数据结构
调度相关的数据结构有三个,M(线程),P(调度器),G(goroutine)
M表示线程,P作为调度器用来帮助每个线程管理自己的goroutine,G就是golang的协程。我们可以通过runtime.GOMAXPROCS(n int)函数设置P的个数,注意P的个数并不代表M的个数,例如程序启动时runtime代码会出实话procs个P,但开始的时候只会启动一个M,就是M0和一个栈为64K(其他goroutine默认初始栈大小2K)来执行runtime代码。
那其他线程是什么时候创建的呐?
当goroutine被唤醒时,要在M上运行(恢复goroutine的上下文),P是帮助M管理goroutine的,恢复上下文的操作也由P来完成。如果被唤醒时发现还有空闲的P,并且没有其他M在窃取goroutine(M发现本地goroutine队列和全局goroutine队列都没有goroutine的时候,会去其他线程窃取goroutine),说明其他M都在忙,就会创建一个M让这个空闲的P帮他来管理goroutine。
总之一句话,开始的时候创建一个M,当发现调度不过来且还有空闲P没有工作就在创建新的,直到创建procs个M(procs通过runtime.GOMAXPROCS设置)

G
golang 用结构体g表示goroutine
g
type g struct {
stack stack // 当前栈的范围[stack.lo, stack.hi)
stackguard0 uintptr // 用于抢占的,一般情况值为stack.lo + StackGuard
stackguard1 uintptr // 用于C语言的抢占
_panic *_panic // 最内侧的panic函数
_defer *_defer // 最外侧的defer函数
m *m // 当前goroutine属于哪个m
sched gobuf // 调度相关信息
...
schedlink guintptr // sched是全局的goroutine链表,schedlink表示这个goroutine在链表中的下一个goroutine的指针
...
preempt bool // 抢占标志,如果需要抢占就将preempt设置为true
...
}
gobuf
gobuf保存goroutine的调度信息,当一个goroutine被调度的时,本质上就是把这个goroutine放到cpu,恢复各个寄存器的值,然后运行
type gobuf struct {
sp uintptr // 栈指针
pc uintptr // 程序计数器
g guintptr // 当前被哪个goroutine持有
ctxt unsafe.Pointer
ret sys.Uintreg // 系统调用返回值,防止系统调用后被其他goroutine抢占,所以有个地方保存返回值
lr uintptr
bp uintptr // 保存CPU的rip寄存器的值
}
M
golang中M表示实际操作系统的线程
m
type m struct {
g0 *g // g0帮M处理大小事务的goroutine,他是m中的第一个goroutine
...
gsignal *g // 用于信号处理的goroutine
tls [6]uintptr // 线程私有空间
mstartfn func()
curg *g // current running goroutine
...
p puintptr // 当前正在运行的p(处理器)
nextp puintptr // 暂存的p
oldp puintptr // 执行系统调用之前的p
...
spinning bool // 表示当前m没有goroutine了,正在从其他m偷取goroutine
blocked bool // m is blocked on a note
...
park note // m没有goroutine的时候会在park上sleep,需要其他m在park中wake up这个m
alllink *m // on allm // 所有m的链表
...
thread uintptr // thread handle
...
}
P
golang中P表示一个调度器,为M提供上下文环境,使得M可以执行多个goroutine
p
type p struct {
m muintptr // 与哪个M关联(可能为空的)
...
runqhead uint32 // p本地goroutine队列的头
runqtail uint32 // p本地goroutine队列的尾
runq [256]guintptr // 队列指针,和sync.pool中数据结构一样也是循环队列
...
sudogcache []*sudog // sudog缓存,channel用的
sudogbuf [128]*sudog // 也是防止false sharing
...
pad cpu.CacheLinePad // 防止false sharing
}
schedt
schedt结构体用来保存P的状态信息和goroutine的全局运行队列
type schedt struct {
...
lock mutex // 全局锁
// 维护空闲的M
midle muintptr // 等待中的M链表
nmidle int32 // 等待中的M的数量
nmidlelocked int32 // number of locked m's waiting for work
mnext int64 // number of m's that have been created and next M ID
maxmcount int32 // 最多创建多少个M(10000)
nmsys int32 // number of system m's not counted for deadlock
nmfreed int64 // cumulative number of freed m's
ngsys uint32 // number of system goroutines; updated atomically
// 维护空闲的P
pidle puintptr // idle p's
npidle uint32
nmspinning uint32 // See "Worker thread parking/unparking" comment in proc.go.
// goroutine的全局队列
runq gQueue
runqsize int32
...
// 全局缓存已经退出的goroutine链表,下次再创建的时候直接用
// Global cache of dead G's.
gFree struct {
lock mutex
stack gList // Gs with stacks
noStack gList // Gs without stacks
n int32
}
...
}
重要的全局变量
allgs []*g // 保存所有的g
allm *m // 所有的m构成的一个链表,包括下面的m0
allp []*p // 保存所有的p,len(allp) == gomaxprocs
ncpu int32 // 系统中cpu核的数量,程序启动时由runtime代码初始化
gomaxprocs int32 // p的最大值,默认等于ncpu,但可以通过GOMAXPROCS修改
sched schedt // 调度器结构体对象,记录了调度器的工作状态
m0 m // 代表进程的主线程
g0 g // m0的g0,也就是m0.g0 = &g0
分步骤剖析调度的初始化
下面是用go实现的hello world,代码里并没有关于调度的初始化,所以程序的入口并非是main.main,下面通过gdb一步步找到go是如何初始化调度的。
// test.go
package main
func main() {
println("hello, world!")
