一.分区表
在下面的场景中,分区可以起到非常大的作用:

分区表本身也有一些限制,下面是其中比较重要的几点:

1.分区表的原理
分区表由多个相关的底层表实现,这些底层表也是由句柄对象(Handlerobject)表示,所以我们也可以直接访问各个分区。存储引擎管理分区的各个底层表和管理普通表一样(所有的底层表都必须使用相同的存储引擎),分区表的索引只是在各个底层表上各自加上一个完全相同的索引。从存储引擎的角度来看,底层表和一个普通表没有任何不同,存储引擎也无须知道这是一个普通表还是一个分区表的一部分。
分区表上的操作按照下面的操作逻辑进行:
SELECT查询
当查询一个分区表的时候,分区层先打开并锁住所有的底层表,优化器先判断是否可以过滤部分分区,然后再调用对应的存储引擎接口访问各个分区的数据。
INSERT操作
当写入一条记录时,分区层先打开并锁住所有的底层表,然后确定哪个分区接收这条记录,再将记录写入对应底层表。
DELETE操作
当删除一条记录时,分区层先打开并锁住所有的底层衣,然石佣疋效掂对应P刀一'最后对相应底层表进行删除操作。
UPDATE操作
当更新一条记录时,分区层先打开并锁住所有的底层表,MySQL先确定需要更新的记录在哪个分区,然后取出数据并更新,再判断更新后的数据应该放在哪个分区,最后对底层表进行写入操作,并对原数据所在的底层表进行删除操作。
2.分区表的类型
MySQL支持多种分区表。我们看到最多的是根据范围进行分区,每个分区存储落在某个范围的记录,分区表达式可以是列,也可以是包含列的表达式。例如,下表就可以将每一年的销售额存放在不同的分区里:

3.如何使用分区表
为了保证大数据量的可扩展性,一般有下面两个策略:
全量扫描数据,不要任何索引。
可以使用简单的分区方式存放表,不要任何索引,根据分区的规则大致定位需要的数据位置。只要能够使用WHERE条件,将需要的数据限制在少数分区中,则效率是很高的。当然,也需要做一些简单的运算保证查询的响应时间能够满足需求。使用该策略假设不用将数据完全放入到内存中,同时还假设需要的数据全都在磁盘上,因为内存相对很小,数据很快会被挤出内存,所以缓存起不了任何作用。这个策略适用于以正常的方式访问大量数据的时候。警告:后面我们会详细解释,必须将查询需要扫描的分区个数限制在一个很小的数量。
索引数据,并分离热点。
如果数据有明显的“热点”,而且除了这部分数据,其他数据很少被访问到,那么可以将这部分热点数据单独放在一个分区中,让这个分区的数据能够有机会都缓存在内存中。这样查询就可以只访问一个很小的分区表,能够使用索引,也能够有效地使用缓存。
4.什么情况下会出问题
NULL值会使分区过滤无效
分区列和索引列不匹配
选择分区的成本可能很高
打开并锁住所有底层表的成本可能很高
维护分区的成本可能很高
5.查询优化
引入分区给查询优化带来了一些新的思路(同时也带来新的bug)。分区最大的优点就是优化器可以根据分区函数来过滤一些分区。根据粗粒度索引的优势,通过分区过滤通常可以让查询扫描更少的数据(在某些场景下)。所以,对于访问分区表来说,很重要的一点是要在WHERE条件中带入分区列,有时候即使看似多余的也要带上,这样就可以让优化器能够过滤掉无须访问的分区。如果没有这些条件,MySQL就需要让对应存储引擎访问这个表的所有分区,如果表非常大的话,就可能会非常慢。
6.合并表
二.视图
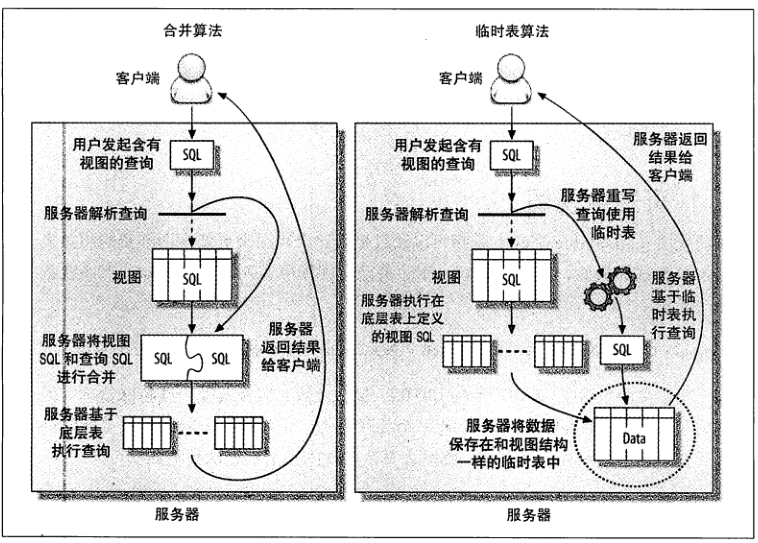
1.可更新视图
可更新视图(updatable view)是指可以通过更新这个视图来更新视图涉及的相关表。只要指定了合适的条件,就可以更新、删除甚至向视图中写入数据。
2.视图对性能的影响
3.视图的限制
三.外键约束
四.在MySQL内部存储代码
MySQL允许通过触发器、存储过程、函数的形式来存储代码。从MySQL 5.1开始,还可以在定时任务中存放代码,这个定时任务也被称为“事件”。存储过程和存储函数都被统称为“存储程序”。
五.游标