写在前面
本来觉得已经学习了Mysql和微软家的SqlServer后,再学习Oracle属实没有必要。但考虑到自己这学期刚刚学习完了数据库原理这门课,我就借此机会对比一下我现在学习的几个数据库之间的区别,体会一下Mysql和Oracle之间的具体差别,事实上我一直以为Oracle凉了,但使用率上看还是稳居高位: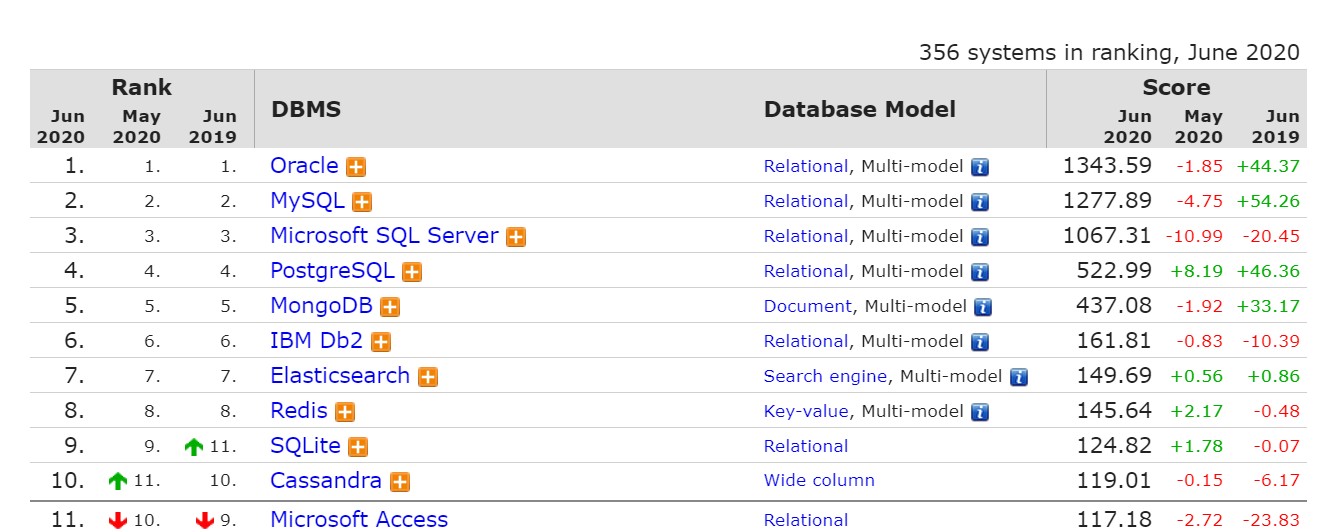 因此我觉得还是有必要学习一下Oracle的。
因此我觉得还是有必要学习一下Oracle的。
配置和连接Oracle
考虑到Oracle是收费的数据库,且安装较为复杂,这里使用了xp的虚拟机来安装数据库,作为远程数据库(即效仿以后工作时的场景)关于虚拟机的具体配置和操作这里就不再赘述了,主要讲一下如何连接到Oracle数据库。我们作为java程序员,一般都会使用专门的图形化数据库管理工具。这里我们使用Plsql(一个专门用于管理oracle的DBMS)来连接。打开Plsql,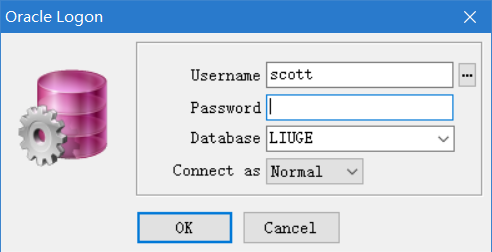
在这里输入用户名和密码即可。密码是我们自己设置的,而oracle自带了许多的用户名,这里我们使用scott,里面自带了一些表,方便一会我们使用他进行查询操作的练习。
oracle数据库的基本操作单位
相比较于mysql以表为单位,oracle以用户为单位,用户拥有表,登录用户后可以查看到表。而mysql里表属于数据库,这里就有着很大的差别。如下图为oracle的操作结构:

oracle数据库的表空间和用户操作
首先来看oracle数据库独有的操作,创建一个表空间,然后创建用户,授予权限等:
--创建表空间
create tablespace liuge
datafile 'c:liuge.dbf'
size 100m
autoextend on
next 10m;
-- 删除表空间
drop tablespace liuge;
-- 创建用户
create user liuge
identified by abc456
default tablespace liuge;
-- 给用户授权
-- oracle数据库中常用角色
connect --连接角色(基本角色)
resource --开发者角色
dba -- 超级管理员角色
-- 给liuge用户授予dba角色
grant dba to liuge;
-- 切换到liuge用户下
可以看到,这些操作比起mysql来说要更加细化,这一点在SqlServer上也是同理,可以拥有多个用户和角色,管理十分的细致。
oracle里的数据类型
我们直接看图:

图里列出了几个常用的数据类型,第一个varchar和varchar2,十分熟悉了,可变长度字符串。varchar不管是SqlServer,mysql还是oracle都是通用的(即标准sql提供的)。在oracle里我们一般用varchar2(oracle特有的)。
第二个为number,即数字类型,分为整数型和小数型。但整数型也可以接受小数型,因此我们一般用整数型。
第三个为data,即oracle里的日期类型。对标mysql里的datetime,2020-06-19 20:09:48 可显示这样的日期。
第四个第五个就比较少用了,主要用于存储大文件。
oracle里的修改表结构操作
--- 修改表结构
--- 添加一列
alter table person add (gender number(1));
-- 修改列类型
alter table person modify gender char(1);
-- 修改列名称
alter table person rename column gender to sex;
直接看sql语句,我们会发现基本类似于标准sql操作。没什么可说的。
删表操作
关于删除操作,我们看如下三个:
-- 三个删除
-- 删除表中全部记录
delete from person;