}
编译
go build -gcflags "-N -l" test.go
使用OS X的同学注意,go1.11之后压缩的debug信息,OS X的同学需要同时做以下设置参考Debug Go Program With Gdb On Macos
export GOFLAGS="-ldflags=-compressdwarf=false"
调试
- 利用断点可以找出目标文件的信息,在入口处打一个断点,找到程序入口在rt0_darwin_amd64.s的第8行
➜ sudo gdb test
(gdb) info files
Symbols from "/Users/journey/workspace/src/tool/gdb/test".
Local exec file:
`/Users/journey/workspace/src/tool/gdb/test', file type mach-o-x86-64.
Entry point: 0x104cd00
0x0000000001001000 - 0x00000000010515b1 is .text
0x00000000010515c0 - 0x000000000108162a is __TEXT.__rodata
0x0000000001081640 - 0x0000000001081706 is __TEXT.__symbol_stub1
0x0000000001081720 - 0x0000000001081e80 is __TEXT.__typelink
0x0000000001081e80 - 0x0000000001081e88 is __TEXT.__itablink
0x0000000001081e88 - 0x0000000001081e88 is __TEXT.__gosymtab
0x0000000001081ea0 - 0x00000000010bfacd is __TEXT.__gopclntab
0x00000000010c0000 - 0x00000000010c0020 is __DATA.__go_buildinfo
0x00000000010c0020 - 0x00000000010c0128 is __DATA.__nl_symbol_ptr
0x00000000010c0140 - 0x00000000010c0d08 is __DATA.__noptrdata
0x00000000010c0d20 - 0x00000000010c27f0 is .data
0x00000000010c2800 - 0x00000000010ddc90 is .bss
0x00000000010ddca0 - 0x00000000010e01e8 is __DATA.__noptrbss
(gdb) b *0x104cd00
Breakpoint 1 at 0x104cd00: file /usr/local/go/src/runtime/rt0_darwin_amd64.s, line 8.
- 进入上面找到的文件rt0_darwin_amd64.s(不同的架构文件是不同的)
➜ runtime ls rt0_*
rt0_aix_ppc64.s rt0_darwin_amd64.s rt0_freebsd_arm.s rt0_linux_arm64.s rt0_nacl_386.s rt0_netbsd_arm64.s rt0_plan9_amd64.s
rt0_android_386.s rt0_darwin_arm.s rt0_illumos_amd64.s rt0_linux_mips64x.s rt0_nacl_amd64p32.s rt0_openbsd_386.s rt0_plan9_arm.s
rt0_android_amd64.s rt0_darwin_arm64.s rt0_js_wasm.s rt0_linux_mipsx.s rt0_nacl_arm.s rt0_openbsd_amd64.s rt0_solaris_amd64.s
rt0_android_arm.s rt0_dragonfly_amd64.s rt0_linux_386.s rt0_linux_ppc64.s rt0_netbsd_386.s rt0_openbsd_arm.s rt0_windows_386.s
rt0_android_arm64.s rt0_freebsd_386.s rt0_linux_amd64.s rt0_linux_ppc64le.s rt0_netbsd_amd64.s rt0_openbsd_arm64.s rt0_windows_amd64.s
rt0_darwin_386.s rt0_freebsd_amd64.s rt0_linux_arm.s rt0_linux_s390x.s rt0_netbsd_arm.s rt0_plan9_386.s rt0_windows_arm.s
- 打开文件go/src/runtime/rt0_darwin_amd64.s:8
这里没有做什么就调了函数_rt0_amd64
TEXT _rt0_amd64_darwin(SB),NOSPLIT,$-8 // 参数+返回值共8字节
JMP _rt0_amd64(SB)
- 然后在打断点看看_rt0_amd64在哪
在ams_amd64.s第15行
(gdb) b _rt0_amd64
Breakpoint 2 at 0x1049350: file /usr/local/go/src/runtime/asm_amd64.s, line 15.
这里首先把参数放到DI,SI寄存器中,然后调用runtime.rt0_go,这就是进程初始化主要函数了
参数0放在DI通用寄存器
参数1放在SI通用寄存器
参数2放在DX通用寄存器
参数3放在CX通用寄存器
TEXT _rt0_amd64(SB),NOSPLIT,$-8 // 参数+返回值共8字节
MOVQ 0(SP), DI // argc
LEAQ 8(SP), SI // argv
JMP runtime·rt0_go(SB)
- 然后跳转到runtime.rt0_go
(gdb) b runtime.rt0_go
Breakpoint 3 at 0x1049360: file /usr/local/go/src/runtime/asm_amd64.s, line 89.
