的操作将数据进行移动,将是非常低效的。
我们先来说插入操作,假如数组的长度为x,那么如果要在第y个位置插入一个数据,那么就需要将y到x的所有数据都往后挪一位,将第y个位置腾出来。
我们来看一下它所涉及到的时间复杂度,如果插入的数据在最后一个,就不需要进行移动,最好时间复杂度为O(1);如果插入的数据在第一个,则后面的每一个数据都需要往后挪一个,最坏时间复杂度为O(n);因为在每一个位置插入的概率都是一样的,所以平均时间复杂度为(1+2+…+n)/n=O(n)。
当然这是对数组数据是有序的情况下来说的,如果数据是无序的话,就不需要这些操作了,如果要在第y位插入数据,只需要将第y位的数据移动到整个数组的最后面,然后再将需要插入的数据插入即可,这个时候的时间复杂度就降为了O(1)。
接下来说删除操作,与插入数据类似,如果要删除第y位的数据,就需要将y到n的数据都往前挪一个,否则内存空间就不连续了,如果删除数组末尾的数据,最好时间复杂度为 O(1);如果删除开头的数据,最坏时间复杂度为 O(n),删除每一个数据的概率是相同的,平均时间复杂度为 O(n)。
数组到这里也就结束了,再接着就是代码实现。
参考文档
极客时间-数据结构和算法之美
文章首发公众号和个人博客:
公众号:无心的梦呓(wuxinmengyi)
这是一个记录红队学习、信安笔记,个人成长的公众号
扫码关注即可

记录红队相关学习笔记