-- 删除表结构
drop table person;
-- 先删除表,再次创建表。效果等同于删除表中全部记录
-- 在数据量大的情况下,尤其在表中带有索引的情况下,该操作效率高。
-- 索引可以提高查询效率,但是会影响增删改效率。
truncate table person;
可以看到,truncate和delete类似,这个关键字我在mysql里为了重置主键的时候用过,仔细细究的话肯定有许多差别,这里就不再细究了。
序列
-- 序列不真的属于任何一张表,逻辑上与表绑定。
-- 序列:默认从1开始,依次递增,主要用来给主键赋值使用。
-- dual:虚表,只为了补全语法,没有任何意义。
create sequence s_person;
select s_person.nextval from dual;
-- 添加一条记录
insert into person (pid,pname) values(s_person.nextval,'武神酱');
commit;
select * from person
序列应该是oracle里特有的了,主要用于生成主键,这点mysql里可以设成自动递增,但oracle要更为灵活。
oracle里的函数
单行函数
-- 字符函数
select upper('yes')from dual;
select lower('YES')from dual;
-- 数值函数
select round(26.18,-1) from dual; -- 四舍五入,后面的参数表示保留的位数。
select trunc(56.16,1) from dual;-- 直接截取,不再四舍五入。
select mod(10,3) from dual; -- 求余数
-- 日期函数
-- 查询出emp表中所有员工入职距离现在几天
select sysdate-e.hiredate from emp e;
-- 算出明天此刻
select sysdate+1 from dual;
-- 查询出emp表中所有员工入职距离现在几月
select months_between(sysdate,e.hiredate) from emp e;
-- 查询出emp表中所有员工入职距离现在几年
select months_between(sysdate,e.hiredate)/12 from emp e;
-- 查询出emp表中所有员工入职距离现在几周
select round((sysdate-e.hiredate)/7) from emp e;
-- 转换函数
-- 日期转字符串
select to_char(sysdate,'fm yyyy-mm-dd hh24:mi:ss')from dual;
-- 字符串转日期
select to_date(' 2020-6-19 18:10:21','fm yyyy-mm-dd hh24:mi:ss')from dual;
-- 通用函数
-- 算出emp表中所有员工的年薪
-- 奖金里有null值,null值和任意数值做算数运算结果都是null
select e.sal*12+nvl(e.comm,0) from emp e;
-- 条件表达式
-- 条件表达式的通用写法,mysql和oracle通用
-- 给emp表中员工起中文名
select e.ename,
case e.ename
when 'SMITH' then '武神'
when 'ALLEN' then '大耳贼'
when 'WARD' then '诸葛小儿'
-- else '无名'
end
from emp e;
-- 判断emp表中员工工资,如果高于3000显示高收入,如果高于1500低于3000显示中等收入,其余显示低收入
select e.sal,
case
when e.sal>3000 then '高收入'
when e.sal>1500 then '中等收入'
else '低收入'
end
from emp e;