初始化
这个函数有点长,下面我们分段来看rt0_go这个函数
初始化参数以及创建g0
-
首先将之前放入通用寄存器的参数放入AX,BX寄存器,然后调整栈顶指针(真SP寄存器)的位置,SP指针先减39,关于16字节向下对齐(因为CPU有一组 SSE 指令,这些指令中出现的内存地址必须是16的倍数),然后把参数放到SP+16字节和SP+24字节处
golang的汇编有抽象出来的寄存器,通过是否有前缀变量区分真假寄存器,例如a+8(SP)就是golang的寄存器,8(SP)就是真的寄存器 -
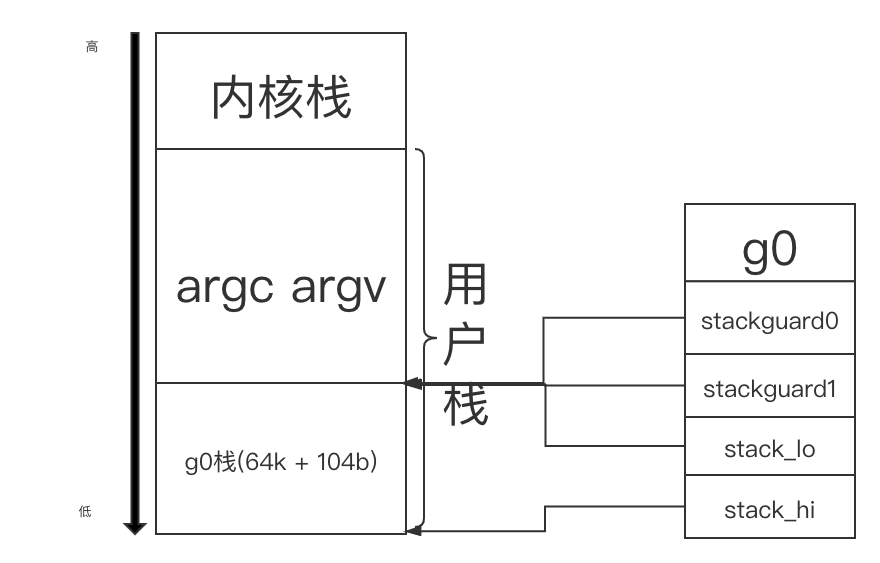
创建g0,并初始化g.stackgruard0,g.stackguard1以及g.stack.lo,g.stack.hi的值(实际上是分配一段内存,然后分割成小段,约定哪小段表示哪个变量)
TEXT runtime·rt0_go(SB),NOSPLIT,$0
MOVQ DI, AX // argc
MOVQ SI, BX // argv
SUBQ $(4*8+7), SP // 2args 2auto
ANDQ $~15, SP
MOVQ AX, 16(SP)
MOVQ BX, 24(SP)
// 初始化g0,g0就是go的第一个协程
// 给g0分配栈空间大概64K
//
MOVQ $runtime·g0(SB), DI
LEAQ (-64*1024+104)(SP), BX // BX = SP - 64 * 1024 + 104
MOVQ BX, g_stackguard0(DI) // g0.g_stackguard0 = SP - 64 * 1024 + 104
MOVQ BX, g_stackguard1(DI) // g0.g_stackguard1 = SP - 64 * 1024 + 104
MOVQ BX, (g_stack+stack_lo)(DI) // g0.stack.lo = SP - 64 * 1024 + 104
MOVQ SP, (g_stack+stack_hi)(DI) // g0.stack.hi = SP
创建完g0的内存分布
然后略过一段CPU型号检测和CGO初始化的代码
...
创建m0
- 创建将m0.tls放入DI寄存器,然后调用runtime.settls将m0设置为线程私有变量(mac下什么也没干),将m0与主线程绑定,然后对m0.tls进行存取操作验证是否能用,不能用就直接退出
- 绑定m0和g0的关系,m0.g0 = g0,g0.m = m0
// 将m0与主线程绑定
LEAQ runtime·m0+m_tls(SB), DI // 将m0的thread local store成员的地址到DI
CALL runtime·settls(SB) // 调用settls设置线程本地存储(mac 下settls什么都没做,线程已经设置好本地存储了)
// 通过往TLS存0x123在判断tls[0]是不是0x123验证TLS是否可用,如果不可用就abort
get_tls(BX)
MOVQ $0x123, g(BX)
MOVQ runtime·m0+m_tls(SB), AX
CMPQ AX, $0x123
JEQ 2(PC)
CALL runtime·abort(SB)
ok:
// 把g0存入m0的本地存储tls[0]
get_tls(BX) // 将m0.tls[0]地址放入BX
LEAQ runtime·g0(SB), CX // 将g0地址放入CX
MOVQ CX, g(BX) // m0.tls[0] = &g0
LEAQ runtime·m0(SB), AX // 将m0地址放入AX
// 将m0和g0建立映射关系
// save m->g0 = g0
MOVQ CX, m_g0(AX) // m0.g0 = g0
// save m0 to g0->m
MOVQ AX, g_m(CX) // g0.m = m0
CLD // convention is D is always left cleared
CALL runtime·check(SB)
创建完m0之后的内存分布

m0和g0的关系
- m0表示主线程,g0表示主线程的第一个goroutine
- g0主要是记录主线程的栈信息,执行调度函数(schedule后边会讲)时会用,而用户goroutine有自己的栈,执行的时候会从g0栈切换到用户goroutine栈
初始化调度
g0和m0都创建并初始化好了,下面就该进行调度初始化了
- 将参数放入AX(初始化g0时将参数放入SP+16和SP+24的位置
- runtime.args初始化参数的
- runtime.osinit是初始化CPU核数的
- 重点看runtime.schedinit
// 初始化m0
// 将argc和argv入栈
MOVL 16(SP), AX // copy argc
MOVL AX, 0(SP)
MOVQ 24(SP), AX // copy argv
MOVQ AX, 8(SP)
// 处理参数
CALL runtime·args(SB)
// 获取cpu的核数
CALL runtime·osinit(SB)
// 调度系统初始化
CALL runtime·schedinit(SB)
runtime.schedinit
下面函数省略了调度无关的代码,大概流程:
- 设置最大线程数
- 根据GOMAXPROCS设置procs(P的数量)
- 调用procresizeprocs调整P的数量
func schedinit() {
// 取出g0
_g_ := getg()
if raceenabled {
_g_.racectx, raceprocctx0 = raceinit()
}
// 设置最大线程数
sched.maxmcount = 10000
...
// 初始化m0, 前边已经将m0和g0的关系绑定好了
// 只是检查一下各种变量,然后将m0挂到allm链表中
mcommoninit(_g_.m)
...
sched.lastpoll = uint64(nanotime())
// ncpu在osinit时已经获取
procs := ncpu
// 如果GOMAXPROCS设置并且合法就将procs的设置为GOMAXPROCS
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
...