-- oracle 除了起别名,都用单引号
-- oracle专用条件表达式
select e.ename,
decode(e.ename,
'SMITH' ,'武神',
'ALLEN' , '大耳贼',
'WARD' , '诸葛小儿',
'无名') "中文名"
from emp e;
可以看到函数有很多,都在注释里写清楚了,直接看sql语句吧。
多行函数
其实无外乎就是max,min,avg,count,sum这几个常用的函数,这几个mysql和SqlServer里也有,就不再细说了。
select count(1) from emp; -- 查询总数量
select sum(sal) from emp; -- 工资总和
select max(sal) from emp; -- 最大工资
select min(sal) from emp; -- 最低工资
select avg(sal) from emp; -- 平均工资
分组查询
这里的分组查询和mysql有着很大的差别。比如同一个sql语句:
select * from emp group by e.deptno;
这个语句在oracle里是无法执行的:
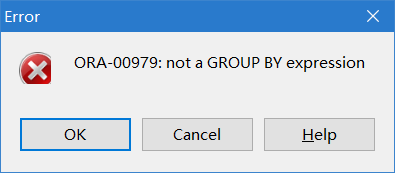
但是放到mysql里:

(这里使用的不是一个表,但也可以看出问题)
也就是说,oracle里的分组查询相当于是新建了一个表,如果不选择显示的列的话,是无法显示数据的。一般我们配合聚合函数来使用(即多行函数)
-- 查询出平均工资高于2000的部门信息
select
e.deptno,avg(e.sal) asal
from emp e
group by e.deptno
having avg(e.sal)>2000;
只要是having或者group by后面出现的我们都可以在select后使用。
其他的关于having和where的差别什么的,之前一直在说,这里就不提了
多表查询
这方面就简单说一个等值连接吧:
-- 多表查询中的概念
-- 笛卡尔积
select *
from emp e,dept d;
-- 等值连接
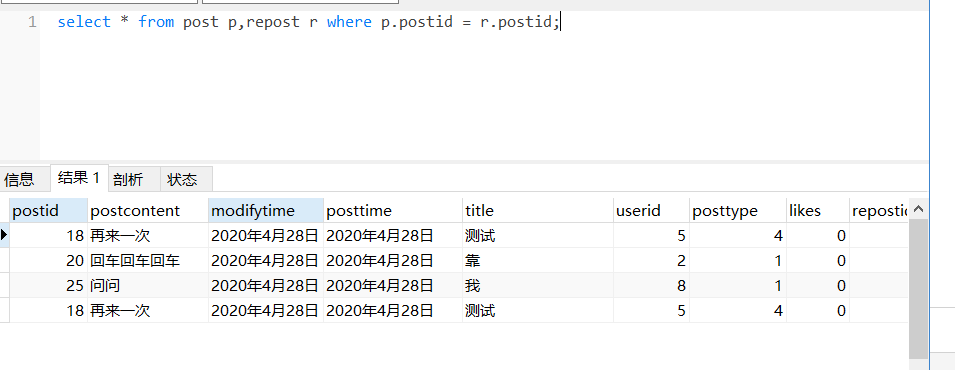
select *
from emp e,dept d
where e.deptno = d.deptno;
这种连接方法其实就是内连接,不过这种写法要更简便些。在mysql中使用这种写法,也是可行的:
oracle中的分页操作
记得我们在mysql中分页时,使用的是limit关键字,但在oracle我们有不同的方法:
-- oracle中的分页
-- rownum 行号:当我们做select操作的时候,每查询出一行记录,就会在该行加上一个行号
-- 行号从1开始,依次递增。
-- emp表工资倒序排列后,每页五条记录,查询第二页。
-- 排序操作会影响rownum的顺序
select rownum,e.* from emp e order by e.sal desc;
-- 如果涉及到排序,但还要使用rownum,我们可以再次嵌套查询
select rownum,t.* from(
select rownum,e.* from emp e order by e.sal desc) t;
-- emp表工资倒序排列后,每页五条记录,查询第二页
-- rownum行号不能写上大于一个正数
select * from(
select rownum rn,e.* from (
select * from emp order by sal desc
)e where rownum < 11
) where rn > 5
这里主要用到了rownum这一个oracle特有的关键字,含义为行号,关于行号的讲解这里推荐这篇文章:
oracle中关于行号的讲解
总结
总的来说,oracle具有很多特殊的地方,在学习完oracle后会尝试使用oracle开发一个简单的项目来同时测试SSM和oracle。