}
runtime.procresize
- 调度初始化最后一步
- 更新最后一次修改P数量动作的时间戳并累加花费时间
- 根据nprocs调整P的数量(加锁)
- nprocs > 现有P数量,就扩展allp(p的全局数组)的长度为nprocs
- nprocs < 现有P数量,就缩容allp的长度为nprocs
- 如果上一步是扩容了,就从堆中创建新P,并把P放入扩容出来的位置
- 通过g0找到m0,然后将allp[0]和m0绑定
- 如果allp缩容了,就将多余的p销毁
- 将空闲的p加入空闲链表
到目前为止,创建了m0,g0,和nprocs个P,但是还是没有让调度真正的跑起来
func procresize(nprocs int32) *p {
old := gomaxprocs
if old < 0 || nprocs <= 0 {
throw("procresize: invalid arg")
}
if trace.enabled {
traceGomaxprocs(nprocs)
}
// update statistics
now := nanotime()
if sched.procresizetime != 0 {
sched.totaltime += int64(old) * (now - sched.procresizetime)
}
sched.procresizetime = now
if nprocs > int32(len(allp)) { // 初始化的len(allp) == 0
lock(&allpLock)
if nprocs <= int32(cap(allp)) { // 需要缩容
allp = allp[:nprocs]
} else { // 扩容
nallp := make([]*p, nprocs)
// Copy everything up to allp's cap so we
// never lose old allocated Ps.
copy(nallp, allp[:cap(allp)])
allp = nallp
}
unlock(&allpLock)
}
for i := old; i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)
}
pp.init(i)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}
_g_ := getg() // 获取g0
if _g_.m.p != 0 && _g_.m.p.ptr().id < nprocs { // 进程初始化时g0.m与p没有绑定,所以g0.m.p == 0
_g_.m.p.ptr().status = _Prunning
_g_.m.p.ptr().mcache.prepareForSweep()
} else {
if _g_.m.p != 0 {
if trace.enabled {
traceGoSched()
traceProcStop(_g_.m.p.ptr())
}
_g_.m.p.ptr().m = 0
}
_g_.m.p = 0
_g_.m.mcache = nil
p := allp[0]
p.m = 0
p.status = _Pidle
acquirep(p) // 把allp[0]和m0关联起来
if trace.enabled {
traceGoStart()
}
}
// 如果有需要销毁的p,就是销毁
for i := nprocs; i < old; i++ {
p := allp[i]
p.destroy()
// can't free P itself because it can be referenced by an M in syscall
}
if int32(len(allp)) != nprocs {
lock(&allpLock)
allp = allp[:nprocs]
unlock(&allpLock)
}
// 将空闲p放入空闲链表
var runnablePs *p
for i := nprocs - 1; i >= 0; i-- {
p := allp[i]
if _g_.m.p.ptr() == p { // allp[0]已经和m0关联了,所以不用放入空闲链表
continue
}
p.status = _Pidle
if runqempty(p) {
pidleput(p)
} else {
p.m.set(mget())
p.link.set(runnablePs)
runnablePs = p
}
}
stealOrder.reset(uint32(nprocs))
var int32p *int32 = &gomaxprocs // make compiler check that gomaxprocs is an int32
atomic.Store((*uint32)(unsafe.Pointer(int32p)), uint32(nprocs))
return runnablePs
}
创建"第一个"goroutine
我们返回runtime·rt0_go接着看
- 将runtime.main地址放入AX
- 参数AX, 0入栈(函数参数入栈由右向左)
- 然后调用runtime.newproc创建goroutine
// create a new goroutine to start program
// 创建第一个goroutine执行runtime.main,源码里没搜到runtime.mainPC,在schedinit函数前注释里找到的runtime.mainPC就是runtime.main
MOVQ $runtime·mainPC(SB), AX // entry AX = func(runtime.main)
PUSHQ AX
PUSHQ $0 // arg size runtime.main没有参数所以入栈0
CALL runtime·newproc(SB) // 创建goroutine执行runtime.main(还没执行,只是将goroutine加入待运行队列)
POPQ AX // 出栈
POPQ AX // 出栈
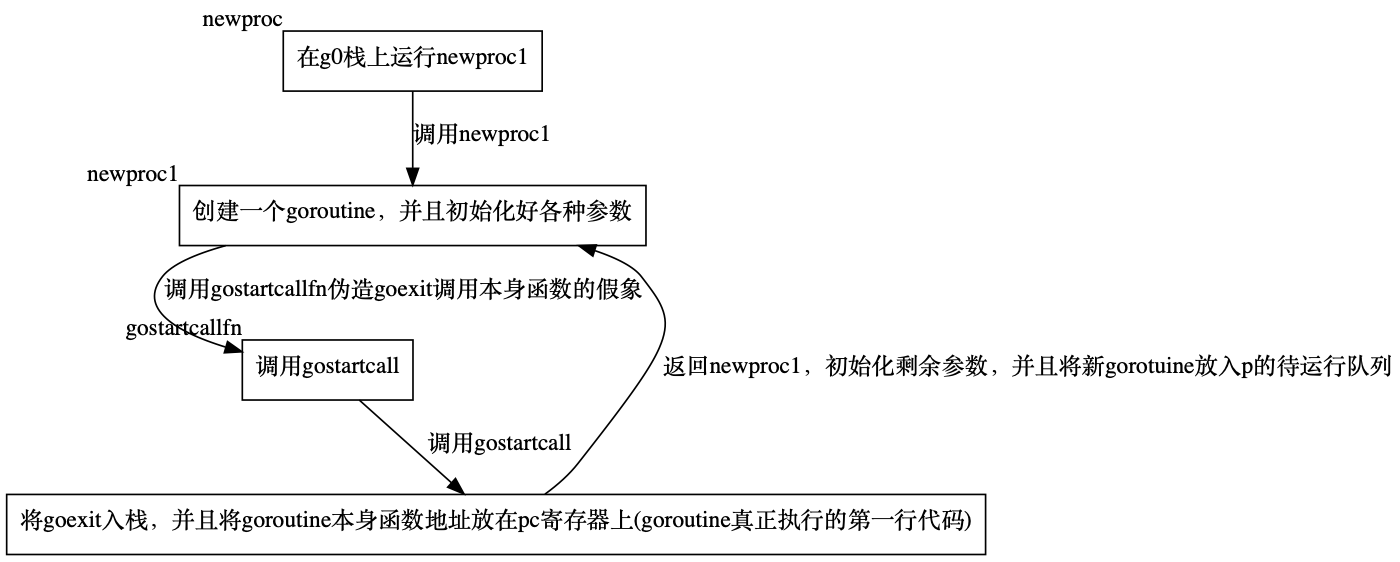
newproc
- 首先获取参数地址
- 获取当前所在goroutine(初始化时runtime代码都在g0执行)
- 获取要执行指令地址
- 在gp的栈上执行runtime.newproc1(在g0栈上执行)
func newproc(siz int32, fn *funcval) {
// 获取函数fn的第一个参数的位置
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
// 获取当前所有goroutine ---- g0
gp := getg()
// 获取要执行指令的位置
pc := getcallerpc()
/*
systemstack是将函数切换到g0的栈上运行,初始化时本来就在g0的栈上,所以直接调用函数返回
*/
systemstack(func() {
newproc1(fn, (*uint8)(argp), siz, gp, pc)
})
}
newproc1函数主要的工作
这个函数有点长分段来看
- 首先获得当前所在goroutine(g0)
- 禁止抢占
- 计算参数位置
- 计算下参数是否过大
- 获取当前goroutine所在m的p,前边讲过g0对应的m是m0,m0对应的p是allp[0]
- 创建一个goroutine(先从p的缓存里找,找不到就new一个),并且确认goroutine栈边界是初始化好的(方式p缓存里的goroutine参数没初始化)
- 计算栈顶的地址,如果有参数就将参数放到新创建的这个goroutine上
func newproc1(fn *funcval, argp *uint8, narg int32, callergp *g, callerpc uintptr) {
// 获取当前所在goroutine,初始化的是g0
_g_ := getg()
if fn == nil {
_g_.m.throwing = -1 // do not dump full stacks
throw("go of nil func value")
}
// 禁止抢占,把p固定在本地变量
acquirem() // disable preemption because it can be holding p in a local var
siz := narg
siz = (siz + 7) &^ 7
// 检查一下参数是否需要空间是否过大,参数大小 和 栈大小 - (额外栈底空间(猜的)) - 返回需要的栈大小
if siz >= _StackMin-4*sys.RegSize-sys.RegSize {
throw("newproc: function arguments too large for new goroutine")
}
// _p_ = allp[0]
_p_ := _g_.m.p.ptr()
// 从_p_的缓存中取一个g,初始化的时候没有可用的g所以newg==nil
newg := gfget(_p_)
if newg == nil {
// 创建一个新g,栈空间2k, 并且给stack,stackguard0,stackguard1初始化
newg = malg(_StackMin)
// 将g的状态设置为_Gdead
casgstatus(newg, _Gidle, _Gdead)
// 将g加入allg链表
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}
// 确认刚才的初始化是否有效
if newg.stack.hi == 0 {
throw("newproc1: newg missing stack")
}
if readgstatus(newg) != _Gdead {
throw("newproc1: new g is not Gdead")
}
// 省略一段调整sp指针的函数,并且如果有参数就将参数放入new goroutine的栈中
...
设置各个寄存器的值(在cpu上恢复上下文时使用)
1) 清理sched
2) 设置栈顶置针位置
3) 设置pc寄存器值(goexit函数第二条指令,常理应该是goroutine本身函数的第一条指令,这个妙用后边说)
4) 设置goroutine地址
5) 调用gostartcallfn,参数是sched和goroutine的参数
// 清理sched(各参数清零)
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
// 设置sched, 在CPU上运行的相关参数
newg.sched.sp = sp
newg.stktopsp = sp
// 设置pc,被调度时第一条指令的位置,将pc设置为goexit函数一个偏移量的位置(goexit函数第二条指令)
// 这里把pc设置为goexit函数的第二条指令的作用就是,伪装成goexit函数调用的fn函数,当fn执行完跳回goexit函数继续做退出需要的操作
newg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
判断一下goroutine的函数是否为空,然后调用gostartcall
func gostartcallfn(gobuf *gobuf, fv *funcval) {
var fn unsafe.Pointer
if fv != nil {
fn = unsafe.Pointer(fv.fn)
} else {
fn = unsafe.Pointer(funcPC(nilfunc))
}
gostartcall(gobuf, fn, unsafe.Pointer(fv))
}
- 获取sp,现在新goroutine的栈上之后本身的函数,sp指向函数的第一个参数
- 将sp指向pc里面的指令地址,也就是goexit的第二条指令,然后重新设置新goroutinesp地址
- 这时候pc才指向goroutine自己的函数
gostartcall的主要作用就是将goexit入栈,然后设置goroutine的pc指向自身函数,伪装成是goexit调用的自身函数,当自身函数执行完时返回goexit清理线程,大概就是下面这样
func goexit() {
goroutine自身函数()
清理现场()
}
func gostartcall(buf *gobuf, fn, ctxt unsafe.Pointer) {
sp := buf.sp
if sys.RegSize > sys.PtrSize {
sp -= sys.PtrSize
*(*uintptr)(unsafe.Pointer(sp)) = 0
}
// 预留返回值空间
sp -= sys.PtrSize
// sp指向pc指令的位置,前边已经将goexit第二条指令的地址放入pc
*(*uintptr)(unsafe.Pointer(sp)) = buf.pc
// 然后设置sp
buf.sp = sp
// 这时候的pc才是goroutine的函数
buf.pc = uintptr(fn)
buf.ctxt = ctxt
}
然后再回到newproc函数,剩下的就是设置goroutine的状态,然后把goroutine放入p的待执行队列中
newg.gopc = callerpc // 用于traceback
newg.ancestors = saveAncestors(callergp)
// newg的函数从哪里开始执行依赖于sched.pc 不依赖于startpc
newg.startpc = fn.fn
if _g_.m.curg != nil {
newg.labels = _g_.m.curg.labels
}
if isSystemGoroutine(newg, false) {
atomic.Xadd(&sched.ngsys, +1)
}
newg.gcscanvalid = false
// 设置newg状态为_Grunnable, 到这里newg就可以运行了
casgstatus(newg, _Gdead, _Grunnable)
if _p_.goidcache == _p_.goidcacheend {
_p_.goidcache = atomic.Xadd64(&sched.goidgen, _GoidCacheBatch)
_p_.goidcache -= _GoidCacheBatch - 1
_p_.goidcacheend = _p_.goidcache + _GoidCacheBatch
}
newg.goid = int64(_p_.goidcache)
_p_.goidcache++
if raceenabled {
newg.racectx = racegostart(callerpc)
}
if trace.enabled {
traceGoCreate(newg, newg.startpc)
}
// 将newg加入p的待运行队列
runqput(_p_, newg, true)
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 && mainStarted {
wakep()
}
// 取消m的固定
releasem(_g_.m)
}
总结一下创建第一个goroutine执行runtime.main的过程(只是创建啊,整个调度这时候还是没有跑起来)
调度循环
我们再返回runtime·rt0_go继续看,总结一下到目前为止已经准备好的事情
- 将m0与主线程绑定了(将m0结构体设为主线程的私有变量)
- 创建了g0,并且与m0绑定
- 创建了procs个p并且初始化,将allp[0]与m0绑定,形成初步的GMP模型(g0,m0,p0)
- 创建了一个执行runtime.main(不是代码里的main.main,runtime.main会做加载init函数等操作然后调用main.main)的goroutine并且放入了p0的待运行队列
接下来就是调度循环了,调用runtime.mstart,这个函数就是调度循环,除非程序退出否则永远阻塞住
// start this M
// 运行runtime.mstart这个函数会阻塞住,运行结束的时候就是程序退出的时候
CALL runtime·mstart(SB)
CALL runtime·abort(SB) // mstart should never return
RET
// Prevent dead-code elimination of debugCallV1, which is
// intended to be called by debuggers.
MOVQ $runtime·debugCallV1(SB), AX
RET
runtime.mstart
- 获取了当前所在goroutine(初始化时代码都是在g0上执行的)
- 初始化栈保护
- 调用mstart1
go/src/runtime/proc.go, line 1146
func mstart() {
_g_ := getg() // 获取g0
osStack := _g_.stack.lo == 0 // g0.stack.lo在前边已经初始化过了,所以osStack = false
if osStack {
size := _g_.stack.hi
if size == 0 {
size = 8192 * sys.StackGuardMultiplier
}
_g_.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))
_g_.stack.lo = _g_.stack.hi - size + 1024
}
// 初始化栈保护
_g_.stackguard0 = _g_.stack.lo + _StackGuard
_g_.stackguard1 = _g_.stackguard0
// 开始m0开始运行
mstart1()
// Exit this thread.
if GOOS == "windows" || GOOS == "solaris" || GOOS == "illumos" || GOOS == "plan9" || GOOS == "darwin" || GOOS == "aix" {
osStack = true
}
mexit(osStack)
}
runtime.mstart1
- 保存g0的指令指针和栈指针,保存这两个值是理解调度循环的关键,mstart1执行完之后,g0继续执行指令,不会再返回来了,保存了指令和栈指针之后,g0要继续执行指令的时候,就会又从上面开始执行
- 做一些初始化工作
- 调用schedule开始调度
func mstart1() {
// 获取当前goroutine g0
_g_ := getg()
if _g_ != _g_.m.g0 {
throw("bad runtime·mstart")
}
// save函数保存了g0再次运行时(循环调度下一次回头)调度相关信息
save(getcallerpc(), getcallersp())
// asminit
asminit()
// 信号相关初始化
minit()
// 初始化时m == m0,mstartm0也是信号相关的初始化
if _g_.m == &m0 {
mstartm0()
}
// 初始化时fn == ni
if fn := _g_.m.mstartfn; fn != nil {
fn()
}
if _g_.m != &m0 {
acquirep(_g_.m.nextp.ptr())
_g_.m.nextp = 0
}
// 开始调度
schedule()
}
runtime.schedule
调度开始了,m要找gorutine放到cpu上执行了
- 每调度61次(具体为啥是61有待思考),就从全局的goroutine列表中选goroutine
- 如果上一步没找到,就从m对应的p的缓存里找
- 如果上一步还没有找到,就调findrunnable从其他线程窃取goroutine,如果发现有就窃取一半放到自己的p缓存中,如果都没有就说明真的没有待运行的goroutine了,就陷入睡眠一直阻塞在findrunnable函数,等待被唤醒
- 直到有goroutine需要执行了,就调用execute执行goroutine
func schedule() {
// 获得g0
_g_ := getg()
if _g_.m.locks != 0 {
throw("schedule: holding locks")
}
if _g_.m.lockedg != 0 {
stoplockedm()
execute(_g_.m.lockedg.ptr(), false) // Never returns.
}
if _g_.m.incgo {
throw("schedule: in cgo")
}
top:
// 等待gc
if sched.gcwaiting != 0 {
gcstopm()
goto top
}
if _g_.m.p.ptr().runSafePointFn != 0 {
runSafePointFn()
}
var gp *g
var inheritTime bool
tryWakeP := false
if trace.enabled || trace.shutdown {
gp = traceReader()
if gp != nil {
casgstatus(gp, _Gwaiting, _Grunnable)
traceGoUnpark(gp, 0)
tryWakeP = true
}
}
if gp == nil && gcBlackenEnabled != 0 {
gp = gcController.findRunnableGCWorker(_g_.m.p.ptr())
tryWakeP = tryWakeP || gp != nil
}
// 先从全局队列中获取,每61次调度都会从全局队列中获取goroutine
if gp == nil {
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
// 如果还空就从本地队列中获取
if gp == nil {
gp, inheritTime = runqget(_g_.m.p.ptr())
if gp != nil && _g_.m.spinning {
throw("schedule: spinning with local work")
}
}
// 如果本地也没有就调用findrunnable从其他线程偷一个过来,直到偷过来在运行
if gp == nil {
gp, inheritTime = findrunnable() // blocks until work is available
}
if _g_.m.spinning {
resetspinning()
}
if sched.disable.user && !schedEnabled(gp) {
lock(&sched.lock)
if schedEnabled(gp) {
unlock(&sched.lock)
} else {
sched.disable.runnable.pushBack(gp)
sched.disable.n++
unlock(&sched.lock)
goto top
}
}
if tryWakeP {
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 {
wakep()
}
}
if gp.lockedm != 0 {
startlockedm(gp)
goto top
}
// 执行这个goroutine
execute(gp, inheritTime)
}
触发调度
触发调度地方大致有:
- 主动挂起
- 系统调用
- 协作式调度
- 正常退出
- proc.go:1208 runtime.mstart1(调度开始)
主动挂起
- proc.go:2610 runtime.park_m
在上一章内容里讲过golang channel源码阅读,当goroutine接收一个channel为空且为阻塞的时候,goroutine会调用goparkunlock使goroutine陷入睡眠,等待send端调用goready函数唤醒函数,主动挂起就是这种情况,当goroutine由于某些条件在等待时,就会主动挂起,不放回待运行队列,等待被唤醒
各种阻塞条件 -> runtime.gopark() -> runtime.park_m() -> runtime.schedule
- 获取当前所在m,并且固定m
- 获取当前程序所在goroutine
- 设置锁状态以及阻塞原因
- 调用runtime.park_m挂起goroutine
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceEv byte, traceskip int) {
if reason != waitReasonSleep {
checkTimeouts() // timeouts may expire while two goroutines keep the scheduler busy
}
mp := acquirem()
gp := mp.curg
status := readgstatus(gp)
if status != _Grunning && status != _Gscanrunning {
throw("gopark: bad g status")
}
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waittraceev = traceEv
mp.waittraceskip = traceskip
releasem(mp)
// can't do anything that might move the G between Ms here.
mcall(park_m)
}
- 获取当前goroutine
- 将goroutine状态设置为Gwaiting
- 重新调度
func park_m(gp *g) {
_g_ := getg()
if trace.enabled {
traceGoPark(_g_.m.waittraceev, _g_.m.waittraceskip)
}
casgstatus(gp, _Grunning, _Gwaiting)
dropg()
if fn := _g_.m.waitunlockf; fn != nil {
ok := fn(gp, _g_.m.waitlock)
_g_.m.waitunlockf = nil
_g_.m.waitlock = nil
if !ok {
if trace.enabled {
traceGoUnpark(gp, 2)
}
casgstatus(gp, _Gwaiting, _Grunnable)
execute(gp, true) // Schedule it back, never returns.
}
}
schedule()
}
协作式调度
- proc.go:2625 runtime.goschedImpl(协作式调度)
- 主动让出cpu,这个情况不会挂起goroutine,而是放回队列,等待下次调度,这个函数(GoSched)被暴露出去,可以调用,例如,线上有这种情况,写log是异步的,但由于机器磁盘老旧性能不佳,所以当log goroutine运行时还是会过多的占用cpu,这时候可以调用GoSched适当降低当前goroutine优先级
runtime.Gosched -> runtime.gosched_m -> runtime.goschedImpl runtime.schedule
// Gosched continuation on g0.
func gosched_m(gp *g) {
if trace.enabled {
traceGoSched()
}
goschedImpl(gp)
}
- 调度保护,当调度器发现goroutine处于禁止的状态时就会主动调度让出cpu
// goschedguarded is a forbidden-states-avoided version of gosched_m
func goschedguarded_m(gp *g) {
if gp.m.locks != 0 || gp.m.mallocing != 0 || gp.m.preemptoff != "" || gp.m.p.ptr().status != _Prunning {
gogo(&gp.sched) // never return
}
if trace.enabled {
traceGoSched()
}
goschedImpl(gp)
}
- 发生抢占,例如当一个goroutine运行时间过长但不像等待channel那样阻塞,一直有事情做时,其他goroutine可能会抢占cpu
func gopreempt_m(gp *g) {
if trace.enabled {
traceGoPreempt()
}
goschedImpl(gp)
}
func goschedImpl(gp *g) {
status := readgstatus(gp)
if status&^_Gscan != _Grunning {
dumpgstatus(gp)
throw("bad g status")
}
casgstatus(gp, _Grunning, _Grunnable)
dropg()
lock(&sched.lock)
globrunqput(gp)
unlock(&sched.lock)
schedule()
}
非main goroutine结束
- proc.go:2704,2727 runtime.goexit0(goroutine正常执行完)
非main goroutine结束后会继续调度,这个是正常继续下一次调度不做过多介绍
系统调用
- proc.go:3141 runtime.exitsyscall0(系统调用)
runtime·exitsyscall -> runtime·exitsyscall0 -> runtime.schedule
我们来看下系统调用的过程
func syscall_syscall(fn, a1, a2, a3 uintptr) (r1, r2, err uintptr) {
entersyscall()
libcCall(unsafe.Pointer(funcPC(syscall)), unsafe.Pointer(&fn))
exitsyscall()
return
}
func syscall()
首先会调用runtime.entersyscall获取当前的指令位置和栈指针,然后调用reentersyscall做goroutine进入系统调用之前的准备
func entersyscall() {
reentersyscall(getcallerpc(), getcallersp())
}
- 禁止线程抢占防止出现栈不一致的情况
- 保证当前函数不会触发栈调整(golang进程的栈初始2k,然后动态调整)
- 设置goroutine状态为Gsyscall
- 将goroutine的P暂时和M分离,并且设置P状态为Psyscall
- 释放锁
func reentersyscall(pc, sp uintptr) {
// 获得当前goroutine
_g_ := getg()
_g_.m.locks++
_g_.stackguard0 = stackPreempt
_g_.throwsplit = true
// Leave SP around for GC and traceback.
save(pc, sp)
_g_.syscallsp = sp
_g_.syscallpc = pc
casgstatus(_g_, _Grunning, _Gsyscall)
if _g_.syscallsp < _g_.stack.lo || _g_.stack.hi < _g_.syscallsp {
systemstack(func() {
print("entersyscall inconsistent ", hex(_g_.syscallsp), " [", hex(_g_.stack.lo), ",", hex(_g_.stack.hi), "]
")
throw("entersyscall")
})
}
if trace.enabled {
systemstack(traceGoSysCall)
save(pc, sp)
}
if atomic.Load(&sched.sysmonwait) != 0 {
systemstack(entersyscall_sysmon)
save(pc, sp)
}
if _g_.m.p.ptr().runSafePointFn != 0 {
systemstack(runSafePointFn)
save(pc, sp)
}
_g_.m.syscalltick = _g_.m.p.ptr().syscalltick
_g_.sysblocktraced = true
_g_.m.mcache = nil
pp := _g_.m.p.ptr()
pp.m = 0
_g_.m.oldp.set(pp)
_g_.m.p = 0
atomic.Store(&pp.status, _Psyscall)
if sched.gcwaiting != 0 {
systemstack(entersyscall_gcwait)
save(pc, sp)
}
_g_.m.locks--
}
然后就进入系统调用
...
- 获得goroutine
- 线程加锁
- 调exitsyscallfast替当前goroutine找一个P
- 如果原P处于Psyscall就让这个P接管,否则的话进行2)
- 否则的话就找空闲的P,有的话就调用exitsyscall0继续调度,否则的话进行3)
- 将goroutine设置为Grunning,加入全局队列,调用Gosched()继续调度
func exitsyscall() {
_g_ := getg()
_g_.m.locks++ // see comment in entersyscall
if getcallersp() > _g_.syscallsp {
throw("exitsyscall: syscall frame is no longer valid")
}
_g_.waitsince = 0
oldp := _g_.m.oldp.ptr()
_g_.m.oldp = 0
if exitsyscallfast(oldp) {
if _g_.m.mcache == nil {
throw("lost mcache")
}
if trace.enabled {
if oldp != _g_.m.p.ptr() || _g_.m.syscalltick != _g_.m.p.ptr().syscalltick {
systemstack(traceGoStart)
}
}
// There's a cpu for us, so we can run.
_g_.m.p.ptr().syscalltick++
// We need to cas the status and scan before resuming...
casgstatus(_g_, _Gsyscall, _Grunning)
// Garbage collector isn't running (since we are),
// so okay to clear syscallsp.
_g_.syscallsp = 0
_g_.m.locks--
if _g_.preempt {
// restore the preemption request in case we've cleared it in newstack
_g_.stackguard0 = stackPreempt
} else {
// otherwise restore the real _StackGuard, we've spoiled it in entersyscall/entersyscallblock
_g_.stackguard0 = _g_.stack.lo + _StackGuard
}
_g_.throwsplit = false
if sched.disable.user && !schedEnabled(_g_) {
// Scheduling of this goroutine is disabled.
Gosched()
}
return
}
_g_.sysexitticks = 0
if trace.enabled {
// Wait till traceGoSysBlock event is emitted.
// This ensures consistency of the trace (the goroutine is started after it is blocked).
for oldp != nil && oldp.syscalltick == _g_.m.syscalltick {
osyield()
}
// We can't trace syscall exit right now because we don't have a P.
// Tracing code can invoke write barriers that cannot run without a P.
// So instead we remember the syscall exit time and emit the event
// in execute when we have a P.
_g_.sysexitticks = cputicks()
}
_g_.m.locks--
// Call the scheduler.
mcall(exitsyscall0)
if _g_.m.mcache == nil {
throw("lost mcache")
}
// Scheduler returned, so we're allowed to run now.
// Delete the syscallsp information that we left for
// the garbage collector during the system call.
// Must wait until now because until gosched returns
// we don't know for sure that the garbage collector
// is not running.
_g_.syscallsp = 0
_g_.m.p.ptr().syscalltick++
_g_.throwsplit = false
}